
Forwarded from Denis Sexy IT 🤖
Media is too big
VIEW IN TELEGRAM
Мы все ближе к генеративной сингулярности:
Nvidia показала работу алгоритма text2video, и он работает сильно лучше чем все предыдущие примеры.
Смонтировал примеры в одно видео, тут по ссылке технические детали про архитектуру и больше примеров.
Модель, поиграться, кажется, нам не дадут🥲
Nvidia показала работу алгоритма text2video, и он работает сильно лучше чем все предыдущие примеры.
Смонтировал примеры в одно видео, тут по ссылке технические детали про архитектуру и больше примеров.
Модель, поиграться, кажется, нам не дадут
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥5
Forwarded from gonzo-обзоры ML статей
Looks interesting
https://github.com/google/maxtext
MaxText is a high performance, arbitrarily scalable, open-source, simple, easily forkable, well-tested, batteries included LLM written in pure Python/Jax and targeting Google Cloud TPUs. MaxText typically achieves 55% to 60% model-flop utilization and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler.
MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.
...
MaxText is heavily inspired by MinGPT/NanoGPT, elegant standalone GPT implementations written in PyTorch and targeting Nvidia GPUs. MaxText is more complex but has an MFU more than three times the 17% reported most recently with that codebase, is massively scalable and implements a key-value cache for efficient auto-regressive decoding.
MaxText is more similar to Nvidia/Megatron-LM, a very well tuned LLM implementation targeting Nvidia GPUs. The two implementations achieve comparable MFUs. The difference in the codebases highlights the different programming strategies. MaxText is pure Python, relying heavily on the XLA compiler to achieve high performance. By contrast, Megatron-LM is a mix of Python and CUDA, relying on well-optimized CUDA kernels to achieve high performance.
MaxText is also comparable to Pax. Like Pax, MaxText provides high-performance and scalable implementations of LLMs in Jax. Pax focuses on enabling powerful configuration parameters, enabling developers to change the model by editing config parameters. By contrast, MaxText is a simple, concrete implementation of an LLM that encourages users to extend by forking and directly editing the source code. The right choice depends on your project's priorities.
https://github.com/google/maxtext
MaxText is a high performance, arbitrarily scalable, open-source, simple, easily forkable, well-tested, batteries included LLM written in pure Python/Jax and targeting Google Cloud TPUs. MaxText typically achieves 55% to 60% model-flop utilization and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler.
MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.
...
MaxText is heavily inspired by MinGPT/NanoGPT, elegant standalone GPT implementations written in PyTorch and targeting Nvidia GPUs. MaxText is more complex but has an MFU more than three times the 17% reported most recently with that codebase, is massively scalable and implements a key-value cache for efficient auto-regressive decoding.
MaxText is more similar to Nvidia/Megatron-LM, a very well tuned LLM implementation targeting Nvidia GPUs. The two implementations achieve comparable MFUs. The difference in the codebases highlights the different programming strategies. MaxText is pure Python, relying heavily on the XLA compiler to achieve high performance. By contrast, Megatron-LM is a mix of Python and CUDA, relying on well-optimized CUDA kernels to achieve high performance.
MaxText is also comparable to Pax. Like Pax, MaxText provides high-performance and scalable implementations of LLMs in Jax. Pax focuses on enabling powerful configuration parameters, enabling developers to change the model by editing config parameters. By contrast, MaxText is a simple, concrete implementation of an LLM that encourages users to extend by forking and directly editing the source code. The right choice depends on your project's priorities.
GitHub
GitHub - AI-Hypercomputer/maxtext: A simple, performant and scalable Jax LLM!
A simple, performant and scalable Jax LLM! Contribute to AI-Hypercomputer/maxtext development by creating an account on GitHub.
Forwarded from Machinelearning
LLM Zoo: democratizing ChatGPT
Model "Phoenix", achieving competitive performance among open-source English and Chinese models while excelling in languages with limited resources
LLM Zoo - это проект, который предоставляет данные, модели и бенчмарки для больших языковых моделей.
🖥 Github: https://github.com/freedomintelligence/llmzoo
⏩ Paper: https://arxiv.org/abs/2304.10453v1
⭐️ Parameters: https://huggingface.co/FreedomIntelligence/phoenix-chat-7b
ai_machinelearning_big_data
Model "Phoenix", achieving competitive performance among open-source English and Chinese models while excelling in languages with limited resources
LLM Zoo - это проект, который предоставляет данные, модели и бенчмарки для больших языковых моделей.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥2
DINOv2: современные модели компьютерного зрения с самообучением
https://ai.facebook.com/blog/dino-v2-computer-vision-self-supervised-learning/
https://github.com/facebookresearch/dinov2
https://ai.facebook.com/blog/dino-v2-computer-vision-self-supervised-learning/
https://github.com/facebookresearch/dinov2
Visual Blocks for ML: Accelerating machine learning prototyping with interactive tools
https://ai.googleblog.com/2023/04/visual-blocks-for-ml-accelerating.html?utm_source=substack&utm_medium=email
https://ai.googleblog.com/2023/04/visual-blocks-for-ml-accelerating.html?utm_source=substack&utm_medium=email
👍4
Forwarded from Machinelearning
This media is not supported in your browser
VIEW IN TELEGRAM
Track anything
Project developed upon Segment Anything, can specify anything to track and segment via user clicks only.
Track-Anything - это гибкий и интерактивный инструмент для отслеживания и сегментации видео.
🖥 Github: https://github.com/gaomingqi/track-anything
⏩ Paper: https://arxiv.org/abs/2304.11968v1
🤗 Hugging face: https://huggingface.co/spaces/watchtowerss/Track-Anything
📌 Dataset: https://paperswithcode.com/dataset/davis-2017
ai_machinelearning_big_data
Project developed upon Segment Anything, can specify anything to track and segment via user clicks only.
Track-Anything - это гибкий и интерактивный инструмент для отслеживания и сегментации видео.
🤗 Hugging face: https://huggingface.co/spaces/watchtowerss/Track-Anything
📌 Dataset: https://paperswithcode.com/dataset/davis-2017
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
👍8🔥1🥰1
Forwarded from эйай ньюз
🔥DeepFloyd IF: новая text-2-image модель
StablityAI выпустили новую модель, которая очень похожа на Imagen от Google, но работает лучше и в open-source.
Архитектура IF, как и у Imagen состоит из трех диффузионных моделей, каждая из которых работает в пространстве RGB и прогрессивно увеличивают картинку. Сначала Text→64×64, затем (Text+64×64)→256×256, и наконец (Text+256×256)→1024×1024. А текст кодируется с помощью текстового энкодера T5.
Почему это круто?
— IF неплохо умеет генерировать текст (я даже генерил в канале ранее), явно лучше чем StableDiffusion XL
— Нормальная открытая имплементация по типу Imagen, которой до сих пор не было. Возможно с какими-то трюками, о которых мы узнаем, когда авторы выпустят блогпост
— FID скор измеряет похожесть снеренированных картинок на реальные. Это чуть ли не основная метрика для качества генерации. У IF FID=6.7, тогда как у Imagen 7.3. Меньше — лучше. Разрыв не космический, но приличный.
Код выложили, веса ждем тут. И ждем подробной статьи от авторов.
@ai_newz
StablityAI выпустили новую модель, которая очень похожа на Imagen от Google, но работает лучше и в open-source.
Архитектура IF, как и у Imagen состоит из трех диффузионных моделей, каждая из которых работает в пространстве RGB и прогрессивно увеличивают картинку. Сначала Text→64×64, затем (Text+64×64)→256×256, и наконец (Text+256×256)→1024×1024. А текст кодируется с помощью текстового энкодера T5.
Почему это круто?
— IF неплохо умеет генерировать текст (я даже генерил в канале ранее), явно лучше чем StableDiffusion XL
— Нормальная открытая имплементация по типу Imagen, которой до сих пор не было. Возможно с какими-то трюками, о которых мы узнаем, когда авторы выпустят блогпост
— FID скор измеряет похожесть снеренированных картинок на реальные. Это чуть ли не основная метрика для качества генерации. У IF FID=6.7, тогда как у Imagen 7.3. Меньше — лучше. Разрыв не космический, но приличный.
Код выложили, веса ждем тут. И ждем подробной статьи от авторов.
@ai_newz
👍3👎1👏1
Forwarded from Machinelearning
🖌 Edit Everything: A Text-Guided Generative System for Images Editing
A text-guided generative system without any finetuning (zero-shot).
Edit Everything позволяет пользователям редактировать изображения с помощью простых текстовых инструкций.
🖥 Github: https://github.com/defengxie/edit_everything
⏩ Paper: https://arxiv.org/abs/2304.14006v1
🚀 Dataset: https://paperswithcode.com/dataset/wukong
ai_machinelearning_big_data
A text-guided generative system without any finetuning (zero-shot).
Edit Everything позволяет пользователям редактировать изображения с помощью простых текстовых инструкций.
🚀 Dataset: https://paperswithcode.com/dataset/wukong
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3👍2🔥2
Forwarded from Сиолошная
Промпты, промпты, промптики...
Промпты для современных GPT-моделек это вообще всё. Они позволяют переключить модель в некоторое "состояние", из которого вероятность генерации правильных/удовлетворяющих вас/клевых ответов выше. Вот наткнулся на офигенный промпт, и хочу поделиться с вами.
Сегодня у нас в гостях Mr. Ranedeer — AI Tutor на основе GPT-4. Он обеспечивает персонализированный опыт обучения для пользователей с различными потребностями и интересами. Имеет 6 разных настроек, включая глубину обучения, тип и тон повествования.
Согласно промпту, сначала производится настройка, затем составляется план обучения, а дальше идет двусторонний диалог учителя и ученика (вас).
Пока учитель ограничен лишь своими знаниями, но ясно, что с подключением плагина на веб-поиск это станет бомбой.
Репозиторий - тут
Детальная документация по промпту (лол, дожили!) - здесь
Сам промпт - вот, прям выделяете всё, копируете и вставляете в ChatGPT сразу (не превышает заданную длину контекста для модели, всё ок)
Киллер-фича: можно написать
Те, у кого оплачена подписка ChatGPT Plus - обязательно попробуйте, и поделитесь впечатлениями и скринами в комментариях. Предложу такие темы, как:
— conditions in English language
— asteroid mining and space exporation
— how can we integrate using analog devices
— how to start business with generative AI
— LLM prompting intro
Гспд вы только представьте как изменится образование для наших детей...(никак, хехе, спасибо бюрократии🤬 )
Промпты для современных GPT-моделек это вообще всё. Они позволяют переключить модель в некоторое "состояние", из которого вероятность генерации правильных/удовлетворяющих вас/клевых ответов выше. Вот наткнулся на офигенный промпт, и хочу поделиться с вами.
Сегодня у нас в гостях Mr. Ranedeer — AI Tutor на основе GPT-4. Он обеспечивает персонализированный опыт обучения для пользователей с различными потребностями и интересами. Имеет 6 разных настроек, включая глубину обучения, тип и тон повествования.
Согласно промпту, сначала производится настройка, затем составляется план обучения, а дальше идет двусторонний диалог учителя и ученика (вас).
Пока учитель ограничен лишь своими знаниями, но ясно, что с подключением плагина на веб-поиск это станет бомбой.
Репозиторий - тут
Детальная документация по промпту (лол, дожили!) - здесь
Сам промпт - вот, прям выделяете всё, копируете и вставляете в ChatGPT сразу (не превышает заданную длину контекста для модели, всё ок)
Киллер-фича: можно написать
/test, чтобы попросить модель потестировать ваши знания по уже пройденному материалуТе, у кого оплачена подписка ChatGPT Plus - обязательно попробуйте, и поделитесь впечатлениями и скринами в комментариях. Предложу такие темы, как:
— conditions in English language
— asteroid mining and space exporation
— how can we integrate using analog devices
— how to start business with generative AI
— LLM prompting intro
Гспд вы только представьте как изменится образование для наших детей...(никак, хехе, спасибо бюрократии
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3
Forwarded from gonzo-обзоры ML статей
И ещё из новостей:
In this repo, we release a permissively licensed open source reproduction of Meta AI's LLaMA large language model. In this release, we're releasing a public preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens. We provide PyTorch and Jax weights of pre-trained OpenLLaMA models, as well as evaluation results and comparison against the original LLaMA models. Stay tuned for our updates.
https://github.com/openlm-research/open_llama
In this repo, we release a permissively licensed open source reproduction of Meta AI's LLaMA large language model. In this release, we're releasing a public preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens. We provide PyTorch and Jax weights of pre-trained OpenLLaMA models, as well as evaluation results and comparison against the original LLaMA models. Stay tuned for our updates.
https://github.com/openlm-research/open_llama
GitHub
GitHub - openlm-research/open_llama: OpenLLaMA, a permissively licensed open source reproduction of Meta AI’s LLaMA 7B trained…
OpenLLaMA, a permissively licensed open source reproduction of Meta AI’s LLaMA 7B trained on the RedPajama dataset - openlm-research/open_llama
Forwarded from Data Science by ODS.ai 🦜
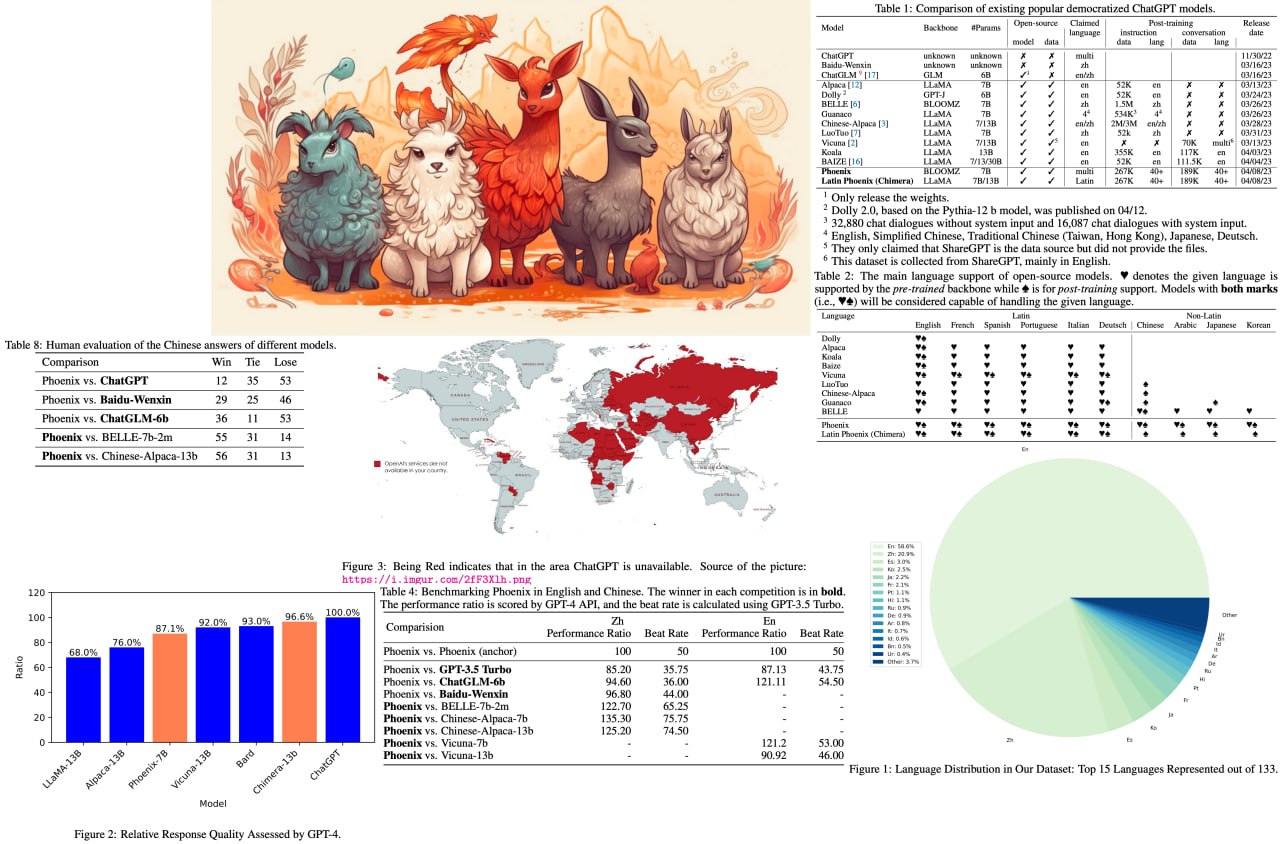
Phoenix: Democratizing ChatGPT across Languages
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
{kind=link}
Forwarded from Machinelearning
Awesome list for ChatGPT — an artificial intelligence chatbot
Awesome список для ChatGPT.
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
❤2👍2
Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs
Introducing MPT-7B, the latest entry in our MosaicML Foundation Series. MPT-7B is a transformer trained from scratch on 1T tokens of text and code. It is open source, available for commercial use, and matches the quality of LLaMA-7B. MPT-7B was trained on the MosaicML platform in 9.5 days with zero human intervention at a cost of ~$200k. Starting today, you can train, finetune, and deploy your own private MPT models, either starting from one of our checkpoints or training from scratch. For inspiration, we are also releasing three finetuned models in addition to the base MPT-7B: MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+, the last of which uses a context length of 65k tokens!
https://www.mosaicml.com/blog/mpt-7b
Introducing MPT-7B, the latest entry in our MosaicML Foundation Series. MPT-7B is a transformer trained from scratch on 1T tokens of text and code. It is open source, available for commercial use, and matches the quality of LLaMA-7B. MPT-7B was trained on the MosaicML platform in 9.5 days with zero human intervention at a cost of ~$200k. Starting today, you can train, finetune, and deploy your own private MPT models, either starting from one of our checkpoints or training from scratch. For inspiration, we are also releasing three finetuned models in addition to the base MPT-7B: MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+, the last of which uses a context length of 65k tokens!
https://www.mosaicml.com/blog/mpt-7b
👍4❤2
Forwarded from gonzo-обзоры ML статей
Looks interesting!
Introducing ImageBind by Meta AI: the first AI model capable of binding information from six different modalities at once.
Humans absorb information from the world by combining data from different senses, like sight and sound. ImageBind brings machines one step closer to this ability with a model that’s capable of learning a single embedding for text, image/video, audio, depth, thermal and IMU inputs. We hope this work opens the floodgates for researchers as they work to develop new, holistic systems across a wide array of real-world applications.
The model and a new paper are now available publicly for the research community.
https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Introducing ImageBind by Meta AI: the first AI model capable of binding information from six different modalities at once.
Humans absorb information from the world by combining data from different senses, like sight and sound. ImageBind brings machines one step closer to this ability with a model that’s capable of learning a single embedding for text, image/video, audio, depth, thermal and IMU inputs. We hope this work opens the floodgates for researchers as they work to develop new, holistic systems across a wide array of real-world applications.
The model and a new paper are now available publicly for the research community.
https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Meta
ImageBind: Holistic AI learning across six modalities
ImageBind is the first AI model capable of binding information from six modalities.
🔥3
Forwarded from Spark in me (Alexander)
Found another PyTorch-based library with basic image functions, losses and transformations
Looks like it is a combination toolkit of augs, skimage and classic cv2 functions, but written in PyTorch.
What is Kornia? Kornia is a differentiable library that allows classical computer vision to be integrated into deep learning models.
Examples:
- https://kornia.readthedocs.io/en/latest/get-started/highlights.html
- and especially this https://kornia.readthedocs.io/en/latest/losses.html
Looks like it is a combination toolkit of augs, skimage and classic cv2 functions, but written in PyTorch.
What is Kornia? Kornia is a differentiable library that allows classical computer vision to be integrated into deep learning models.
Examples:
- https://kornia.readthedocs.io/en/latest/get-started/highlights.html
- and especially this https://kornia.readthedocs.io/en/latest/losses.html
Forwarded from Machinelearning
This media is not supported in your browser
VIEW IN TELEGRAM
🔥 ImageBind: One Embedding Space To Bind Them All
ImageBind, an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data.
ImageBind, новый подход от Meta к обучению совместному встраиванию шести различных модальностей - текста,изображений, аудио, глубины, тепловых данных и данных IMU.
🖥 Github: https://github.com/facebookresearch/imagebind
Ⓜ️ Meta blog: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
⏩ Paper: https://arxiv.org/pdf/2305.05665v1.pdf
⭐️ Demo: https://imagebind.metademolab.com/
📌 Dataset: https://paperswithcode.com/dataset/msr-vtt
ai_machinelearning_big_data
ImageBind, an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data.
ImageBind, новый подход от Meta к обучению совместному встраиванию шести различных модальностей - текста,изображений, аудио, глубины, тепловых данных и данных IMU.
Ⓜ️ Meta blog: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
📌 Dataset: https://paperswithcode.com/dataset/msr-vtt
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
❤2
Forwarded from Denis Sexy IT 🤖
Так, ну было хоть и местами скучно, мне понравилось:
🪙 Gmail получит встроенную LLM для автоматического написания черновика. Например, отменили рейс и прислали вам письмо, вы можете сразу написать заявку на рефанд с помощью одной кнопки. В целом, ничего нового, делаю такое же с ChatGPT через плагин.
🪙 Google Maps получит обновление летом, а точнее его функция Immersive view - строите маршрут и он показывает его как в SimCity в 3D на основе реальных данных (скан реального мира), с машинками виртуальными и тп. Тут видео.
🪙 Google показал свой новый ответ GPT от OpenAI – Palm 2, это серия моделей от самой маленькой которая может работать оффлайн на телефоне и до самой большой которая работает в облаке. Bard, ChatGPT от Google, тоже перевели на Palm 2 уже сегодня. Еще в Bard добавят плагины, такие же как в ChatGPT. И с сегодня доступ открыли для всех:
https://bard.google.com
Google также показал интеграцию Bard в Google Docs, Slides, Tables и тп, тут как бы тоже все что вы уже видели от Microsoft.
🪙 Google поиск чуть изменит результаты выдачи, и первый остров станет пытаться отвечать на вопрос в стиле ChatGPT.
Если честно, очень логичный шаг, очень утомляет ходить в ChatGPT или Bing Chat когда ищешь ответ на вопрос, не всегда же приходишь пообщаться, иногда просто нужен быстрый ответ (но опция початиться тоже останется). "Остров ответа нейронкой" занимает немного места, так что сможете использовать Google как обычно, промотав ответ языковой модели. Видео тут.
Лица SEO-экспертов имаджинировали?
🪙 Теперь большой бизнес может купить тренировку своей большой языковой модели в Google Cloud через Vertex AI. Это, условно, если вы хотите в организации рабочего бота обученного на данных компании, и вам не хочется нанимать свой R&D отдел, вы можете заплатить им и они сделают все что нужно, на самых лучших моделях. Золотая жила и классный продукт.
Доступен тут, обещают ранний доступ:
https://cloud.google.com/vertex-ai
🪙 Тут в целом можно посмотреть про AI штуки что показали, и запросить доступы:
https://labs.withgoogle.com/
В общем, как и ожидалось, Google долго запрягает, потому что они большие, но им есть куда встраивать AI-штуки, и главное они знают как их сделать удобными, молодцы (но мне все еще нравится подшучивать над ними когда у них что-то не получается☺️ )
https://bard.google.com
Google также показал интеграцию Bard в Google Docs, Slides, Tables и тп, тут как бы тоже все что вы уже видели от Microsoft.
Если честно, очень логичный шаг, очень утомляет ходить в ChatGPT или Bing Chat когда ищешь ответ на вопрос, не всегда же приходишь пообщаться, иногда просто нужен быстрый ответ (но опция початиться тоже останется). "Остров ответа нейронкой" занимает немного места, так что сможете использовать Google как обычно, промотав ответ языковой модели. Видео тут.
Лица SEO-экспертов имаджинировали?
Доступен тут, обещают ранний доступ:
https://cloud.google.com/vertex-ai
https://labs.withgoogle.com/
В общем, как и ожидалось, Google долго запрягает, потому что они большие, но им есть куда встраивать AI-штуки, и главное они знают как их сделать удобными, молодцы (но мне все еще нравится подшучивать над ними когда у них что-то не получается
Please open Telegram to view this post
VIEW IN TELEGRAM
👍4
Forwarded from Machinelearning
VideoChat: Chat-Centric Video Understanding
Currently, Ask-Anything is a simple yet interesting tool for chatting with video.
Набор данных, ориентированный на видео, состоящий из тысяч видеороликов, сопровождаемых подробными описаниями и субтитрами.
🖥 Github: https://github.com/OpenGVLab/Ask-Anything
⭐️ Demo: https://huggingface.co/spaces/ynhe/AskAnything
⏩ Paper: https://arxiv.org/pdf/2305.06355v1.pdf
📌 Dataset: https://paperswithcode.com/dataset/webvid
ai_machinelearning_big_data
Currently, Ask-Anything is a simple yet interesting tool for chatting with video.
Набор данных, ориентированный на видео, состоящий из тысяч видеороликов, сопровождаемых подробными описаниями и субтитрами.
📌 Dataset: https://paperswithcode.com/dataset/webvid
ai_machinelearning_big_data
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3❤2🔥1