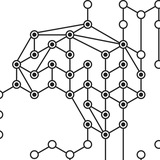
На ICLR-2022 была, оказывается, такая интересная работа: авторы показали, что принцип работы Transformer’ов (с небольшим дополнением) схож с принципом работы гиппокампа и энторинальной коры головного мозга человека.
(Автор работы, если что, Ph.D. по computational/ theoretical neuroscience из Stanford и Oxford. Понимает, о чем говорит)
Подробнее:
Гиппокамп и энториальная кора мозга вместе отвечают за память, восприятие времени и пространства. Энториальная кора является “шлюзом” для гиппокампа: она обрабатывает поступающую в гиппокамп и исходящую из него информацию. Гиппокамп же обрабатывает и структурирует все виды памяти: краткосрочную, долгосрочную, пространственную.
То есть, связка “гиппокамп + энторинальная кора” (EC-hippocampus) играют важную роль при решении человеком задач, связанных с пространственным восприятием.
Как показали, почему Transformer “похож” на EC-hippocampus: авторы статьи взяли Transformer и обучили его на простую задачу, в которой нужно выдавать ответ, имея в виду текущее пространственно положение. Архитектура Transformer была стандартная с парой небольших отличий в формуле для attention и position encodings. Вычисление position encodings было изменено так, что стало обучаемым.
После обучения модели ученые посмотрели на “пространственную карту весов position encodings”. Карта составляется просто: для каждого пространственного положения из задачи, которую учил Tranformer, вычисляется средняя активация position encodings. Так вот, оказалось, что эта карта структурно схожа с той, что получается из активаций нейронов в EC-hippocampus
Но это еще не все: только такая “похожесть” карт активаций нейронов в мозге и модели недостаточно убедительна. Авторы статьи так же показали следующее: архитектура Transformer эквивалентна математической модели EC-hippocampus, которую нейробиологи построили не так давно и активно используют. Эта матмодель называется TEM (Tolman-Eichenbaum Machine), и она хорошо описывает основные процессы, происходящие в EC-hippocampus. TEM — обучаемся модель, которая при обучении должна имитировать процессы, происходящие в EC-hippocampus.
Так вот, упомянутый выше модифицированный Transformer, оказывается, имеет аналогичное с TEM устройство. Аторы назвали такой трансформер TEM-t. В статье авторы показывают аналогии между отдельными компонентами Transformer и TEM. В частности, “модель памяти” TEM оказывается эквивалентной self-attention из Tranformer.
Более того, авторы заявляют, что TEM-t может служить более эффективной моделью EC-hippocampus, чем существующий TEM: он гораздо быстрее обучается, имеет больший потенциал по памяти (может “запоминать” и “вытаскивать” больше бит памяти). Также плюсом является то, что пространственная карта весов position encodings трансформера похожа на такую карту из мозга (о чем писала выше).
Подробнее об устройстве TEM, TEM-t, экспериментах и о том, какое значение это имеет для нейробиологии — в статье. А еще там есть описание того, как архитектура Transformer может быть реализована на биологических нейронах. Блин, а вдруг какие-то части нашего мозга — это реально transformer’ы?)
Еще ссылка: статья в Quantamagazine об этой работе
P.S. Надеюсь, я нигде сильно не наврала. Все же в вопросах устройства мозга и подобном я дилетант. Feel free поправлять меня в комментариях
#ai_inside #paper
(Автор работы, если что, Ph.D. по computational/ theoretical neuroscience из Stanford и Oxford. Понимает, о чем говорит)
Подробнее:
Гиппокамп и энториальная кора мозга вместе отвечают за память, восприятие времени и пространства. Энториальная кора является “шлюзом” для гиппокампа: она обрабатывает поступающую в гиппокамп и исходящую из него информацию. Гиппокамп же обрабатывает и структурирует все виды памяти: краткосрочную, долгосрочную, пространственную.
То есть, связка “гиппокамп + энторинальная кора” (EC-hippocampus) играют важную роль при решении человеком задач, связанных с пространственным восприятием.
Как показали, почему Transformer “похож” на EC-hippocampus: авторы статьи взяли Transformer и обучили его на простую задачу, в которой нужно выдавать ответ, имея в виду текущее пространственно положение. Архитектура Transformer была стандартная с парой небольших отличий в формуле для attention и position encodings. Вычисление position encodings было изменено так, что стало обучаемым.
После обучения модели ученые посмотрели на “пространственную карту весов position encodings”. Карта составляется просто: для каждого пространственного положения из задачи, которую учил Tranformer, вычисляется средняя активация position encodings. Так вот, оказалось, что эта карта структурно схожа с той, что получается из активаций нейронов в EC-hippocampus
Но это еще не все: только такая “похожесть” карт активаций нейронов в мозге и модели недостаточно убедительна. Авторы статьи так же показали следующее: архитектура Transformer эквивалентна математической модели EC-hippocampus, которую нейробиологи построили не так давно и активно используют. Эта матмодель называется TEM (Tolman-Eichenbaum Machine), и она хорошо описывает основные процессы, происходящие в EC-hippocampus. TEM — обучаемся модель, которая при обучении должна имитировать процессы, происходящие в EC-hippocampus.
Так вот, упомянутый выше модифицированный Transformer, оказывается, имеет аналогичное с TEM устройство. Аторы назвали такой трансформер TEM-t. В статье авторы показывают аналогии между отдельными компонентами Transformer и TEM. В частности, “модель памяти” TEM оказывается эквивалентной self-attention из Tranformer.
Более того, авторы заявляют, что TEM-t может служить более эффективной моделью EC-hippocampus, чем существующий TEM: он гораздо быстрее обучается, имеет больший потенциал по памяти (может “запоминать” и “вытаскивать” больше бит памяти). Также плюсом является то, что пространственная карта весов position encodings трансформера похожа на такую карту из мозга (о чем писала выше).
Подробнее об устройстве TEM, TEM-t, экспериментах и о том, какое значение это имеет для нейробиологии — в статье. А еще там есть описание того, как архитектура Transformer может быть реализована на биологических нейронах. Блин, а вдруг какие-то части нашего мозга — это реально transformer’ы?)
Еще ссылка: статья в Quantamagazine об этой работе
P.S. Надеюсь, я нигде сильно не наврала. Все же в вопросах устройства мозга и подобном я дилетант. Feel free поправлять меня в комментариях
#ai_inside #paper
👍49🔥13❤2👎2🤯1🤮1🤨1
Айра — моя знакомая и основательница школы Mathshub, в которой я вела занятия и приглашала вас весной — запустила свой подкаст “Не сами боги”
В нем разные гости из мира ИИ, технологий и масштабных продуктов будут делится опытом и историями из жизни.
Сейчас доступен первый эпизод, второй появится где-то в октябре. Гость эпизода — Юрий Кашницкий: друг Айры, опытный дата-сайнтист, основатель одного из самых известных и фундаментальных курсов по классическому машинному обучению и анализу данных — mlcourse.ai.
Говорили о разном: об интервью, Kaggle, исследованиях, математике, синдроме самозванца. На мой взгляд, получилось круто. Подробнее — в описании к эпизоду на YouTube.
Подкаст с видео (очень качественным, не то, что у меня🥲), запись первого эпизода проходила в Амстердаме.
🎙Смотреть “Не сами боги” на YouTube
Ссылки на подкаст на других платформах (Apple/Google/Yandex) тут
В нем разные гости из мира ИИ, технологий и масштабных продуктов будут делится опытом и историями из жизни.
Сейчас доступен первый эпизод, второй появится где-то в октябре. Гость эпизода — Юрий Кашницкий: друг Айры, опытный дата-сайнтист, основатель одного из самых известных и фундаментальных курсов по классическому машинному обучению и анализу данных — mlcourse.ai.
Говорили о разном: об интервью, Kaggle, исследованиях, математике, синдроме самозванца. На мой взгляд, получилось круто. Подробнее — в описании к эпизоду на YouTube.
Подкаст с видео (очень качественным, не то, что у меня🥲), запись первого эпизода проходила в Амстердаме.
🎙Смотреть “Не сами боги” на YouTube
Ссылки на подкаст на других платформах (Apple/Google/Yandex) тут
👍31👎5🔥5⚡1👏1
This media is not supported in your browser
VIEW IN TELEGRAM
Хотите научиться решать действительно важные для бизнеса задачи и проектировать всю необходимую ML-инфраструктуру?
#промо
Валерий Бабушкин (Head of Data Science в Blockchainꓸcom, ранее работал в Facebook, Alibaba, X5 Group, Яндекс) со своими друзьями — руководителями Data Science направлений в крупнейших компаниях — записал свой авторский курс по хардкорному ML.
Вы научитесь самостоятельно собирать и размечать данные, строить пайплайны их поставки, деплоить приложения, настраивать мониторинги и оценивать эффективность алгоритмов.
Сразу предупреждаем — придется интенсивно поработать. Но оно определённо того стоит, ведь знания прикладные: каждый модуль заканчивается разработкой ML-сервиса, который будет не стыдно показать будущему работодателю или адептам ODS.
Переходите по ссылке и записывайтесь на курс до 3 октября — по промокоду DLS20 вы получите скидку 10% на полную оплату курса.
А чтобы вы могли посмотреть, как обучение выглядит изнутри, мы подготовили бесплатную демоверсию!
#промо
Валерий Бабушкин (Head of Data Science в Blockchainꓸcom, ранее работал в Facebook, Alibaba, X5 Group, Яндекс) со своими друзьями — руководителями Data Science направлений в крупнейших компаниях — записал свой авторский курс по хардкорному ML.
Вы научитесь самостоятельно собирать и размечать данные, строить пайплайны их поставки, деплоить приложения, настраивать мониторинги и оценивать эффективность алгоритмов.
Сразу предупреждаем — придется интенсивно поработать. Но оно определённо того стоит, ведь знания прикладные: каждый модуль заканчивается разработкой ML-сервиса, который будет не стыдно показать будущему работодателю или адептам ODS.
Переходите по ссылке и записывайтесь на курс до 3 октября — по промокоду DLS20 вы получите скидку 10% на полную оплату курса.
А чтобы вы могли посмотреть, как обучение выглядит изнутри, мы подготовили бесплатную демоверсию!
❤🔥19💩8👍6🤮4🔥1
В сфере языковых моделей существует интересная проблема, о которой я как-то раньше не задумывалась. Состоит она вот в чем: когда модель обучалась, мир был устроен одним образом. Например, президентом США был Трамп, королева UK была жива, а текущей мировой проблемой был covid-19. Но проходит время, и теперь президент США — Байден, королевы больше нет, а воспоминания ковидного времени — прямо таки ностальгические. Задача, в общем, понятна: как впихнуть в обученную языковую модель новые знания об отдельных вещах/событиях?
Задача не так проста, как кажется: простое изменение инфы вида “президент Трамп -> президент Байден” влияет на очень много запросов и ответов модели. И нужно изменить веса сети не только чтобы научилась правильно отвечать на вопрос “кто президент США”, но и на любые каверзные вопросы, для ответа на которые нужно знание о том, кто сидит в Белом доме.
Так вот, к решению этой задачи существует много подходов. Вот какие у них идеи:
- разные техники дообучения небольшого числа параметров сети (не всей сети целиком) на новых примерах;
- использование трюков с архитектурой и способ обучения сети, которые позволяют сделать так, чтобы последующие изменения в сеть можно было вносить, изменяя только опеределенную малую ее часть. Например, есть подход, который выделяет отдельные нейроны сети под отдельные факты, и изменение инфы об этих фактах достигается изменением активации этого конкретного нейрона;
- подходы, при которых изначально обученная сеть никак не меняется. Но создаются дополнительные мини-модели, которые дообучаются под новые факты и во время инференса помогают начальной модели выдать актуальный ответ на вопрос.
На статью с новой идеей архитектуры в парадигме третьего подхода (без изменения основной сети) я и наткнулась недавно. Идея вот какая:
Не менять изначальную модель. Когда в мире изменяется некий факт, который изначально был заложен в модель (например, сменился президент США), этот факт запомниается в отдельный кеш памяти. Далее при каждом новом запросе в модель происходит следующее:
- небольшая модель-классификатор определяет, связан ли новый запрос с каким-то из фактов в кеше памяти;
- если запрос не связан ни с одним фактом из памяти, модель генерирует ответ как обычно. Если же нашелся факт (или несколько), связанный с запросом, то модели на фход вместе с запросом подается этот связанный факт, и модель генерирует ответ.
Получается, дообучать под новые факты ничего не надо: только сохранять в память. Единственная проблемы, которые может возникнуть — это то, что фактов станет слишком много и они станут занимать кучу памяти. Авторы говорят, что это hardly a problem: один факт — это ~3кб памяти.
Вот так вот. Идея интересная и очень простая, что есть ее огромный плюс. Но у меня в голове крутятся две мысли по этому поводу:
Во-первых, когда я читала эту статью, меня не покидало ощущение, что это как-то не очень естественно. Ну то есть, хочется изобрести какой-то более элегантный способ внеднять новые знания в модель, не таская их за собой в виде мешка фактов. Не могу объяснить, чем подход “неестествен”, но ощущение такое.
И вторая мысль: эта идея, по сути, имитирует zero-shot режим работы модели. Но когда идут разговоры про zero-shot режим, это чаще всего про сценарий вида “есть задача. Мы подаем на вход модели пару примеров “input -> output”, затем новый инпут и ждем, что она выдаст правильный ответ. Например:
“Paris -> France”
“Moscow -> Russia”
“Tbilisi ->”
и ждем на выходе ”Georgia”. Так вот, вопрос в том, будет ли это работать в виде “подаем модели на вход факт, затем начинаем с ней болтать”. Будет ли модель иметь этот факт в виду? Или как нужно сформулировать вход, чтобы модель в zero-shot режиме поняла, что нужно принять этот факт во внимание для генерации последующих текстов?
#paper
Задача не так проста, как кажется: простое изменение инфы вида “президент Трамп -> президент Байден” влияет на очень много запросов и ответов модели. И нужно изменить веса сети не только чтобы научилась правильно отвечать на вопрос “кто президент США”, но и на любые каверзные вопросы, для ответа на которые нужно знание о том, кто сидит в Белом доме.
Так вот, к решению этой задачи существует много подходов. Вот какие у них идеи:
- разные техники дообучения небольшого числа параметров сети (не всей сети целиком) на новых примерах;
- использование трюков с архитектурой и способ обучения сети, которые позволяют сделать так, чтобы последующие изменения в сеть можно было вносить, изменяя только опеределенную малую ее часть. Например, есть подход, который выделяет отдельные нейроны сети под отдельные факты, и изменение инфы об этих фактах достигается изменением активации этого конкретного нейрона;
- подходы, при которых изначально обученная сеть никак не меняется. Но создаются дополнительные мини-модели, которые дообучаются под новые факты и во время инференса помогают начальной модели выдать актуальный ответ на вопрос.
На статью с новой идеей архитектуры в парадигме третьего подхода (без изменения основной сети) я и наткнулась недавно. Идея вот какая:
Не менять изначальную модель. Когда в мире изменяется некий факт, который изначально был заложен в модель (например, сменился президент США), этот факт запомниается в отдельный кеш памяти. Далее при каждом новом запросе в модель происходит следующее:
- небольшая модель-классификатор определяет, связан ли новый запрос с каким-то из фактов в кеше памяти;
- если запрос не связан ни с одним фактом из памяти, модель генерирует ответ как обычно. Если же нашелся факт (или несколько), связанный с запросом, то модели на фход вместе с запросом подается этот связанный факт, и модель генерирует ответ.
Получается, дообучать под новые факты ничего не надо: только сохранять в память. Единственная проблемы, которые может возникнуть — это то, что фактов станет слишком много и они станут занимать кучу памяти. Авторы говорят, что это hardly a problem: один факт — это ~3кб памяти.
Вот так вот. Идея интересная и очень простая, что есть ее огромный плюс. Но у меня в голове крутятся две мысли по этому поводу:
Во-первых, когда я читала эту статью, меня не покидало ощущение, что это как-то не очень естественно. Ну то есть, хочется изобрести какой-то более элегантный способ внеднять новые знания в модель, не таская их за собой в виде мешка фактов. Не могу объяснить, чем подход “неестествен”, но ощущение такое.
И вторая мысль: эта идея, по сути, имитирует zero-shot режим работы модели. Но когда идут разговоры про zero-shot режим, это чаще всего про сценарий вида “есть задача. Мы подаем на вход модели пару примеров “input -> output”, затем новый инпут и ждем, что она выдаст правильный ответ. Например:
“Paris -> France”
“Moscow -> Russia”
“Tbilisi ->”
и ждем на выходе ”Georgia”. Так вот, вопрос в том, будет ли это работать в виде “подаем модели на вход факт, затем начинаем с ней болтать”. Будет ли модель иметь этот факт в виду? Или как нужно сформулировать вход, чтобы модель в zero-shot режиме поняла, что нужно принять этот факт во внимание для генерации последующих текстов?
#paper
👍36🤔10🤮2
Всем привет! Извините, что неделю (даже больше) не было постов: у меня было больше дел, чем я могла вывезти, плюс некоторое нервное напряжение.
Сейчас я сижу в Шереметьево, жду рейс в Стамбул. Там буду находиться до конца октября, затем уезжаю в Лондон. В Лондоне буду делать Ph.D. у вот этого профессора. В связи с отъездом (все же немного даже неожиданным, планировала уехать чуть позже) и были гора дел.
Тут снова будут регулярные посты в самое ближайшее время. Стоило блин только отвлечься, как наклепали классных статей и нейронок😅 Прямо сейчас вот сижу пишу один)
А у вас как дела?
Сейчас я сижу в Шереметьево, жду рейс в Стамбул. Там буду находиться до конца октября, затем уезжаю в Лондон. В Лондоне буду делать Ph.D. у вот этого профессора. В связи с отъездом (все же немного даже неожиданным, планировала уехать чуть позже) и были гора дел.
Тут снова будут регулярные посты в самое ближайшее время. Стоило блин только отвлечься, как наклепали классных статей и нейронок😅 Прямо сейчас вот сижу пишу один)
А у вас как дела?
👍110❤46🔥26🍾11🕊9🙏4💩3👎2🤮2💋1
FoldingDiff: диффузионная модель для генерации структур протеинов.
#paper
По порядку:
Задача генерации протеинов состоит в том, чтобы из атомов и аминокислот создавать новые структуры протеинов, которые действительно стабильно могут существовать а реальном мире. Со времен AlphaFold мы помним, что находить структуры протеинов — сложная задача. Каждый протеин имеет свою уникальную пространственную структуру, которую очень сложно найти даже если аминокислоты, составляющие протеин, известны. А здесь задача еще круче: сгенерировать новые, неизвестные протеины, которые могут существовать в стабильном состоянии.
Как работает диффузия для молекул:
Во-первых, пару слов о том, какое представление используют для молекулы протеина. Есть несколько вариантов, как это делать. Первый — в виде графа в 3-хмерном пространстве (3D-point cloud). Это довольно простой и логичный вариант, который использовали во многих (в том числе недавних) работах по генерации протеинов. Второй вариант представления молекулы — с помощью углов между ее атомами: каждая аминокислота, входящая в состав протеина — это вектор из шести значений (углов). Именно такой вариант используется в FoldingDiff.
Такое представление имеет огромное преимущество: оно не зависит от пространственного положения молекулы. Как бы ни была повернута молекула протеина, ее представление будет одинаковым. 3D point cloud таким свойством не обладает. Это позволяет использовать более легкие модели, с меньшим количеством параметров, для генерации протеинов.
Также авторы говорят, что у такого представления есть еще одно преимущество — оно “имитирует” то, как протеины образуются в реальности, “заворачивая” свои аминокислоты под разными углами, достигая энергетически самого выгодного представления.
Итак, в итоге каждый протеин представляется в виде матрицы размера 6xN, где N — количество аминокислот в составе протеина. К этому представлению постепенно добавляется гауссов шум, пока распределение чисел матрицы не станет неотличимым от wrapped gaussian. Задача модели — из такого представления восстановить структуру молекулы. Обученная модель далее может из рандомных матриц размера 6xN генерировать новые структуры молекул. Процесс показан на картинке к посту выше.
Сама модель очень простая — обычный bidirectional transformer. Модель генерирует структуру протеина шаг за шагом — на каждом шаге генерируется очередной вектор размера 6, соответствующий следующей аминокислоте в цепочке.
Эксперименты показывают, что обученная модель действительно часто генерирует структуры белков, которые можно получить в реальности. “Получить в реальности” означает, что для сгенеренной моделью последовательности углов аминокислот можно подобрать такие атомы, что существует реальный протеин с этими атомами и углами между ними. Также авторы показывают, что модель генерит довольно разнообразные структуры: более разнообразные, чем это делали предыдущие SOTA модели для этой задачи.
Детали устройства модели и экспериментов читайте в статье.
Также есть код на GitHub
#paper
По порядку:
Задача генерации протеинов состоит в том, чтобы из атомов и аминокислот создавать новые структуры протеинов, которые действительно стабильно могут существовать а реальном мире. Со времен AlphaFold мы помним, что находить структуры протеинов — сложная задача. Каждый протеин имеет свою уникальную пространственную структуру, которую очень сложно найти даже если аминокислоты, составляющие протеин, известны. А здесь задача еще круче: сгенерировать новые, неизвестные протеины, которые могут существовать в стабильном состоянии.
Как работает диффузия для молекул:
Во-первых, пару слов о том, какое представление используют для молекулы протеина. Есть несколько вариантов, как это делать. Первый — в виде графа в 3-хмерном пространстве (3D-point cloud). Это довольно простой и логичный вариант, который использовали во многих (в том числе недавних) работах по генерации протеинов. Второй вариант представления молекулы — с помощью углов между ее атомами: каждая аминокислота, входящая в состав протеина — это вектор из шести значений (углов). Именно такой вариант используется в FoldingDiff.
Такое представление имеет огромное преимущество: оно не зависит от пространственного положения молекулы. Как бы ни была повернута молекула протеина, ее представление будет одинаковым. 3D point cloud таким свойством не обладает. Это позволяет использовать более легкие модели, с меньшим количеством параметров, для генерации протеинов.
Также авторы говорят, что у такого представления есть еще одно преимущество — оно “имитирует” то, как протеины образуются в реальности, “заворачивая” свои аминокислоты под разными углами, достигая энергетически самого выгодного представления.
Итак, в итоге каждый протеин представляется в виде матрицы размера 6xN, где N — количество аминокислот в составе протеина. К этому представлению постепенно добавляется гауссов шум, пока распределение чисел матрицы не станет неотличимым от wrapped gaussian. Задача модели — из такого представления восстановить структуру молекулы. Обученная модель далее может из рандомных матриц размера 6xN генерировать новые структуры молекул. Процесс показан на картинке к посту выше.
Сама модель очень простая — обычный bidirectional transformer. Модель генерирует структуру протеина шаг за шагом — на каждом шаге генерируется очередной вектор размера 6, соответствующий следующей аминокислоте в цепочке.
Эксперименты показывают, что обученная модель действительно часто генерирует структуры белков, которые можно получить в реальности. “Получить в реальности” означает, что для сгенеренной моделью последовательности углов аминокислот можно подобрать такие атомы, что существует реальный протеин с этими атомами и углами между ними. Также авторы показывают, что модель генерит довольно разнообразные структуры: более разнообразные, чем это делали предыдущие SOTA модели для этой задачи.
Детали устройства модели и экспериментов читайте в статье.
Также есть код на GitHub
👍25🔥8🤮1🕊1
В MIT исследовали феномен гроккинга (grokking) и, кажется, нашли этому эффекту правдоводобное объяснение
#paper
Grokking — это эффект, при котором уже после стадии переобучения модели (при возрастающем test лоссе и падаюшем train) при дальнейшем обучении test loss вдруг начинает падать, и сеть лучше генерализуется. Такой эффект наблюдали уже давно (например, вот тут), но, чаще всего, на малых, “игрушечных” датасетах (например, на такой простой задаче как сложение чисел). Никакого сильно убедительного объяснения эффекту не было (насколько я знаю), а также не удавалось повторить эффект на реальных, не игрушечных данных.
Ребята из MIT подошли ближе к пониманию природы grokking’а и даже смогли воспроизвести эффект на разных больших датасетах.
Авторы связывают эффект гроккинга с устройством поверхности лосс-функции. В недавней работе из Стенфорда было показано, что у этой поверхности существует сферическая область, в которой достигается оптимальная генерализация модели: то есть, для модели с параметрами из этой области train и test loss малы, переобучения при этом не наблюдается. Эту сферическую область ребята из Стенфорда назвали Goldilocks zone (“зона Златовласки”, показана на картинке зеленым). Так как область сферическая, она соответствует параметрам модели с определенной нормой. Внутренность это сферической области соответствует параметрам с меньшем нормой, область вне сферы — параметрам с большей нормой.
Далее: оказывается, grokking начинает проявляться, если в какой-то момент параметры сети имели большую норму (то есть, соответствовали точке поверхности вне сферы Златовласки). В этом случае параметры из этой точки быстро скатываются в точку локального минимума, которая также чаще всего находится за пределами сферы Златовласки, т.е. вне той области, где достигается оптимальная генерализация модели. Лосс на train становится малым, лосс на test остается большим: наблюдается переобучение.
Далее происходит следующее: если у модели нет никакой регуляризации (weight decay, к примеру), то на этом обучение модели заканчивается. Лосс не выходит из точки минимума, grokking не наблюдается, переобучение остается. Но если к модели применяется регуляризация, это выталкивает веса модели из локального минимума, и они начинают стремиться к зоне Златовласки. Обычно регуляризация применяется не очень сильная, поэтому проходит довольно много эпох обучения, прежде чем веса модели достигают точки внутри зоны Goldilocks и модель начинает генерализоваться. Это и объясняет эффект гроккинга: когда через достаточно долгое время после переобучения лосс на тесте вдруг падает и модель начинает лучше обобщаться.
Кстати, если у модели регуляризация довольно сильная, grokking’а тоже не будет: веса модели будут сразу быстро приходить внутрь зоны Златовласки, не задерживаясь в локальном минимуме вне сферы. Модель просто сразу достаточно хорошо генерализуется.
Теперь, почему grokking часто наблюдают на “игрушечных” датасетах, и почти никогда — на реальных. Во-первых, обычно веса любых нейросетей инициализируют значениями с довольно малой нормой, т.е. лежащими внутри зоны Златовласки. Однако на суперпростых датасетах при обучении модели наблюдается более быстрое увеличение нормы весов, потому что градиентный спуск быстрее выталкивает веса модели в локальную точку минимума трейн лосса сильно за пределами сферы. При обучении больших моделей этот эффект не такой сильный, и веса нечасто выходят за пределы зоны Златовласки вообще, и grokking не наблюдается.
Чтобы подтвердить гипотезу об описанном происхождении гроккина, исследователи обучили несколько моделей для разных задач CV и NLP с разными нормами весов. Оказалось, что увеличение нормы весов действительно приводит к возникновению эффекта grokking’а, пусть все же и не настолько выраженно, как на более простых датасетах.
Подробнее читайте в статье
Изначально новость нашла тут
#paper
Grokking — это эффект, при котором уже после стадии переобучения модели (при возрастающем test лоссе и падаюшем train) при дальнейшем обучении test loss вдруг начинает падать, и сеть лучше генерализуется. Такой эффект наблюдали уже давно (например, вот тут), но, чаще всего, на малых, “игрушечных” датасетах (например, на такой простой задаче как сложение чисел). Никакого сильно убедительного объяснения эффекту не было (насколько я знаю), а также не удавалось повторить эффект на реальных, не игрушечных данных.
Ребята из MIT подошли ближе к пониманию природы grokking’а и даже смогли воспроизвести эффект на разных больших датасетах.
Авторы связывают эффект гроккинга с устройством поверхности лосс-функции. В недавней работе из Стенфорда было показано, что у этой поверхности существует сферическая область, в которой достигается оптимальная генерализация модели: то есть, для модели с параметрами из этой области train и test loss малы, переобучения при этом не наблюдается. Эту сферическую область ребята из Стенфорда назвали Goldilocks zone (“зона Златовласки”, показана на картинке зеленым). Так как область сферическая, она соответствует параметрам модели с определенной нормой. Внутренность это сферической области соответствует параметрам с меньшем нормой, область вне сферы — параметрам с большей нормой.
Далее: оказывается, grokking начинает проявляться, если в какой-то момент параметры сети имели большую норму (то есть, соответствовали точке поверхности вне сферы Златовласки). В этом случае параметры из этой точки быстро скатываются в точку локального минимума, которая также чаще всего находится за пределами сферы Златовласки, т.е. вне той области, где достигается оптимальная генерализация модели. Лосс на train становится малым, лосс на test остается большим: наблюдается переобучение.
Далее происходит следующее: если у модели нет никакой регуляризации (weight decay, к примеру), то на этом обучение модели заканчивается. Лосс не выходит из точки минимума, grokking не наблюдается, переобучение остается. Но если к модели применяется регуляризация, это выталкивает веса модели из локального минимума, и они начинают стремиться к зоне Златовласки. Обычно регуляризация применяется не очень сильная, поэтому проходит довольно много эпох обучения, прежде чем веса модели достигают точки внутри зоны Goldilocks и модель начинает генерализоваться. Это и объясняет эффект гроккинга: когда через достаточно долгое время после переобучения лосс на тесте вдруг падает и модель начинает лучше обобщаться.
Кстати, если у модели регуляризация довольно сильная, grokking’а тоже не будет: веса модели будут сразу быстро приходить внутрь зоны Златовласки, не задерживаясь в локальном минимуме вне сферы. Модель просто сразу достаточно хорошо генерализуется.
Теперь, почему grokking часто наблюдают на “игрушечных” датасетах, и почти никогда — на реальных. Во-первых, обычно веса любых нейросетей инициализируют значениями с довольно малой нормой, т.е. лежащими внутри зоны Златовласки. Однако на суперпростых датасетах при обучении модели наблюдается более быстрое увеличение нормы весов, потому что градиентный спуск быстрее выталкивает веса модели в локальную точку минимума трейн лосса сильно за пределами сферы. При обучении больших моделей этот эффект не такой сильный, и веса нечасто выходят за пределы зоны Златовласки вообще, и grokking не наблюдается.
Чтобы подтвердить гипотезу об описанном происхождении гроккина, исследователи обучили несколько моделей для разных задач CV и NLP с разными нормами весов. Оказалось, что увеличение нормы весов действительно приводит к возникновению эффекта grokking’а, пусть все же и не настолько выраженно, как на более простых датасетах.
Подробнее читайте в статье
Изначально новость нашла тут
🔥51👍25❤2
Вспомнила тут, как мне кто-то в DLS недавно утверждал, что париться о правильной инициализации нейросетей не надо. Мол, может, экспериментально где-то что-то “хорошая” инициализация дает, но математических доказательств улучшения работы нейросети для разных видов инициализации нет. Инициализируем не нулями, и сойдет.
Так вот, это не так) Эффект grokking и его объяснение — еще одно этому доказательство. Инициализируйте сети правильно =)
И, наверное, надо добавить в DLS занятие или хотя бы мини-конспект по инициализации весов.
Так вот, это не так) Эффект grokking и его объяснение — еще одно этому доказательство. Инициализируйте сети правильно =)
И, наверное, надо добавить в DLS занятие или хотя бы мини-конспект по инициализации весов.
👍81❤8🔥7
AlphaZero обучили находить более эффективные алгоритмы перемножения матриц
#paper
Перемножение матриц — суперски важная операция. Она используется в куче задач: сжатии/обработке картинок, рендеринге сцен в компьютерных играх, симуляциях и т.д. Ну и, разумеетя, перемножение матриц — основа всего AI =)
Поэтому хочется уметь перемножать матрицы как можно быстрее. Ускорение этой операции позволит нейросетям, симуляциям и компьютерным играм работать быстрее, требуя менее навороченное железо.
Что значит “перемножать матрицы быстрее”. Вспомним стандартный алгоритм матричного умножения, который мы изучали еще в школе: он состоит из нескольких операций умножения и сложения. Например, чтобы перемножить две матрицы размера 2х2, нужно сделать 8 операций умножения и сколько-то — сложения. Так вот, умножение чисел в компьютере занимает гораздо больше времени, чем сложение. Поэтому если удастся найти другой алгоритм, в котором для перемножения двух произвольных матриц требуется меньше операций умножения, чем в стандартном алгоритме, то это сильно ускорит умножение матриц.
Надо сказать, что для матриц размера 2х2 такой более быстрый алгоритм существует: его придумал Фолькер Штрассен в 1969 году. Он требует 7 операций умножения вместо стандартных восьми. Только вот для матриц большей размерности этот алгоритм не скейлится: они в компьютерах все еще умножаются стандартным способом.
И вот в DeepMind решили натравить нейронку на эту задачу: обучить ее находить более выгодные схемы умножения матриц произвольного размера.
Как работает модель:
Авторы представили задачу умножения матриц в виде игры. Начальное состояние игры — трехмерный тензор S произвольного размера. На каждом шаге игры игрок выбирает три произвольных тензора u, v и w, и произведение этих тензоров отнимается от S. Задача игрока — за минимальное число ходов превратить S в тензор из всех нулей.
На такую игру натравили RL-агента AlphaTensor. За его основу была взята AlphaZero — модель, которая когда-то отлично научилась играть в Го. Обучали AlphaTensor на матрицах размера <=5. В итоге для некоторых размеров матрицы S действительно удалось найти SOTA алгоритмы умножения:
- для S размера (3, 4, 5) модель нашла вариант алгоритма за 47 умножений вместо 48;
- для S размера (4, 4, 5) — 63 умножения вместо 64;
- для S размера (4, 5, 5) — 76 умножений вместо 80;
- также модель улучшила алгоритмы для перемножения некоторых матриц со значениями из поля Z_2.
Тесты найденных AlphaTensor алгоритмов перемножения матриц на реальных процессорах показывают, что они работают не хуже или даже лучше, чем SOTA алгоритмы.
Также авторы показывают, что можно научить AlphaTensor находить более быстрые варианты умножения матриц для определенной архитектуры процессора. Для этого нужно чуть модифицировать функцию reward’а модели: добавить в нее время, которое найденный моделью алгоритм требует для реализации на том или ином железе.
Ну и, напоследок, пара замечаний:
- одна из главных сложностей задачи — огромное пространство действий агента на каждом ходе (чисел так-то континуум). Поэтому в AlphaTensor факторизуют пространство действий для агента. Одно из путей развития алгоритма — сделать факторизацию обучаемой: заставить агента самому понимать, в каком множестве искать значения матриц u, v и w. Возможно, так можель сможет находить еще более оптимальные алгоритмы перемножения. Также из-за этого расширить алгоритм на матрицы большей размерности чуть сложнее.
- подобную идею перевода фундаментальной задачи в RL-игру можно применить не только к умножению матриц. Например, кажется, можно попробовать сделать то же самое для задачи разложения матриц и паре других.
Более подробно про архитектуру AlphaTensor и RL-сетап читайте в статье в Nature
Также у DeepMind есть блогпост об AlphaTensor
Новость изначально нашла тут
#paper
Перемножение матриц — суперски важная операция. Она используется в куче задач: сжатии/обработке картинок, рендеринге сцен в компьютерных играх, симуляциях и т.д. Ну и, разумеетя, перемножение матриц — основа всего AI =)
Поэтому хочется уметь перемножать матрицы как можно быстрее. Ускорение этой операции позволит нейросетям, симуляциям и компьютерным играм работать быстрее, требуя менее навороченное железо.
Что значит “перемножать матрицы быстрее”. Вспомним стандартный алгоритм матричного умножения, который мы изучали еще в школе: он состоит из нескольких операций умножения и сложения. Например, чтобы перемножить две матрицы размера 2х2, нужно сделать 8 операций умножения и сколько-то — сложения. Так вот, умножение чисел в компьютере занимает гораздо больше времени, чем сложение. Поэтому если удастся найти другой алгоритм, в котором для перемножения двух произвольных матриц требуется меньше операций умножения, чем в стандартном алгоритме, то это сильно ускорит умножение матриц.
Надо сказать, что для матриц размера 2х2 такой более быстрый алгоритм существует: его придумал Фолькер Штрассен в 1969 году. Он требует 7 операций умножения вместо стандартных восьми. Только вот для матриц большей размерности этот алгоритм не скейлится: они в компьютерах все еще умножаются стандартным способом.
И вот в DeepMind решили натравить нейронку на эту задачу: обучить ее находить более выгодные схемы умножения матриц произвольного размера.
Как работает модель:
Авторы представили задачу умножения матриц в виде игры. Начальное состояние игры — трехмерный тензор S произвольного размера. На каждом шаге игры игрок выбирает три произвольных тензора u, v и w, и произведение этих тензоров отнимается от S. Задача игрока — за минимальное число ходов превратить S в тензор из всех нулей.
На такую игру натравили RL-агента AlphaTensor. За его основу была взята AlphaZero — модель, которая когда-то отлично научилась играть в Го. Обучали AlphaTensor на матрицах размера <=5. В итоге для некоторых размеров матрицы S действительно удалось найти SOTA алгоритмы умножения:
- для S размера (3, 4, 5) модель нашла вариант алгоритма за 47 умножений вместо 48;
- для S размера (4, 4, 5) — 63 умножения вместо 64;
- для S размера (4, 5, 5) — 76 умножений вместо 80;
- также модель улучшила алгоритмы для перемножения некоторых матриц со значениями из поля Z_2.
Тесты найденных AlphaTensor алгоритмов перемножения матриц на реальных процессорах показывают, что они работают не хуже или даже лучше, чем SOTA алгоритмы.
Также авторы показывают, что можно научить AlphaTensor находить более быстрые варианты умножения матриц для определенной архитектуры процессора. Для этого нужно чуть модифицировать функцию reward’а модели: добавить в нее время, которое найденный моделью алгоритм требует для реализации на том или ином железе.
Ну и, напоследок, пара замечаний:
- одна из главных сложностей задачи — огромное пространство действий агента на каждом ходе (чисел так-то континуум). Поэтому в AlphaTensor факторизуют пространство действий для агента. Одно из путей развития алгоритма — сделать факторизацию обучаемой: заставить агента самому понимать, в каком множестве искать значения матриц u, v и w. Возможно, так можель сможет находить еще более оптимальные алгоритмы перемножения. Также из-за этого расширить алгоритм на матрицы большей размерности чуть сложнее.
- подобную идею перевода фундаментальной задачи в RL-игру можно применить не только к умножению матриц. Например, кажется, можно попробовать сделать то же самое для задачи разложения матриц и паре других.
Более подробно про архитектуру AlphaTensor и RL-сетап читайте в статье в Nature
Также у DeepMind есть блогпост об AlphaTensor
Новость изначально нашла тут
🔥57👍19😱3🤔1🙏1
А тут, наконец, вышел новый выпуск подкаста Deep Learning Stories, который мы записывали в конце августа🙃
#podcast
S01E05: AI в сейсмологии с Артемием Новоселовым
Гость выпуска — Артемий Новоселов, постдок рисерчер в Stanford University и автор канала NN for Science. В Стенфорде Артемий занимается ML в сейсмологии.
Обсудили с Артемием:
- путь Артемия в рисерче: как добраться до Стенфорда;
- что такое землетрясения и какими методами их пытаются предсказывать;
- AI в сейсмологии: как применяется сейчас, какие есть проблемы и какое видится будущее;
- немного о жизненном: о выгорании, мотивации, психологической помощи.
Ссылки на выпуск:
Yandex Music
Apple Music
Google Music
Spotify
Anchor.fm
YouTube (скоро будет, но без видео в этот раз)
—————————————
Поддержать подкаст и канал можно тут
#podcast
S01E05: AI в сейсмологии с Артемием Новоселовым
Гость выпуска — Артемий Новоселов, постдок рисерчер в Stanford University и автор канала NN for Science. В Стенфорде Артемий занимается ML в сейсмологии.
Обсудили с Артемием:
- путь Артемия в рисерче: как добраться до Стенфорда;
- что такое землетрясения и какими методами их пытаются предсказывать;
- AI в сейсмологии: как применяется сейчас, какие есть проблемы и какое видится будущее;
- немного о жизненном: о выгорании, мотивации, психологической помощи.
Ссылки на выпуск:
Yandex Music
Apple Music
Google Music
Spotify
Anchor.fm
YouTube (скоро будет, но без видео в этот раз)
—————————————
Поддержать подкаст и канал можно тут
🔥30👍3❤1💩1
Центр когнитивного моделирования МФТИ открывает набор на оплачиваемую стажировку в области AI
На выбор есть несколько направлений:
- Embodied AI;
- CV;
- RL;
- Беспилотники и робототехника.
Обещают работу в команде опытных рисерчеров, возможность работать как над прикладными, так и над фундаментальными задачами, а также написание статей в ведущие конференции и журналы.
Важно: стажировку можно совмещать с написанием бакалаврского или магистерского диплома. Даже если вы учитесь не в МФТИ, часто можно найти научрука и лабу для написания диплома в другом ВУЗе. Я сама так делала в магистратуре.
Прием заявок до 1 ноября. Чтобы податься на стажировку, заполните эту анкету.
Подробнее о Центре Когнитивного Моделирования МФТИ, темах их исследований и стажировках можно почитать тут.
На выбор есть несколько направлений:
- Embodied AI;
- CV;
- RL;
- Беспилотники и робототехника.
Обещают работу в команде опытных рисерчеров, возможность работать как над прикладными, так и над фундаментальными задачами, а также написание статей в ведущие конференции и журналы.
Важно: стажировку можно совмещать с написанием бакалаврского или магистерского диплома. Даже если вы учитесь не в МФТИ, часто можно найти научрука и лабу для написания диплома в другом ВУЗе. Я сама так делала в магистратуре.
Прием заявок до 1 ноября. Чтобы податься на стажировку, заполните эту анкету.
Подробнее о Центре Когнитивного Моделирования МФТИ, темах их исследований и стажировках можно почитать тут.
🔥27👍3🤮2🤯1💩1🤡1
Очень классная работа: редактирование отдельных частей изображения, сгенерированного диффузией.
#paper
Диффузии (DALL-E 2, Imagen, Stable Diffusion) очень классно генерируют картинки. Но управлять структурой этих картинок мы не очень умеем: малейшее изменение во входном тексте может поменять картинку целиком. Контроль структуры и семантики изображения (форм, цветов, частей объектов) — важная, и пока нерешенная задача. До сих пор решить ее пытались в основном с помощью создания сегментационных масок, которые подаются на вход диффузии вместе с текстом. Пример такого подхода — модель Make-A-Scene, о ней я писала тут.
Авторы из Стенфорда и университета Тель-Авива пошли глубже: они исследовали, где кроется связь между словами текста и структурой сгенерированной картинки, и придумали, как сохранять структуру картинки при изменении слов входного текста, не используя никаких масок сегментации.
Примеры работы модели — на картинке к посту.
Кратко, идея работы такая: оказывается, структура генерируемого изображения целиком определяется одной из матриц M слоя cross-attention. Используя ту же матрицу M при генерации с измененным текстовым запросом, можно "зафиксировать" структуру изображения. Но при этом семантические детили картинки будут изменены согласно изменению текста запроса. То есть, при переходе “A cat riding on a bicycle” -> “A cat riding on a car” вместо велосипеда действительно появится машина, а все остальные детали останутся неизменными.
Подробно о том, как алгоритм работает, и где же кроется связь между текстом и структурой изображения, я написала статью в telegraph.
📃Статья
🛠Код на GitHub
#paper
Диффузии (DALL-E 2, Imagen, Stable Diffusion) очень классно генерируют картинки. Но управлять структурой этих картинок мы не очень умеем: малейшее изменение во входном тексте может поменять картинку целиком. Контроль структуры и семантики изображения (форм, цветов, частей объектов) — важная, и пока нерешенная задача. До сих пор решить ее пытались в основном с помощью создания сегментационных масок, которые подаются на вход диффузии вместе с текстом. Пример такого подхода — модель Make-A-Scene, о ней я писала тут.
Авторы из Стенфорда и университета Тель-Авива пошли глубже: они исследовали, где кроется связь между словами текста и структурой сгенерированной картинки, и придумали, как сохранять структуру картинки при изменении слов входного текста, не используя никаких масок сегментации.
Примеры работы модели — на картинке к посту.
Кратко, идея работы такая: оказывается, структура генерируемого изображения целиком определяется одной из матриц M слоя cross-attention. Используя ту же матрицу M при генерации с измененным текстовым запросом, можно "зафиксировать" структуру изображения. Но при этом семантические детили картинки будут изменены согласно изменению текста запроса. То есть, при переходе “A cat riding on a bicycle” -> “A cat riding on a car” вместо велосипеда действительно появится машина, а все остальные детали останутся неизменными.
Подробно о том, как алгоритм работает, и где же кроется связь между текстом и структурой изображения, я написала статью в telegraph.
📃Статья
🛠Код на GitHub
👍34🔥21❤3💩1
This media is not supported in your browser
VIEW IN TELEGRAM
#промо
На что первым делом падает взгляд, когда вы заходите на сайт? На удобство расположения кнопок и интуитивно понятный интерфейс? Если сайт сделан круто, то вы не заметите никаких швов. Именно этим и занимается UX/UI-дизайнер: делает digital-мир удобнее. А работать такой специалист может из любой точки мира.
Сегодня каждая компания создает свой сайт или мобильное приложение, поэтому UX/UI-дизайнеры пользуются спросом. А еще профессия популярна в сфере IT, при этом UX/UI-дизайнерам не нужно уметь программировать.
Учиться на UX/UI-дизайнера лучше там, где дадут хороший старт.
На курсе в онлайн-школе дизайна CONTENTED студенты получают более 200 часов практики и 12 проектов в портфолио. Во время обучения вас ждет онлайн-практика в креативном агентстве REDKEDS или в IT-компании OZON под руководством арт-директора.
Приглашаем к нам учиться!
Узнать подробнее, посмотреть программу и подать заявку можно на сайте.
Там же вы можете получить еще более детальное описание обучения и бесплатную консультацию специалиста, чтобы не оставалось вопросов по программе.
А читателям канала DLStories скидка 45% до 25 октября по промокоду dl_stories!
Приходи ⬇️
Онлайн-школа дизайна Contented
На что первым делом падает взгляд, когда вы заходите на сайт? На удобство расположения кнопок и интуитивно понятный интерфейс? Если сайт сделан круто, то вы не заметите никаких швов. Именно этим и занимается UX/UI-дизайнер: делает digital-мир удобнее. А работать такой специалист может из любой точки мира.
Сегодня каждая компания создает свой сайт или мобильное приложение, поэтому UX/UI-дизайнеры пользуются спросом. А еще профессия популярна в сфере IT, при этом UX/UI-дизайнерам не нужно уметь программировать.
Учиться на UX/UI-дизайнера лучше там, где дадут хороший старт.
На курсе в онлайн-школе дизайна CONTENTED студенты получают более 200 часов практики и 12 проектов в портфолио. Во время обучения вас ждет онлайн-практика в креативном агентстве REDKEDS или в IT-компании OZON под руководством арт-директора.
Приглашаем к нам учиться!
Узнать подробнее, посмотреть программу и подать заявку можно на сайте.
Там же вы можете получить еще более детальное описание обучения и бесплатную консультацию специалиста, чтобы не оставалось вопросов по программе.
А читателям канала DLStories скидка 45% до 25 октября по промокоду dl_stories!
Приходи ⬇️
Онлайн-школа дизайна Contented
🤮14👍7🔥4❤1
Через буквально день после предыдущего поста скинули еще более новую статью про контролируемое изменение семантики картинок с помощью диффузионных моделей. И в этой работе можно изменять детали любых изображений, а не только тех, что предварительно были сгенерированны моделью.
#paper
Imagic: text-based редактирование изображений с помощью диффузионной модели.
Как это работает:
Берем предобученную диффузионную модель. Например, Imagen: авторы использовали именно его.
Также берем любую картинку, которую хотим изменить, и придумываем к ней описание, которое будет соответствовать уже новой картинке. Например, если мы хотим из картинки белой машины сделать черную, таргет текст может быть таким: “black sports car”.
И делаем следующее:
1. Прогоняем target text через text encoder, получаем эмбеддинг e_tgt. Далее делаем пару итераций тюнинга этого эмбеддинга: меняем его так, чтобы картинка, которую выдает диффузионная модель на этому эмбеддингу, получалась как можно более похожей на картинку, которую мы хотим поменять (на картинку белой машины). Это делается обычным backprop. Диффузионная модель при этом не обучается. Назовем полученный эмбеддинг на этом шаге e_opt.
2. Теперь замораживаем эмбеддинг текста и еще пару итераций дообучаем диффузию. Цель та же: чтобы диффузия выдавала по этому эмбеддингу картинку, более похожую на нашу картинку, которую мы хотим изменять.
3. Последний шаг. Берем e_opt и e_tgt, и интерполируем: e = alpha*e_opt + (1-alpha)*e_tgt. Результат e прогоняем через дообученную диффузию. Вуаля, получаем на выходе картинку. Ее основные детали остались теми же, что были на изначальной картинке, но некоторые детали поменялись в соответствии с target text.
Для разных alpha результат получится разным: для маленьких alpha картинка будет практически идентична изначальной, для alpha ~1 картинка получится абсолютно новой, не имеющей ничего общего с изначальной. Для промежуточных значений alpha будет получаться то, что нам нужно: все детали, кроме тех, что мы хотим поменять, будут сохранены (ну, почти сохранены, об этом ниже). Пример получаемых картинок для разных alpha — на второй картинке к посту.
Идея работы модели, конечно, крутая: так просто позволяет изменять вообще любые изображения. Но у алгоритма есть ограничения:
- Модель работает с довольно low-resolution картинками. Потому что иначе на 1-2 шагах алгоритма просто не выйдет подобрать эмбеддинг и веса модели так, чтобы на выходе диффузии получалась картинка, прям похожая на нужную. Получаемые low-resolution картинки потом прогоняются через super-resolution сети (как это и было у Imagen, собственно).
- Таким алгоритмом, очевидно, не выйдет добиться того, чтобы на получаемой картинке все детали, которые мы не хотели менять, в точности сохранялись такими, каким были на изначальной картинке. Вообще все детали чуть меняются: это видно на примерах работы модели (1 картинка к посту). Например, стена и окно дома за человеком со скрещенными руками чуть разные на изначальной и полученной картинке.
Изменения затрагивают все детали в основном из-за того, что на первом шаге алгоритма измененяется e_tgt. Именно поэтому первый шаг делается очень малое количество итераций, чтобы e_opt был как можно ближе к e_tgt, но все же содержал каку-то информацию из target text’а.
- Из второго пункта очевидно следует, что этим алгоритмом не получится делать сложные изменения деталей. Действительно, чтобы сделать солжные изменения, нужно сильно изменить e_tgt. Но тогда сильнее изменятся и остальные детали изображения, чего мы не хотим.
Больше примеров работы модели — на третьей картинке к посту.
📃 Статья
#paper
Imagic: text-based редактирование изображений с помощью диффузионной модели.
Как это работает:
Берем предобученную диффузионную модель. Например, Imagen: авторы использовали именно его.
Также берем любую картинку, которую хотим изменить, и придумываем к ней описание, которое будет соответствовать уже новой картинке. Например, если мы хотим из картинки белой машины сделать черную, таргет текст может быть таким: “black sports car”.
И делаем следующее:
1. Прогоняем target text через text encoder, получаем эмбеддинг e_tgt. Далее делаем пару итераций тюнинга этого эмбеддинга: меняем его так, чтобы картинка, которую выдает диффузионная модель на этому эмбеддингу, получалась как можно более похожей на картинку, которую мы хотим поменять (на картинку белой машины). Это делается обычным backprop. Диффузионная модель при этом не обучается. Назовем полученный эмбеддинг на этом шаге e_opt.
2. Теперь замораживаем эмбеддинг текста и еще пару итераций дообучаем диффузию. Цель та же: чтобы диффузия выдавала по этому эмбеддингу картинку, более похожую на нашу картинку, которую мы хотим изменять.
3. Последний шаг. Берем e_opt и e_tgt, и интерполируем: e = alpha*e_opt + (1-alpha)*e_tgt. Результат e прогоняем через дообученную диффузию. Вуаля, получаем на выходе картинку. Ее основные детали остались теми же, что были на изначальной картинке, но некоторые детали поменялись в соответствии с target text.
Для разных alpha результат получится разным: для маленьких alpha картинка будет практически идентична изначальной, для alpha ~1 картинка получится абсолютно новой, не имеющей ничего общего с изначальной. Для промежуточных значений alpha будет получаться то, что нам нужно: все детали, кроме тех, что мы хотим поменять, будут сохранены (ну, почти сохранены, об этом ниже). Пример получаемых картинок для разных alpha — на второй картинке к посту.
Идея работы модели, конечно, крутая: так просто позволяет изменять вообще любые изображения. Но у алгоритма есть ограничения:
- Модель работает с довольно low-resolution картинками. Потому что иначе на 1-2 шагах алгоритма просто не выйдет подобрать эмбеддинг и веса модели так, чтобы на выходе диффузии получалась картинка, прям похожая на нужную. Получаемые low-resolution картинки потом прогоняются через super-resolution сети (как это и было у Imagen, собственно).
- Таким алгоритмом, очевидно, не выйдет добиться того, чтобы на получаемой картинке все детали, которые мы не хотели менять, в точности сохранялись такими, каким были на изначальной картинке. Вообще все детали чуть меняются: это видно на примерах работы модели (1 картинка к посту). Например, стена и окно дома за человеком со скрещенными руками чуть разные на изначальной и полученной картинке.
Изменения затрагивают все детали в основном из-за того, что на первом шаге алгоритма измененяется e_tgt. Именно поэтому первый шаг делается очень малое количество итераций, чтобы e_opt был как можно ближе к e_tgt, но все же содержал каку-то информацию из target text’а.
- Из второго пункта очевидно следует, что этим алгоритмом не получится делать сложные изменения деталей. Действительно, чтобы сделать солжные изменения, нужно сильно изменить e_tgt. Но тогда сильнее изменятся и остальные детали изображения, чего мы не хотим.
Больше примеров работы модели — на третьей картинке к посту.
📃 Статья
👍22🔥11❤4🤮1
На основе GPT-3 придумали очередную тулзу. Explainapaper: объяснятор научных статей
Загружаете статью, выделяете какую-то ее часть (например, ту, которую не понимаете), и GPT-3 переводит сложный заумный текст в лакончиную простую форму (т.е. решает задачу text summarization). Пример — на картинке к посту. Далее у GPT-3 можно спрашивать уточняющие вопросы по тексту, и модель постарается ответить.
Кажется, это действительно работает: текст получился верным и простым для понимания. Для уверенности нужно еще потестить, конечно.
Интересно наблюдать за тем, как после релиза инструмента снова пошли разговоры о том, как нейронки кого-то заменят и как представители некоторых профессий “наверное, напряглись” =)
В связи с этим, скажите: как вам кажется, полезная штука? Пользовались бы?
Мне кажется, людям, которые работают в науке и читают статьи по теме своих исследований, такая штука не нужна. Но если приходится читать текст не по своей специализации, может быть полезно: там могут встречаться термины и рассуждения, непонятные человеку вне области. И саммари простым языком значительно упростит понимание. Плюс, возможно, это будет полезно научпоп-жерналистам: часто они не очень глубоко разбираются в теме, на которые пишут статьи, а научные работы в процессе написания материала разбирать приходится.
Загружаете статью, выделяете какую-то ее часть (например, ту, которую не понимаете), и GPT-3 переводит сложный заумный текст в лакончиную простую форму (т.е. решает задачу text summarization). Пример — на картинке к посту. Далее у GPT-3 можно спрашивать уточняющие вопросы по тексту, и модель постарается ответить.
Кажется, это действительно работает: текст получился верным и простым для понимания. Для уверенности нужно еще потестить, конечно.
Интересно наблюдать за тем, как после релиза инструмента снова пошли разговоры о том, как нейронки кого-то заменят и как представители некоторых профессий “наверное, напряглись” =)
В связи с этим, скажите: как вам кажется, полезная штука? Пользовались бы?
Мне кажется, людям, которые работают в науке и читают статьи по теме своих исследований, такая штука не нужна. Но если приходится читать текст не по своей специализации, может быть полезно: там могут встречаться термины и рассуждения, непонятные человеку вне области. И саммари простым языком значительно упростит понимание. Плюс, возможно, это будет полезно научпоп-жерналистам: часто они не очень глубоко разбираются в теме, на которые пишут статьи, а научные работы в процессе написания материала разбирать приходится.
👍69❤🔥16❤3🔥1😁1