
Как и зачем мы сделали свой мониторинг гипервизоров для виртуальных машин
В этой статье рассказано кастомном мониторинге гипервизоров: как его сделали, как он работает и какую пользу приносит. Решение выполнено для Openstack на базе Prometheus/Alertmanager/Grafana. Читать статью.
В этой статье рассказано кастомном мониторинге гипервизоров: как его сделали, как он работает и какую пользу приносит. Решение выполнено для Openstack на базе Prometheus/Alertmanager/Grafana. Читать статью.
{kind=link}
👍4
Alerting: The Do’s and Don’ts for Effective Observability
Статья об эффективном подходе к алертингу. Читать статью.
Статья об эффективном подходе к алертингу. Читать статью.
❤1👍1
👍4
Prometheus Now Supports OpenTelemetry Metrics
Prometheus уже долгое время является основным средством мониторинга Kubernetes и облачных систем. Prometheus предоставляет полный стек, включая сбор метрик, а также бэкенд, включающий базу данных с временными рядами для хранения метрик, пользовательский интерфейс, AlertManager и многое другое.
Затем появился OpenTelemetry, который предлагает унифицированный способ сбора телеметрии наблюдаемости, включая трассировки, журналы и метрики. OpenTelemetry — самый активный проект в CNCF после Kubernetes, и он быстро становится стандартом сбора данных о наблюдаемости.
Но как сочетаются эти два чрезвычайно популярных проекта?
Если люди начинают собирать метрики с помощью OpenTelemetry, смогут ли они продолжать использовать Prometheus в качестве бэкенда для сбора метрик? Ответ на вопрос в статье.
❗️Статья на Медиум, возможно, нужен VPN.
Prometheus уже долгое время является основным средством мониторинга Kubernetes и облачных систем. Prometheus предоставляет полный стек, включая сбор метрик, а также бэкенд, включающий базу данных с временными рядами для хранения метрик, пользовательский интерфейс, AlertManager и многое другое.
Затем появился OpenTelemetry, который предлагает унифицированный способ сбора телеметрии наблюдаемости, включая трассировки, журналы и метрики. OpenTelemetry — самый активный проект в CNCF после Kubernetes, и он быстро становится стандартом сбора данных о наблюдаемости.
Но как сочетаются эти два чрезвычайно популярных проекта?
Если люди начинают собирать метрики с помощью OpenTelemetry, смогут ли они продолжать использовать Prometheus в качестве бэкенда для сбора метрик? Ответ на вопрос в статье.
❗️Статья на Медиум, возможно, нужен VPN.
{kind=link}
👍4
Preparing your logging stack for a 10x scale using ELK & Kafka on Kubernetes
Urban Company рассказывает о собственном опыте скалирования инфраструктуры логирования. Читать статью.
Urban Company рассказывает о собственном опыте скалирования инфраструктуры логирования. Читать статью.
{kind=link}
👍3❤1
Deploying Prometheus and Grafana monitoring stack to Kubernetes the GitOps way using ArgoCD
Деплой мониторинга K8S при помощи ArgoCD. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
Деплой мониторинга K8S при помощи ArgoCD. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
{kind=link}
👍2
Zabbix + OpenStack
Zabbix представил шаблон для мониторинга OpenStack для версии 6.4. Посмотреть шаблон.
Zabbix представил шаблон для мониторинга OpenStack для версии 6.4. Посмотреть шаблон.
👍6👎1🤔1
What is My SLO and How do I Test It?
В этой статье рассказано как при помощи K6 определить SLO для ряда эндпоинтов демонстрационного сервиса K6 и как написать повторяющиеся тесты производительности этих SLO, чтобы следить за работой сервиса. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
В этой статье рассказано как при помощи K6 определить SLO для ряда эндпоинтов демонстрационного сервиса K6 и как написать повторяющиеся тесты производительности этих SLO, чтобы следить за работой сервиса. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
{kind=link}
How to Calculate Reliability and High Availability in SRE!
В этой статье раскрываются технические детали реализации понятий SLO, SLI, SLA и показано, как создавать собственные дашборды, отвечающие специфическим потребностям. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
В этой статье раскрываются технические детали реализации понятий SLO, SLI, SLA и показано, как создавать собственные дашборды, отвечающие специфическим потребностям. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
{kind=link}
👍2
Python Profiling — Why and Where Your Code is Slow
Сказ о профайлерах, которые помогут выявить недостатки кода на Python. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
Сказ о профайлерах, которые помогут выявить недостатки кода на Python. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
{kind=link}
👍2❤1
Best Practices for Monitoring and Improving Kafka Performance
Несколько советов по улучшению производительности и мониторингу Kafka. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
Несколько советов по улучшению производительности и мониторингу Kafka. Читать статью.
❗️Статья на Медиум, возможно, нужен VPN.
{kind=link}
🔥2
How to find unused Prometheus metrics using mimirtool
В этой статье рассказано, как с помощью mimirtool определить, какие метрики используются на платформе, а какие нет. Читать статью.
Prometheus performance and cardinality in practice
В этой статье рассказано об оптимизации производительности Prometheus. Читать статью.
В этой статье рассказано, как с помощью mimirtool определить, какие метрики используются на платформе, а какие нет. Читать статью.
Prometheus performance and cardinality in practice
В этой статье рассказано об оптимизации производительности Prometheus. Читать статью.
{kind=link}
👍5
teletrace
Teletrace — это распределенная система трассировки с открытым исходным кодом, которая помогает разработчикам контролировать и устранять неполадки в сложных распределенных системах, обеспечивая сквозной мониторинг и трассировку транзакций в различных микросервисах. Teletrace опирается OpenTelemetry.
Репыч на Гитхабе.
Teletrace — это распределенная система трассировки с открытым исходным кодом, которая помогает разработчикам контролировать и устранять неполадки в сложных распределенных системах, обеспечивая сквозной мониторинг и трассировку транзакций в различных микросервисах. Teletrace опирается OpenTelemetry.
Репыч на Гитхабе.
{kind=link}
🔥5
Приемы логирования в Kubernetes
В этой статье на Хабре описаны приемы логирования Kubernetes и практики работы с логами. Читать статью.
В этой статье на Хабре описаны приемы логирования Kubernetes и практики работы с логами. Читать статью.
👍6
Grafana Tempo 2.2 release: TraceQL structural operators are here!
Главной фишкой нового релиза, безусловно, являются структурные операторы. Структурные операторы позволяют пользователю очень четко и лаконично искать сложные структурные условия в трассировках вызовов. Подробности в статье в блоге Grafana.
Главной фишкой нового релиза, безусловно, являются структурные операторы. Структурные операторы позволяют пользователю очень четко и лаконично искать сложные структурные условия в трассировках вызовов. Подробности в статье в блоге Grafana.
{kind=link}
👍6
Сага в двух частях:
Наблюдаемость сетевой инфраструктуры Kubernetes. Часть первая
В этой статье рассмотрены инструменты наблюдения за сетевой инфраструктурой Kubernetes и основные составляющие Observability/Наблюдаемости – мониторинг, журналы событий, метрики, распределенная трассировка и оповещения.
Наблюдаемость сетевой инфраструктуры Kubernetes. Часть вторая
В этой статье разобраны инструменты, базирующиеся на ранее озвученных подходах (Service Mesh, eBPF monitoring и Distributed Tracing). Для сравнения решений будет выбран единый сценарий, при развёртывании которого собираются метрики приложения и кластера k8s.
Наблюдаемость сетевой инфраструктуры Kubernetes. Часть первая
В этой статье рассмотрены инструменты наблюдения за сетевой инфраструктурой Kubernetes и основные составляющие Observability/Наблюдаемости – мониторинг, журналы событий, метрики, распределенная трассировка и оповещения.
Наблюдаемость сетевой инфраструктуры Kubernetes. Часть вторая
В этой статье разобраны инструменты, базирующиеся на ранее озвученных подходах (Service Mesh, eBPF monitoring и Distributed Tracing). Для сравнения решений будет выбран единый сценарий, при развёртывании которого собираются метрики приложения и кластера k8s.
{kind=link}
👍3🔥2
What's new in distributed trace visualization in Grafana
В этой рассказано о нескольких усовершенствованиях, которые были недавно внесены в Grafana и которые направлены на облегчение поиска нужной информации и отсеивание ненужной. Читать статью.
В этой рассказано о нескольких усовершенствованиях, которые были недавно внесены в Grafana и которые направлены на облегчение поиска нужной информации и отсеивание ненужной. Читать статью.
{kind=link}
Мониторинг Postgres по USE и RED
Есть две методологии перформанс мониторинга: USE (Utilization, Saturation, Errors) Брендана Грегга и RED (Requests, Errors, Durations) от Тома Уилки. В этой статье (она же расшифровка доклада Павла Труханова из Okmeter с PGConf.Russia) рассказано о том, как ориентироваться на эти методологии при реализации мониторинга Postgres. Читать статью.
Есть две методологии перформанс мониторинга: USE (Utilization, Saturation, Errors) Брендана Грегга и RED (Requests, Errors, Durations) от Тома Уилки. В этой статье (она же расшифровка доклада Павла Труханова из Okmeter с PGConf.Russia) рассказано о том, как ориентироваться на эти методологии при реализации мониторинга Postgres. Читать статью.
{kind=link}
👍9
openobserve
OpenObserve — это платформа наблюдаемости, созданная специально для работы с логами, метриками, трассировками и аналитикой в петабайтных масштабах.
Она очень проста и удобна в эксплуатации, в отличие от Elasticsearch. Использование OpenObserve позволяет сократить расходы на хранение логов в ~140 раз по сравнению с Elasticsearch.
Репыч на Гитхабе.
OpenObserve — это платформа наблюдаемости, созданная специально для работы с логами, метриками, трассировками и аналитикой в петабайтных масштабах.
Она очень проста и удобна в эксплуатации, в отличие от Elasticsearch. Использование OpenObserve позволяет сократить расходы на хранение логов в ~140 раз по сравнению с Elasticsearch.
Репыч на Гитхабе.
{kind=link}
👎2
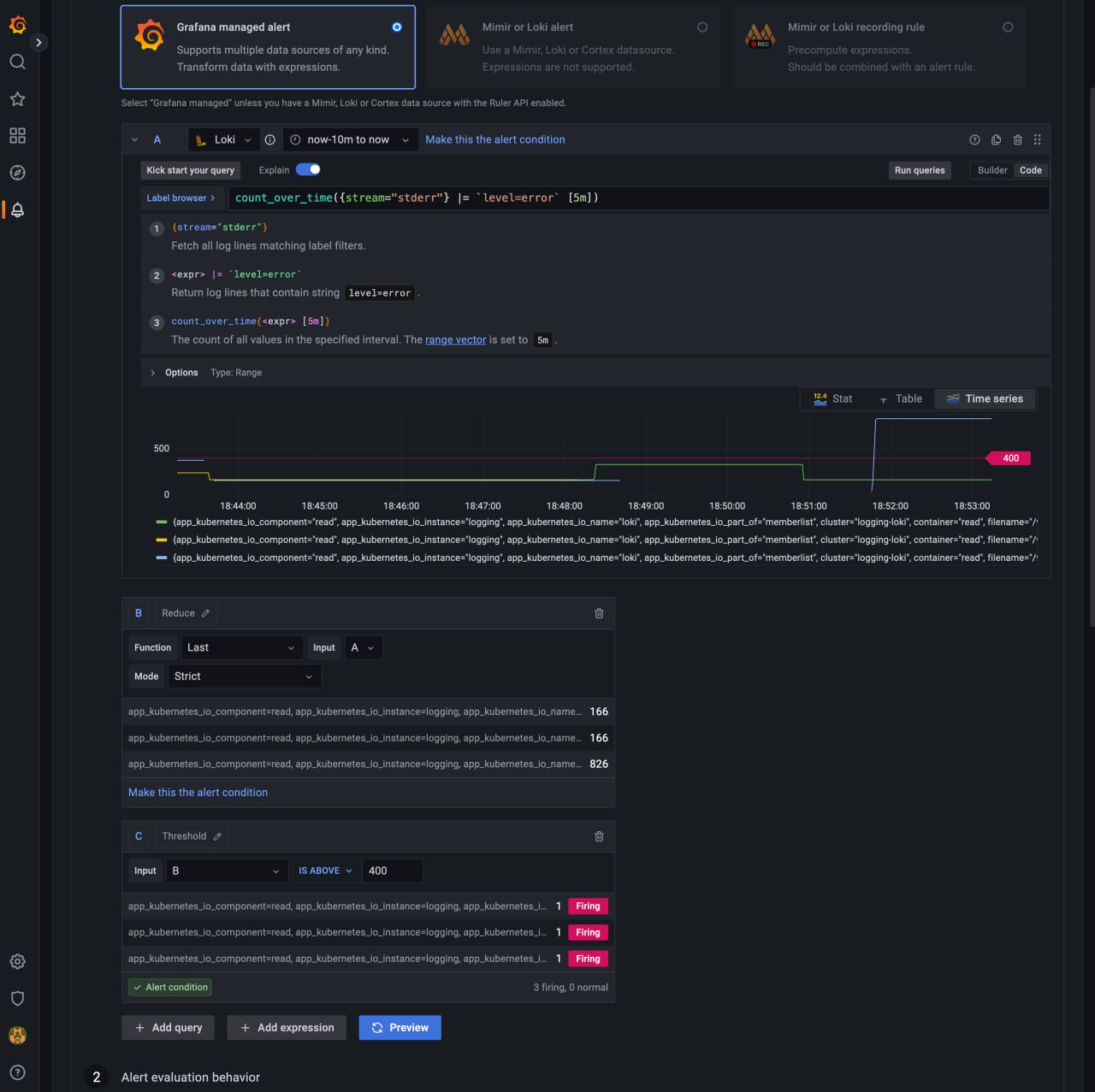
How to collect and query Kubernetes logs with Grafana Loki, Grafana, and Grafana Agent
В этой статье в блоге Grafana рассказано как можно централизовать сбор и анализ логов K8S при помощи Grafana Loki. Читать статью.
В этой статье в блоге Grafana рассказано как можно централизовать сбор и анализ логов K8S при помощи Grafana Loki. Читать статью.
{kind=link}
👍8