
rezolus
Rezolus — это агент для сбора телеметрии производительности Linux, который собирает подробную информацию о поведении системы с помощью инструментария eBPF. Собранные метрики отправляются напрямую в Prometheus.
Репыч на Гитхабе
Документация со списком собираемых метрик
Rezolus — это агент для сбора телеметрии производительности Linux, который собирает подробную информацию о поведении системы с помощью инструментария eBPF. Собранные метрики отправляются напрямую в Prometheus.
Репыч на Гитхабе
Документация со списком собираемых метрик
VictoriaMetrics Components: Getting Started
В этой статье в блоге VictoriaMetrics рассказывается об основных компонентах VictoriaMetrics и объясняется, как они работают вместе как часть комплексной системы мониторинга.
В этой статье в блоге VictoriaMetrics рассказывается об основных компонентах VictoriaMetrics и объясняется, как они работают вместе как часть комплексной системы мониторинга.
{kind=link}
Anomaly Detection in Time Series Using Statistical Analysis
Иногда простое пороговое значение работает отлично — например, мониторинг дискового пространства на сервере. Можно просто установить оповещение при оставшихся 10%, и все будет в порядке. То же самое касается отслеживания доступной памяти на сервере.
Но что, если нужно отслеживать что-то вроде поведения пользователей на веб-сайте? Представьте себе, что вы управляете интернет-магазином, где продаете товары. Один из подходов может заключаться в том, чтобы установить минимальный порог для ежедневных продаж и проверять его раз в день. Но что, если что-то пойдет не так, и нужно будет обнаружить проблему гораздо раньше — в течение нескольких часов или даже минут? В этом случае статический порог не справится, потому что активность пользователей колеблется в течение дня. Вот тут-то и вступает в дело обнаружение аномалий. Читать дальше в статье.
❗️Статья на medium.com
Иногда простое пороговое значение работает отлично — например, мониторинг дискового пространства на сервере. Можно просто установить оповещение при оставшихся 10%, и все будет в порядке. То же самое касается отслеживания доступной памяти на сервере.
Но что, если нужно отслеживать что-то вроде поведения пользователей на веб-сайте? Представьте себе, что вы управляете интернет-магазином, где продаете товары. Один из подходов может заключаться в том, чтобы установить минимальный порог для ежедневных продаж и проверять его раз в день. Но что, если что-то пойдет не так, и нужно будет обнаружить проблему гораздо раньше — в течение нескольких часов или даже минут? В этом случае статический порог не справится, потому что активность пользователей колеблется в течение дня. Вот тут-то и вступает в дело обнаружение аномалий. Читать дальше в статье.
❗️Статья на medium.com
{kind=link}
Introducing OpenTelemetry eBPF Instrumentation: Why we donated Grafana Beyla to OpenTelemetry
Около шести месяцев назад в Grafana Labs начался путь проекта Beyla — инструмента инструментирования с открытым исходным кодом на основе eBPF, не требующего написания кода — совместно с проектом OpenTelemetry. Grafana Labs контрибьютит код Beyla в OpenTelemetry под новым названием проекта OpenTelemetry eBPF Instrumentation.
В этой статье команда Grafana Labs рассказывает почему они передают свой проект Beyla в OpenTelemetry.
Около шести месяцев назад в Grafana Labs начался путь проекта Beyla — инструмента инструментирования с открытым исходным кодом на основе eBPF, не требующего написания кода — совместно с проектом OpenTelemetry. Grafana Labs контрибьютит код Beyla в OpenTelemetry под новым названием проекта OpenTelemetry eBPF Instrumentation.
В этой статье команда Grafana Labs рассказывает почему они передают свой проект Beyla в OpenTelemetry.
{kind=link}
Отправка label в систему логирования и мониторинга из метаданных GitLab Runner (job_id, pipeline_id)
При использовании GitLab CI/CD с Kubernetes возникает необходимость видеть связку между логами и конкретными CI job'ами или pipeline'ами. Это особенно полезно для отладки и мониторинга. Однако по умолчанию логи из подов не содержат этих связующих метаданных.
В статье показано, как можно передавать метки job_id, pipeline_id, project_name и другие из GitLab Runner в систему логирования VictoriaLogs с помощью Promtail и систему мониторинга VictoriaMetrics.
При использовании GitLab CI/CD с Kubernetes возникает необходимость видеть связку между логами и конкретными CI job'ами или pipeline'ами. Это особенно полезно для отладки и мониторинга. Однако по умолчанию логи из подов не содержат этих связующих метаданных.
В статье показано, как можно передавать метки job_id, pipeline_id, project_name и другие из GitLab Runner в систему логирования VictoriaLogs с помощью Promtail и систему мониторинга VictoriaMetrics.
{kind=link}
How We Migrated Terabytes of Metrics from InfluxDB to Grafana Mimir: A Complete Observability Overhaul
«К нам обратилась ведущая коммуникационная компания, которая хотела обновить свой устаревший стек наблюдаемости. Их существующая система была построена на InfluxDB v1, стеке TICK и Grafana 8, который подошел к окончанию поддержки, что создавало риски для надежности и долгосрочного обслуживания. Им нужна была современная, масштабируемая и экономически эффективная альтернатива — та, которая могла бы поддерживать многопользовательскую среду и эффективно обрабатывать годы исторических данных. После оценки нескольких вариантов они определили Grafana Mimir как идеальный выбор». Читать дальше.
«К нам обратилась ведущая коммуникационная компания, которая хотела обновить свой устаревший стек наблюдаемости. Их существующая система была построена на InfluxDB v1, стеке TICK и Grafana 8, который подошел к окончанию поддержки, что создавало риски для надежности и долгосрочного обслуживания. Им нужна была современная, масштабируемая и экономически эффективная альтернатива — та, которая могла бы поддерживать многопользовательскую среду и эффективно обрабатывать годы исторических данных. После оценки нескольких вариантов они определили Grafana Mimir как идеальный выбор». Читать дальше.
{kind=link}
Удаление бакетов в S3: что стоит учесть?
Объектное хранилище S3 — надёжный способ работать с большими объёмами данных. 27 мая проведем митап для тех, кто хочет точно понимать, как устроены ключевые процессы S3 — от настройки версионирования до безопасного удаления бакетов.
В формате демо разберём
🔹 настройку версионирования, multipart-загрузок и lifecycle-политик
🔹 автоматизацию очистки бакета (включая delete marker и незавершённые multipart-загрузки)
🔹 как подготовить бакет к удалению
🔹 настройку политик доступа, временных ссылок и шифрование на стороне сервера SSE
Спикер
Евгения Тарашкевич, инженер K2 Cloud
Формат
Онлайн-митап
Ждем администраторов, девопсов, системных архитекторов и всех, кто работает с S3.
Зарегистрироваться>>
Объектное хранилище S3 — надёжный способ работать с большими объёмами данных. 27 мая проведем митап для тех, кто хочет точно понимать, как устроены ключевые процессы S3 — от настройки версионирования до безопасного удаления бакетов.
В формате демо разберём
🔹 настройку версионирования, multipart-загрузок и lifecycle-политик
🔹 автоматизацию очистки бакета (включая delete marker и незавершённые multipart-загрузки)
🔹 как подготовить бакет к удалению
🔹 настройку политик доступа, временных ссылок и шифрование на стороне сервера SSE
Спикер
Евгения Тарашкевич, инженер K2 Cloud
Формат
Онлайн-митап
Ждем администраторов, девопсов, системных архитекторов и всех, кто работает с S3.
Зарегистрироваться>>
Анализируем сетевой трафик средних и крупных сетей с помощью Netflow/IPFIX/sFlow и боремся с DoS/DDoS с помощью BGP
xenoeye — open source xFlow-коллектор и анализатор. Анализатор собирает xFlow (Netflow и некоторые родственные протоколы типа Jflow, IPFIX, sFlow), распределяет их по объектам мониторинга, экспортирует информацию в СУБД (в текущей версии PostgreSQL), и может быстро реагировать на всплески трафика выше порогов для детекции DoS/DDoS атак с помощью скользящих средних.
Статья с описанием решения на Хабре
Репыч на Гитхабе
xenoeye — open source xFlow-коллектор и анализатор. Анализатор собирает xFlow (Netflow и некоторые родственные протоколы типа Jflow, IPFIX, sFlow), распределяет их по объектам мониторинга, экспортирует информацию в СУБД (в текущей версии PostgreSQL), и может быстро реагировать на всплески трафика выше порогов для детекции DoS/DDoS атак с помощью скользящих средних.
Статья с описанием решения на Хабре
Репыч на Гитхабе
Исследование состояния DevOps в России 2025
Дорогие друзья, мы рады сообщить, что «Экспресс 42» при поддержке генеральных партнеров запустила ежегодное исследование состояния DevOps 2025! Мы планируем опросить больше 4000 представителей индустрии, связанных с DevOps: инженеров, разработчиков, администраторов, тестировщиков, техлидов и тимлидов, CIO и CTO.
Если тема DevOps вам не безразлична — пройдите опрос и внесите свой вклад в развитие индустрии. Важно мнение каждого респондента!
📊 Ключевой темой исследования в 2025 году становится Developer Experience (DX) — то, насколько опыт разработчиков влияет на эффективность команд и успех компании.
🎁 По завершении опроса вы сможете поучаствовать в лотерее с розыгрышем классных призов от организатора исследования и генеральных партнёров.
Вас ждут эксклюзивный мерч, подписки на полезные и развлекательные сервисы, промокоды на незаменимые в работе продукты, билеты на профильные конференции Highload++, DevOpsConf и другие подарки. Проходите опрос, участвуйте в розыгрыше подарков и побеждайте!
Участники первыми узнают о результатах и получат готовый отчёт, как только он будет готов.
Заполнить анкету 👉 по ссылке
Дорогие друзья, мы рады сообщить, что «Экспресс 42» при поддержке генеральных партнеров запустила ежегодное исследование состояния DevOps 2025! Мы планируем опросить больше 4000 представителей индустрии, связанных с DevOps: инженеров, разработчиков, администраторов, тестировщиков, техлидов и тимлидов, CIO и CTO.
Если тема DevOps вам не безразлична — пройдите опрос и внесите свой вклад в развитие индустрии. Важно мнение каждого респондента!
📊 Ключевой темой исследования в 2025 году становится Developer Experience (DX) — то, насколько опыт разработчиков влияет на эффективность команд и успех компании.
🎁 По завершении опроса вы сможете поучаствовать в лотерее с розыгрышем классных призов от организатора исследования и генеральных партнёров.
Вас ждут эксклюзивный мерч, подписки на полезные и развлекательные сервисы, промокоды на незаменимые в работе продукты, билеты на профильные конференции Highload++, DevOpsConf и другие подарки. Проходите опрос, участвуйте в розыгрыше подарков и побеждайте!
Участники первыми узнают о результатах и получат готовый отчёт, как только он будет готов.
Заполнить анкету 👉 по ссылке
VictoriaMetrics : Effective alerts, from theory to practice
Golden Signals, PromQL/MetricsQL и VMalert. В статье разобраны подходы к алертингу из VM.
Golden Signals, PromQL/MetricsQL и VMalert. В статье разобраны подходы к алертингу из VM.
{kind=link}
Облачные решения: как снизить затраты и повысить эффективность?
Приглашаем на бесплатный вебинар Слёрма 11 июня в 17:00.
Обсудим:
🔹 Типичные ошибки при работе с облачными сервисами и их влияние на бизнес.
🔹 Настройку сетевых сервисов и контроль доступа.
🔹 Как неправильный выбор ресурсов может привести к сбоям.
🔹 Почему резервное копирование — обязательная часть стратегии.
Покажем практику и кейсы с фокусом на эффективность.
Присоединяйтесь, будем учиться контролировать затраты на облачные сервисы и брать от них максимум!
Регистрация в один клик 👈
erid: 2W5zFJABQgp
Приглашаем на бесплатный вебинар Слёрма 11 июня в 17:00.
Обсудим:
🔹 Типичные ошибки при работе с облачными сервисами и их влияние на бизнес.
🔹 Настройку сетевых сервисов и контроль доступа.
🔹 Как неправильный выбор ресурсов может привести к сбоям.
🔹 Почему резервное копирование — обязательная часть стратегии.
Покажем практику и кейсы с фокусом на эффективность.
Присоединяйтесь, будем учиться контролировать затраты на облачные сервисы и брать от них максимум!
Регистрация в один клик 👈
erid: 2W5zFJABQgp
Prometheus Monitoring: Functions, Subqueries, Operators, and Modifiers
Статья из блога VictoriaMetrics о функциях, подзапросах, операторах и модификаторах.
Статья из блога VictoriaMetrics о функциях, подзапросах, операторах и модификаторах.
{kind=link}
🚀 Разгоняем kube-prometheus-stack: секретный ингредиент в Observability
🔥 9 июня в 20:00 мск — бесплатный вебинар «Разгоняем kube-prometheus-stack».
Мониторинг не должен тормозить, особенно когда что-то идёт не так.
Что разберём:
– как ускорить отклик Grafana при работе с большими объёмами данных,
– что замедляет Prometheus и как с этим бороться,
– как сократить сетевой трафик мониторинга без потерь,
– как не положить observability-инфру при инциденте,
– и какие архитектурные подходы помогают сделать мониторинг отказоустойчивым.
Оптимизируйте kube-prometheus-stack и держите руку на пульсе — даже в условиях пиковых нагрузок.
👉 Регистрируйтесь здесь: https://otus.pw/aQZ0I/?erid=2W5zFGborZn
Занятие приурочено к старту курса "Observability: мониторинг, логирование, трейсинг", на котором вы научитесь строить эффективные системы мониторинга, работать с Prometheus, Grafana, ELK и другими инструментами, визуализировать метрики.
Реклама. ООО "ОТУС ОНЛАЙН-ОБРАЗОВАНИЕ". ИНН 9705100963.
🔥 9 июня в 20:00 мск — бесплатный вебинар «Разгоняем kube-prometheus-stack».
Мониторинг не должен тормозить, особенно когда что-то идёт не так.
Что разберём:
– как ускорить отклик Grafana при работе с большими объёмами данных,
– что замедляет Prometheus и как с этим бороться,
– как сократить сетевой трафик мониторинга без потерь,
– как не положить observability-инфру при инциденте,
– и какие архитектурные подходы помогают сделать мониторинг отказоустойчивым.
Оптимизируйте kube-prometheus-stack и держите руку на пульсе — даже в условиях пиковых нагрузок.
👉 Регистрируйтесь здесь: https://otus.pw/aQZ0I/?erid=2W5zFGborZn
Занятие приурочено к старту курса "Observability: мониторинг, логирование, трейсинг", на котором вы научитесь строить эффективные системы мониторинга, работать с Prometheus, Grafana, ELK и другими инструментами, визуализировать метрики.
Реклама. ООО "ОТУС ОНЛАЙН-ОБРАЗОВАНИЕ". ИНН 9705100963.
ClickStack: A High-Performance OSS Observability Stack on ClickHouse
ClickStack — новое решение для наблюдаемости с открытым исходным кодом, созданное на основе ClickHouse. ClickStack обеспечивает полный, готовый к использованию инструмент для журналов, метрик, трассировок и воспроизведения сеансов — на основе производительности и эффективности ClickHouse, но разработанный как полный стек наблюдения, который открыт и доступен для всех.
Статья в блоге Clickhouse с описанием решения
Страница ClickStack
ClickStack — новое решение для наблюдаемости с открытым исходным кодом, созданное на основе ClickHouse. ClickStack обеспечивает полный, готовый к использованию инструмент для журналов, метрик, трассировок и воспроизведения сеансов — на основе производительности и эффективности ClickHouse, но разработанный как полный стек наблюдения, который открыт и доступен для всех.
Статья в блоге Clickhouse с описанием решения
Страница ClickStack
{kind=link}
Подборка популярных каналов по информационной безопасности и этичному хакингу:
🔐 infosec — ламповое сообщество, которое публикует редкую литературу, курсы и полезный контент для ИБ специалистов любого уровня и направления.
🤯 Social Engineering — самый крупный ресурс в Telegram, посвященный этичному Хакингу, OSINT и социальной инженерии.
💬 Вакансии в ИБ — актуальные предложения от самых крупных работодателей и лидеров рынка в сфере информационной безопасности.
🔐 infosec — ламповое сообщество, которое публикует редкую литературу, курсы и полезный контент для ИБ специалистов любого уровня и направления.
🤯 Social Engineering — самый крупный ресурс в Telegram, посвященный этичному Хакингу, OSINT и социальной инженерии.
💬 Вакансии в ИБ — актуальные предложения от самых крупных работодателей и лидеров рынка в сфере информационной безопасности.
Какие есть альтернативы Prometheus, если для метрик его стало недостаточно
Prometheus прекрасно подходит для краткосрочного мониторинга, но у этого решения есть свои ограничения по масштабу, и если вы столкнулись с высоким потреблением памяти/CPU, снижением скорости запросов или вам требуются уникальные лейблы вида user ID, то стоит подумать над внедрением альтернатив. На наш взгляд следующими после Prometheus в линейке стоят Thanos, Cortex, Mimir или VictoriaMetrics. Объективное, насколько это возможно, сравнение характеристик этих решений приведено в этой статье.
Prometheus прекрасно подходит для краткосрочного мониторинга, но у этого решения есть свои ограничения по масштабу, и если вы столкнулись с высоким потреблением памяти/CPU, снижением скорости запросов или вам требуются уникальные лейблы вида user ID, то стоит подумать над внедрением альтернатив. На наш взгляд следующими после Prometheus в линейке стоят Thanos, Cortex, Mimir или VictoriaMetrics. Объективное, насколько это возможно, сравнение характеристик этих решений приведено в этой статье.
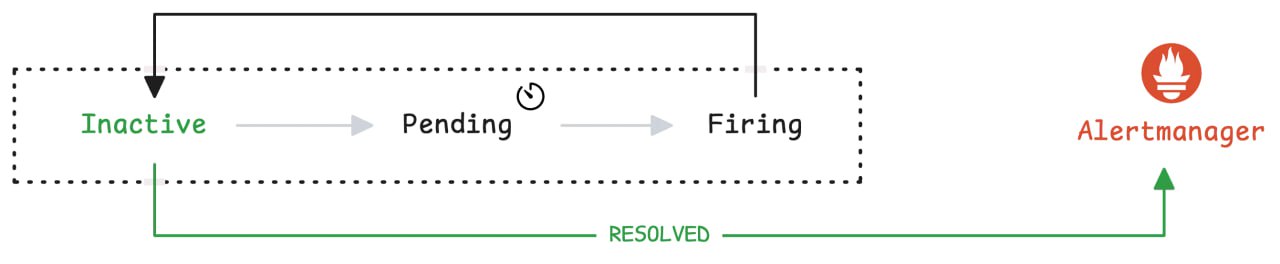
Prometheus Alerting 101: Rules, Recording Rules, and Alertmanager
Четвертая статья цикла в блоге VictoriaMetrics.
Первые три статьи:
🚀 Counters, Gauges, Histograms & Summaries
🚀 Instant Queries and Range Queries Explained
🚀 Functions, Subqueries, Operators, and Modifiers
Четвертая статья цикла в блоге VictoriaMetrics.
Первые три статьи:
🚀 Counters, Gauges, Histograms & Summaries
🚀 Instant Queries and Range Queries Explained
🚀 Functions, Subqueries, Operators, and Modifiers
{kind=link}
Трассировка запросов в Postgres с расширением pg_trace
Трассировка запросов — это процесс сбора и анализа запросов на стороне СУБД, необходимый для диагностики проблем с производительностью в базах данных. С её помощью можно:
🚀 понять, почему запрос выполняется медленно, — для этого нужно посмотреть текст запроса на языке SQL и его план;
🚀 определить источник чрезмерной нагрузки на БД (например, ресурсоемкий запрос) и связать его с ответственным пользователем;
🚀 упростить управление рабочими нагрузками приложений за счёт отслеживания конкретных модулей и действий в службе.
Для некоторых СУБД существуют специальные инструменты для трассировки запросов — профайлеры запросов. В этой статье рассказано про pg_trace — профайлер для СУБД Postgres.
Трассировка запросов — это процесс сбора и анализа запросов на стороне СУБД, необходимый для диагностики проблем с производительностью в базах данных. С её помощью можно:
🚀 понять, почему запрос выполняется медленно, — для этого нужно посмотреть текст запроса на языке SQL и его план;
🚀 определить источник чрезмерной нагрузки на БД (например, ресурсоемкий запрос) и связать его с ответственным пользователем;
🚀 упростить управление рабочими нагрузками приложений за счёт отслеживания конкретных модулей и действий в службе.
Для некоторых СУБД существуют специальные инструменты для трассировки запросов — профайлеры запросов. В этой статье рассказано про pg_trace — профайлер для СУБД Postgres.
{kind=link}
Почему стоит пройти официальные тренинги Zabbix?
Если вы хотите, чтобы ваша система мониторинга Zabbix работала не просто "как-то", а стабильно, надёжно и по максимуму эффективно — обучение от разработчиков Zabbix просто must-have. Вот почему:
💡 1. Быстрый старт без граблей
Сотрудники разберутся в Zabbix с нуля или систематизируют уже имеющиеся знания. Без боли, экспериментов и потери времени — только проверенные практики и рабочие кейсы.
📚 2. Только актуальные знания
Все материалы составлены самим Zabbix. Никаких устаревших гайдов с форумов — только то, что действительно работает в последних версиях.
🎓 3. Официальный сертификат
После тренинга можно сдать экзамен и получить международный сертификат, который подтверждает уровень знаний. Это не просто бумажка — это реальное подтверждение экспертизы.
🚀 4. Рост внутри команды
Обученные сотрудники — уверенные сотрудники. Они смогут быстрее находить и решать проблемы, а не тратить часы на разбор логов и эксперименты с триггерами.
💬 5. Возможность задать вопросы экспертам
На тренинге можно напрямую обсудить рабочие задачи и нюансы, с которыми сталкиваются именно ваши специалисты. Это не просто теория — это практическая польза.
🧰 6. Больше, чем документация
Даже если кто-то "и так всё умеет" — после тренинга появится масса новых идей, лайфхаков и инструментов, которые раньше просто не приходили в голову.
💸 7. Экономия времени и денег
Сотрудники не будут тратить дни на поиск решений. Они будут знать, где и как искать, и как правильно настраивать систему с первого раза.
🌍 8. Международный стандарт
Zabbix используют тысячи компаний по всему миру. Официальные знания — это способ выйти на один уровень с лидерами рынка и крупными игроками.
👥 9. Командная синергия
Когда вся команда говорит на одном языке и понимает логику системы, работать становится проще. Меньше недопонимания — больше эффективности.
🔐 10. Безопасность и надёжность
Zabbix — это не просто метрики. Это и безопасность, и отказоустойчивость. А грамотная настройка начинается с грамотных специалистов.
🎓 Тренинг Zabbix Сертифицированный Специалист 7.0 (ZCS 7.0) 📅 16-20 июня — ответ на вопрос «как быстро получить самые полные знания по Zabbix 7.0».
🎓 Тренинг Zabbix сертифицированный профессионал 7.0 (ZCP 7.0) будет следом — 📅 14-16 июля. Отличный шанс расширить и углубить знания, полученные на тренинге ZCS.
❗️ Полное расписание тренингов
Запрос дополнительной информации можно отправить @galssoftware или на [email protected].
erid: 2Vtzqv9kf9k
Если вы хотите, чтобы ваша система мониторинга Zabbix работала не просто "как-то", а стабильно, надёжно и по максимуму эффективно — обучение от разработчиков Zabbix просто must-have. Вот почему:
💡 1. Быстрый старт без граблей
Сотрудники разберутся в Zabbix с нуля или систематизируют уже имеющиеся знания. Без боли, экспериментов и потери времени — только проверенные практики и рабочие кейсы.
📚 2. Только актуальные знания
Все материалы составлены самим Zabbix. Никаких устаревших гайдов с форумов — только то, что действительно работает в последних версиях.
🎓 3. Официальный сертификат
После тренинга можно сдать экзамен и получить международный сертификат, который подтверждает уровень знаний. Это не просто бумажка — это реальное подтверждение экспертизы.
🚀 4. Рост внутри команды
Обученные сотрудники — уверенные сотрудники. Они смогут быстрее находить и решать проблемы, а не тратить часы на разбор логов и эксперименты с триггерами.
💬 5. Возможность задать вопросы экспертам
На тренинге можно напрямую обсудить рабочие задачи и нюансы, с которыми сталкиваются именно ваши специалисты. Это не просто теория — это практическая польза.
🧰 6. Больше, чем документация
Даже если кто-то "и так всё умеет" — после тренинга появится масса новых идей, лайфхаков и инструментов, которые раньше просто не приходили в голову.
💸 7. Экономия времени и денег
Сотрудники не будут тратить дни на поиск решений. Они будут знать, где и как искать, и как правильно настраивать систему с первого раза.
🌍 8. Международный стандарт
Zabbix используют тысячи компаний по всему миру. Официальные знания — это способ выйти на один уровень с лидерами рынка и крупными игроками.
👥 9. Командная синергия
Когда вся команда говорит на одном языке и понимает логику системы, работать становится проще. Меньше недопонимания — больше эффективности.
🔐 10. Безопасность и надёжность
Zabbix — это не просто метрики. Это и безопасность, и отказоустойчивость. А грамотная настройка начинается с грамотных специалистов.
🎓 Тренинг Zabbix Сертифицированный Специалист 7.0 (ZCS 7.0) 📅 16-20 июня — ответ на вопрос «как быстро получить самые полные знания по Zabbix 7.0».
🎓 Тренинг Zabbix сертифицированный профессионал 7.0 (ZCP 7.0) будет следом — 📅 14-16 июля. Отличный шанс расширить и углубить знания, полученные на тренинге ZCS.
❗️ Полное расписание тренингов
Запрос дополнительной информации можно отправить @galssoftware или на [email protected].
erid: 2Vtzqv9kf9k
💥 Собираем закрытую тусовку экспертов по K8s вокруг Nova Container Platform СНОВА О КУБЕРЕ
10 июня ждем DevOps-инженеров, архитекторов, CTO, CIO, разработчиков, DevSecOps-специалистов на первый офлайн КУБЕР СБОР в Москве.
Обсудим:
➖ Как выбрать решение для Service Mesh и избежать «подводных камней»
➖ Как переиспользовать старые серверы с GPU, чтобы объединять их в логический пул для тренировки современных крупных языковых моделей
➖ Как эффективно запустить распределенный интерфейс языковой модели на нескольких видеокартах в Kubernetes
➖ Разбор реального кейса по задаче безопасного хранения секретов в K8s
➖ Какие фичи мы уже добавили в оркестратор и что добавим до конца 2025 года
Вайб: крутой технический контент, неформальная обстановка, вкусная пицца и кальяны.
📌Регистрация и подробности
10 июня ждем DevOps-инженеров, архитекторов, CTO, CIO, разработчиков, DevSecOps-специалистов на первый офлайн КУБЕР СБОР в Москве.
Обсудим:
➖ Как выбрать решение для Service Mesh и избежать «подводных камней»
➖ Как переиспользовать старые серверы с GPU, чтобы объединять их в логический пул для тренировки современных крупных языковых моделей
➖ Как эффективно запустить распределенный интерфейс языковой модели на нескольких видеокартах в Kubernetes
➖ Разбор реального кейса по задаче безопасного хранения секретов в K8s
➖ Какие фичи мы уже добавили в оркестратор и что добавим до конца 2025 года
Вайб: крутой технический контент, неформальная обстановка, вкусная пицца и кальяны.
📌Регистрация и подробности