
Мониторинг температуры Windows. Создание метрик, настройка InfluxDB и Grafana
В этой статье автор показывает полный путь от получения таких метрик до конечной визуализации на примере сбора информации датчиков температуры Windows в минимально возможной конфигурации. Читать статью.
У автора есть репозиторий на GitHub с различными PowerShell-командами.
В этой статье автор показывает полный путь от получения таких метрик до конечной визуализации на примере сбора информации датчиков температуры Windows в минимально возможной конфигурации. Читать статью.
У автора есть репозиторий на GitHub с различными PowerShell-командами.
{kind=link}
SRE Interview Prep Plan
В этом цикле статей 6-недельный план, который составлен, чтобы пройти через весь процесс подготовки к собеседованию на позицию SRE. На каждой неделе уделено внимание развитию знаний в ключевых областях, которые должны знать SRE, таких как автоматизация, мониторинг, реагирование на инциденты и т. д.
В статьях собраны ссылки на материалы для подготовки. Полезный свод знаний для подготовки к интервью. В одном из прошлых постов ссылка на статьи по первым 4 неделям, а в этом вы найдете ссылку на статью по 5 неделе.
Неделя 5
Day 1: Introduction to Scalability
Day 2: Performance Metrics and Tools
Day 3: Architectural Patterns for Scalability
Day 4: Optimizing Application Performance
Day 5: Infrastructure Optimization
Days 6-7: System Design
В этом цикле статей 6-недельный план, который составлен, чтобы пройти через весь процесс подготовки к собеседованию на позицию SRE. На каждой неделе уделено внимание развитию знаний в ключевых областях, которые должны знать SRE, таких как автоматизация, мониторинг, реагирование на инциденты и т. д.
В статьях собраны ссылки на материалы для подготовки. Полезный свод знаний для подготовки к интервью. В одном из прошлых постов ссылка на статьи по первым 4 неделям, а в этом вы найдете ссылку на статью по 5 неделе.
Неделя 5
Day 1: Introduction to Scalability
Day 2: Performance Metrics and Tools
Day 3: Architectural Patterns for Scalability
Day 4: Optimizing Application Performance
Day 5: Infrastructure Optimization
Days 6-7: System Design
{kind=link}
За свои собственные деньги я вписался в курс Observability от Отуса. Решил расширить свои знания в области мониторинга на чуть менее известные для меня TICK Stack, Grafana Loki, Tempo, Jaeger, Prometheus, Thanos и другие модные словечки.
Если вы проходили этот курс, напишите, что о нем думаете в комментах. Я планирую периодически писать посты в канале о своих ощущениях от курса, о преподавателях и, самое главное, о пользе. Вообще, мне интересно узнать как устроены процессы мониторинга в других компаниях, узнать подходы, которые они там используют.
Ссылки не публикую, поиском легко найти этот курс.
Если вы проходили этот курс, напишите, что о нем думаете в комментах. Я планирую периодически писать посты в канале о своих ощущениях от курса, о преподавателях и, самое главное, о пользе. Вообще, мне интересно узнать как устроены процессы мониторинга в других компаниях, узнать подходы, которые они там используют.
Ссылки не публикую, поиском легко найти этот курс.
How to Create and Work with Variables | Grafana
Из этого видео с ютуб-канала Grafana вы узнаете:
⚡️Что такое переменные дашбордов
⚡️ Какие типы переменных существуют
⚡️ Как создавать переменные
⚡️ Пример создания переменной
Из этого видео с ютуб-канала Grafana вы узнаете:
⚡️Что такое переменные дашбордов
⚡️ Какие типы переменных существуют
⚡️ Как создавать переменные
⚡️ Пример создания переменной
YouTube
How to Create and Work with Variables | Grafana
Links:
Variables
https://grafana.com/docs/grafana/latest/dashboards/variables/
List of Global Variables
https://grafana.com/docs/grafana/latest/dashboards/variables/add-template-variables/#global-variables
Sign up for Grafana cloud for free: https://graf…
Variables
https://grafana.com/docs/grafana/latest/dashboards/variables/
List of Global Variables
https://grafana.com/docs/grafana/latest/dashboards/variables/add-template-variables/#global-variables
Sign up for Grafana cloud for free: https://graf…
Key metrics for monitoring etcd
Статья из блога Datadog и посвящена мониторингу etcd в Kubernetes. В ней показаны ключевые показатели, которые следует отслеживать, чтобы убедиться, что etcd обеспечивает работоспособность и производительность кластера Kubernetes. Читать статью.
Статья из блога Datadog и посвящена мониторингу etcd в Kubernetes. В ней показаны ключевые показатели, которые следует отслеживать, чтобы убедиться, что etcd обеспечивает работоспособность и производительность кластера Kubernetes. Читать статью.
{kind=link}
Ещё одно интересное выступление с Fosdem 2024 — Linux load average and other silly metrics. Здесь запускают нагрузку на сервере и интересно интерпретируют показатели утилиты top. Смотреть видео.
{kind=link}
The engineering on-call experience: misconceptions, lessons learned, and how to prepare
В этой статье старшие инженеры-программисты Grafana делятся своими самыми большими заблуждениями о дежурстве, некоторыми советами и приемами, которые они узнали на этом пути, а также тем, почему этот опыт может быть полезным и веселым. Читать статью.
В этой статье старшие инженеры-программисты Grafana делятся своими самыми большими заблуждениями о дежурстве, некоторыми советами и приемами, которые они узнали на этом пути, а также тем, почему этот опыт может быть полезным и веселым. Читать статью.
How to Display Grafana Alerts to Your Dashboards | Grafana
В этом видео рассказывывают о подходах к визуализации алертов на дашбордах в Grafana.
В этом видео рассказывывают о подходах к визуализации алертов на дашбордах в Grafana.
{kind=link}
Настраиваем логирование с помощью Loki и Grafana
При построении микросервисной архитектуры часто возникает потребность анализировать логи из нескольких источников (баз, сервисов и т. д.). В этой статье автор делится решением к которому в итоге пришел. Читать статью.
При построении микросервисной архитектуры часто возникает потребность анализировать логи из нескольких источников (баз, сервисов и т. д.). В этой статье автор делится решением к которому в итоге пришел. Читать статью.
{kind=link}
{kind=link}
{kind=link}
ClickHouse как бэкенд для Prometheus
Вы узнаете про мощные возможности ClickHouse для эффективного долгосрочного хранения метрик Prometheus. В статье также есть рекомендации по использованию инструмента и описание альтернативных решений, таких как Thanos, Grafana Mimir и Victoria Metrics. Читать статью.
Вы узнаете про мощные возможности ClickHouse для эффективного долгосрочного хранения метрик Prometheus. В статье также есть рекомендации по использованию инструмента и описание альтернативных решений, таких как Thanos, Grafana Mimir и Victoria Metrics. Читать статью.
{kind=link}
Как мы выстроили систему визуализации ошибок с помощью Grafana и снизили время на их отработку с 2 часов до 15 секунд
Решение, как архитектурное так и практическое, пришло, как это часто бывает, со стороны разработки. Операции, производимые с данными, логировались с самого начала. Эти логи складывались в БД. Мы решили их расширить, продлить (не все источники логировались с одинаковой степенью глубины) и визуализировать.
Для визуализации взяли популярный инструмент, который выводит нужную информацию в удобочитаемом виде — Grafana. Обновления в этой системе выглядят в виде самолетной панели — все видно на одном экране.
Теперь у нас работает цепочка Backend -> Prometheus -> Grafana. Скорость изучения статуса обновления снизилась с 2 часов (когда специалист вручную шел в логи при возникновении ошибки) до 15 секунд.
Читать статью на Хабре.
Решение, как архитектурное так и практическое, пришло, как это часто бывает, со стороны разработки. Операции, производимые с данными, логировались с самого начала. Эти логи складывались в БД. Мы решили их расширить, продлить (не все источники логировались с одинаковой степенью глубины) и визуализировать.
Для визуализации взяли популярный инструмент, который выводит нужную информацию в удобочитаемом виде — Grafana. Обновления в этой системе выглядят в виде самолетной панели — все видно на одном экране.
Теперь у нас работает цепочка Backend -> Prometheus -> Grafana. Скорость изучения статуса обновления снизилась с 2 часов (когда специалист вручную шел в логи при возникновении ошибки) до 15 секунд.
Читать статью на Хабре.
{kind=link}
Мы запустили профессиональную сертификацию по облачным технологиям!
Наша программа сертификации ориентирована на международные стандарты, поэтому теперь специалисты по облачным технологиям смогут официально подтвердить свои компетенции. Это поможет им получить конкурентное преимущество при трудоустройстве, ускорить развитие карьеры и претендовать на более высокую оплату. А для тех, кто работает с заказчиками напрямую, — получать более выгодные контракты.
Экзамен на сертификат Yandex Cloud Certified Engineer Associate проверяет знания и навыки в шести областях:
• Базовые облачные технологии
• Хранение и обработка данных
• DevOps и автоматизация
• Бессерверные вычисления
• Информационная безопасность
• Биллинг
🔍 О том, как устроена сертификация, что нужно сделать для подготовки и участия в первом экзамене, читайте по ссылке.
Наша программа сертификации ориентирована на международные стандарты, поэтому теперь специалисты по облачным технологиям смогут официально подтвердить свои компетенции. Это поможет им получить конкурентное преимущество при трудоустройстве, ускорить развитие карьеры и претендовать на более высокую оплату. А для тех, кто работает с заказчиками напрямую, — получать более выгодные контракты.
Экзамен на сертификат Yandex Cloud Certified Engineer Associate проверяет знания и навыки в шести областях:
• Базовые облачные технологии
• Хранение и обработка данных
• DevOps и автоматизация
• Бессерверные вычисления
• Информационная безопасность
• Биллинг
🔍 О том, как устроена сертификация, что нужно сделать для подготовки и участия в первом экзамене, читайте по ссылке.
Prometheus & OpenTelemetry: Better Together
Статья о том как подружить Prometheus и OTel c примерами настроек. Читать статью.
Статья на Медиум.
Статья о том как подружить Prometheus и OTel c примерами настроек. Читать статью.
Статья на Медиум.
{kind=link}
Monitoring Kubernetes Security Metrics with Prometheus and Kubescape
Пошаговая инструкция по мониторингу безопасности Kubernetes. Разобрана настройка аудита логов Kubernetes при помощи Kubescape, отправка из в Loki и дальнейшая визуализация в Grafana. Читать статью.
❗️ Статья на Медиум
Пошаговая инструкция по мониторингу безопасности Kubernetes. Разобрана настройка аудита логов Kubernetes при помощи Kubescape, отправка из в Loki и дальнейшая визуализация в Grafana. Читать статью.
❗️ Статья на Медиум
{kind=link}
SRE Interview Prep Plan
В этом цикле статей 6-недельный план, который составлен, чтобы пройти через весь процесс подготовки к собеседованию на позицию SRE. На каждой неделе уделено внимание развитию знаний в ключевых областях, которые должны знать SRE, таких как автоматизация, мониторинг, реагирование на инциденты и т. д.
В статьях собраны ссылки на материалы для подготовки. Полезный свод знаний для подготовки к интервью. В одном из прошлых постов ссылка на статьи по первым 4 неделям, отдельно вышел пост со ссылкой на статью по 5 неделе. А в этом посте заключительная статья по 6 неделе подготовки к интервью на позицию SRE
Неделя 6
Day 1-2: LeetCode Coding Challenges
Day 3: System Design Fundamentals
Day 4-5: Behavioral Mock Interviews Focusing on SRE Scenarios
Day 6-7: Revision and Feedback
В этом цикле статей 6-недельный план, который составлен, чтобы пройти через весь процесс подготовки к собеседованию на позицию SRE. На каждой неделе уделено внимание развитию знаний в ключевых областях, которые должны знать SRE, таких как автоматизация, мониторинг, реагирование на инциденты и т. д.
В статьях собраны ссылки на материалы для подготовки. Полезный свод знаний для подготовки к интервью. В одном из прошлых постов ссылка на статьи по первым 4 неделям, отдельно вышел пост со ссылкой на статью по 5 неделе. А в этом посте заключительная статья по 6 неделе подготовки к интервью на позицию SRE
Неделя 6
Day 1-2: LeetCode Coding Challenges
Day 3: System Design Fundamentals
Day 4-5: Behavioral Mock Interviews Focusing on SRE Scenarios
Day 6-7: Revision and Feedback
{kind=link}
{kind=link}
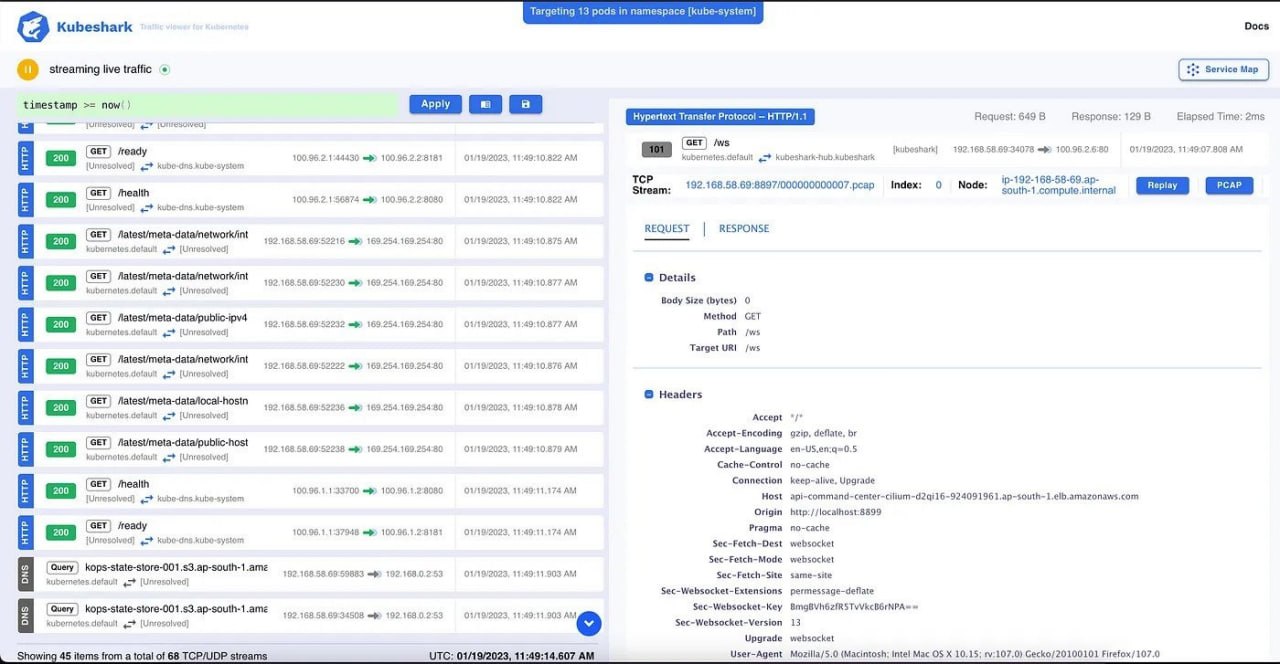
Kubeshark — мониторинг и анализ Kubernetes
Kubeshark захватывает пакеты на уровнях L3 и L7. В результате, можно создать дашборд мониторинга для визуализации данных Kubernetes по аналогии того же самого Wireshark. Читать статью.
Kubeshark захватывает пакеты на уровнях L3 и L7. В результате, можно создать дашборд мониторинга для визуализации данных Kubernetes по аналогии того же самого Wireshark. Читать статью.
{kind=link}
erid: 2VtzqxHHvUv
👀 В 2013 году мой одногруппник на заводе мог заработать больше, чем я в айти.
Такой расклад меня не устраивал, и я искал себя в других сферах — работал в такси, пробовал открыть бизнес, преподавал танцы...
/да-да, представьте себе танцующего айтишника 😅
В Southbridge я начал с младшей позиции — работал ночным администратором и реагировал на аварии. Затем уже перешел в основную команду.
Скажу честно: поначалу было очень напряженно. Приходилось сидеть вечерами и самому осваивать тонну новой информации. При этом зарплата все еще не устраивала. Да, одногруппника на заводе я догнал, но хотелось большего.
Ближе к 2018 году мы активно начали работать с контейнерами, и я оказался перед выбором: остаться на позиции системного администратора или расширить стек технологий и пойти в девопс.
Я выбрал второй вариант, и это было одно из лучших решений в жизни.
Почему DevOps?
1⃣ Это дает возможность мощно прокачаться в техническом плане;
2⃣ Это позволяет повысить зарплату минимум в 2-3 раза, причем сделать это можно всего за полгода;
3⃣ Топовые компании с руками отрывают грамотных DevOps-специалистов.
Когда я начинал свой путь, методология только набирала популярность. У девопс есть своя специфика, и она не так уж проста, поэтому мне очень не хватало какой-то маршрутной карты, чтобы структурировать знания.
⚡ И я хочу, чтобы она была у вас!
Мы в Слёрме подготовили крутой роадмап по базовым и основным компетенциям для всех, кто собирается в DevOps. Он создан с учетом российских реалий, разбит на уровни и фокусирует внимание на том, что в первую очередь
понадобится для старта и роста в профессии.
🔗 ЗАБРАТЬ РОАДМАП
Такой расклад меня не устраивал, и я искал себя в других сферах — работал в такси, пробовал открыть бизнес, преподавал танцы...
/да-да, представьте себе танцующего айтишника 😅
В Southbridge я начал с младшей позиции — работал ночным администратором и реагировал на аварии. Затем уже перешел в основную команду.
Скажу честно: поначалу было очень напряженно. Приходилось сидеть вечерами и самому осваивать тонну новой информации. При этом зарплата все еще не устраивала. Да, одногруппника на заводе я догнал, но хотелось большего.
Ближе к 2018 году мы активно начали работать с контейнерами, и я оказался перед выбором: остаться на позиции системного администратора или расширить стек технологий и пойти в девопс.
Я выбрал второй вариант, и это было одно из лучших решений в жизни.
Почему DevOps?
Когда я начинал свой путь, методология только набирала популярность. У девопс есть своя специфика, и она не так уж проста, поэтому мне очень не хватало какой-то маршрутной карты, чтобы структурировать знания.
Мы в Слёрме подготовили крутой роадмап по базовым и основным компетенциям для всех, кто собирается в DevOps. Он создан с учетом российских реалий, разбит на уровни и фокусирует внимание на том, что в первую очередь
понадобится для старта и роста в профессии.
Please open Telegram to view this post
VIEW IN TELEGRAM