
Встречаемся 30 мая в штаб-квартире Сбера! На митапе вместе с инженерами сопровождения и DevOps-инженерами обсудим тему вендорозамещения и импортозамещения ПО и технологий, а также сфокусируемся на вопросах их сопровождения.
Приглашаем вас присоединиться к большому сообществу support-специалистов и пообщаться с коллегами из технологических компаний со всей страны.
Подробности и регистрация - на сайте! Количество мест ограничено.
Please open Telegram to view this post
VIEW IN TELEGRAM
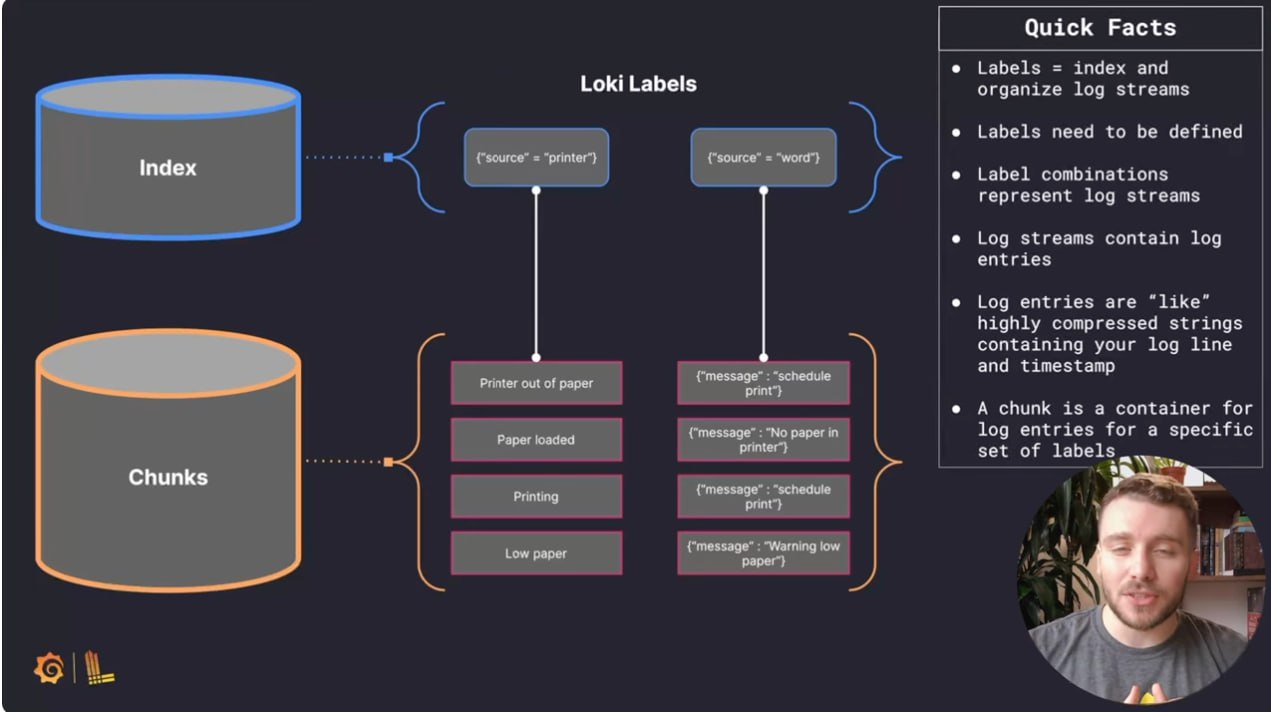
Zero to Hero: Loki | Grafana
Если вы ищете простую систему логирования — почему бы не обратить внимание на Loki? В этой серии видео команда Grafana рассказывает начиная с самых азов.
Intro to Logging | Zero to Hero: Loki | Grafana
Structure of Logs (Part 1) | Zero to Hero: Loki | Grafana
Structure of Logs (Part 2) | Zero to Hero: Loki | Grafana
How to Get Started with Loki | Zero to Hero: Loki | Grafana
Introduction to Ingesting logs with Loki | Zero to Hero: Loki | Grafana
Если вы ищете простую систему логирования — почему бы не обратить внимание на Loki? В этой серии видео команда Grafana рассказывает начиная с самых азов.
Intro to Logging | Zero to Hero: Loki | Grafana
Structure of Logs (Part 1) | Zero to Hero: Loki | Grafana
Structure of Logs (Part 2) | Zero to Hero: Loki | Grafana
How to Get Started with Loki | Zero to Hero: Loki | Grafana
Introduction to Ingesting logs with Loki | Zero to Hero: Loki | Grafana
{kind=link}
Как случайно написать систему мониторинга (еще одну)
Почему нет, если да?
Статья на Хабр
Репыч на Гитхабе
Почему нет, если да?
Статья на Хабр
Репыч на Гитхабе
{kind=link}
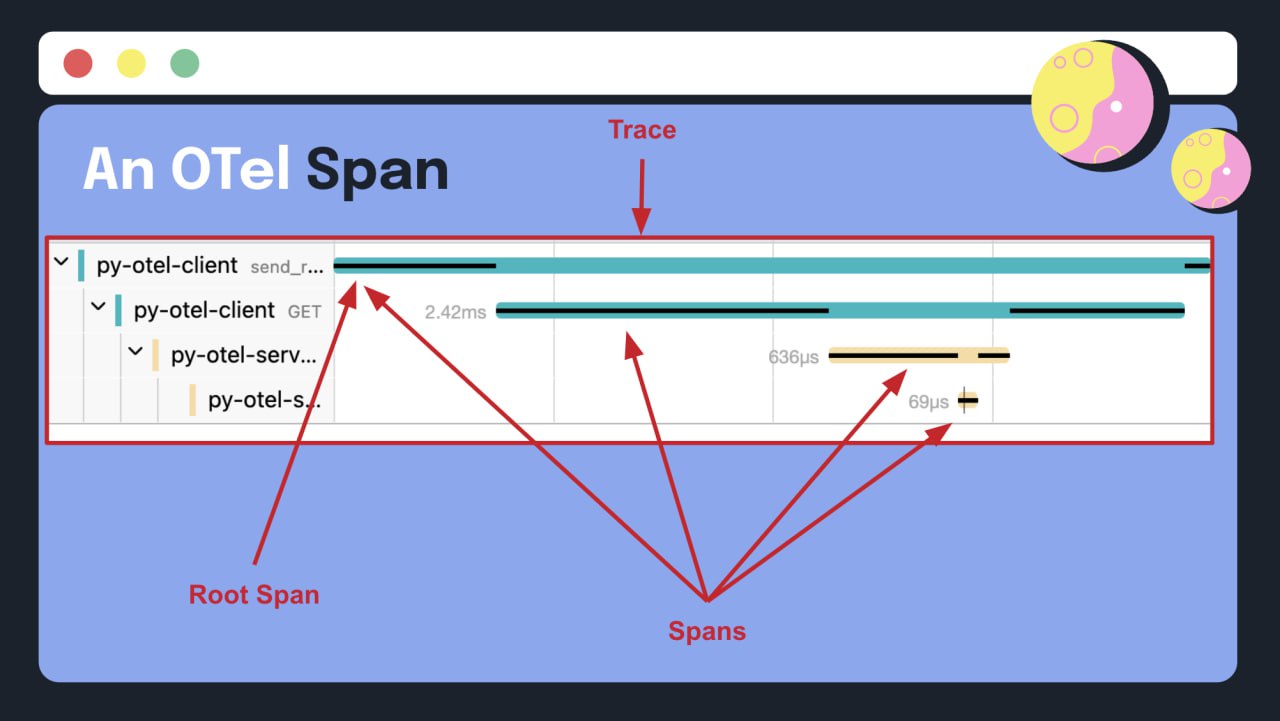
Dude, where's my error? How OpenTelemetry records errors
Некоторые языки, такие как Python и JavaScript, рассматривают ошибки и исключения как синонимы; другие, такие как PHP и Java, этого не делают. Понимание различия между ошибками и исключениями имеет решающее значение для эффективной обработки ошибок, т.к. оно позволяет использовать более тонкие стратегии обработки и восстановления после сбоев в приложениях.
Это важная статья для понимания того, как устроен OpenTelemetry и как собирает данные. Читать.
Некоторые языки, такие как Python и JavaScript, рассматривают ошибки и исключения как синонимы; другие, такие как PHP и Java, этого не делают. Понимание различия между ошибками и исключениями имеет решающее значение для эффективной обработки ошибок, т.к. оно позволяет использовать более тонкие стратегии обработки и восстановления после сбоев в приложениях.
Это важная статья для понимания того, как устроен OpenTelemetry и как собирает данные. Читать.
{kind=link}
Zabbix 7.0 LTS
Трудно спорить с тем, что все очень долго ждали выхода новой мажорной версии Zabbix. Вчера объявили о выходе нового релиза, а там действительно много нововведений:
🟩 Веб-мониторинг на базе Selenium
🟩 Высокая доступность и распределение нагрузки для Zabbix-Proxy
🟩 Повышена производительность Zabbix-Proxy
🟩 Улучшена скорость сбора данных (асинхронные поллеры)
🟩 Централизованное управление таймаутами
🟩 Новые панели для визуализации данных
🟩 Динамический дашборд для навигации между узлами
🟩 Многофакторная аутентификация
🟩 Новые шаблоны и интеграции
🟩 Изменение лицензирования Zabbix на AGPLv3
Что нового
Трудно спорить с тем, что все очень долго ждали выхода новой мажорной версии Zabbix. Вчера объявили о выходе нового релиза, а там действительно много нововведений:
🟩 Веб-мониторинг на базе Selenium
🟩 Высокая доступность и распределение нагрузки для Zabbix-Proxy
🟩 Повышена производительность Zabbix-Proxy
🟩 Улучшена скорость сбора данных (асинхронные поллеры)
🟩 Централизованное управление таймаутами
🟩 Новые панели для визуализации данных
🟩 Динамический дашборд для навигации между узлами
🟩 Многофакторная аутентификация
🟩 Новые шаблоны и интеграции
🟩 Изменение лицензирования Zabbix на AGPLv3
Что нового
homer
Утилита операторского уровня для наблюдения за пакетами и событиями VoiP/RTC, основанная на протоколе HEP/EEP и готовая принимать большие объемы сигналов, событий RTC, логов и статистики с мгновенным и сквозным поиском.
Репыч на Гитхабе
Утилита операторского уровня для наблюдения за пакетами и событиями VoiP/RTC, основанная на протоколе HEP/EEP и готовая принимать большие объемы сигналов, событий RTC, логов и статистики с мгновенным и сквозным поиском.
Репыч на Гитхабе
gatus
Утилита мониторинга состояния, ориентированная на разработчиков, которая дает вам возможность отслеживать службы с помощью HTTP, ICMP, TCP и DNS-запросов, а также анализировать результат запросов, используя список условий для значений, таких как код и время ответа, срок действия сертификата, тело ответа и многие другие. Каждую из этих проверок работоспособности можно сочетать с оповещениями через Slack, Teams, PagerDuty, Discord, Twilio и другие.
Репыч на гитхабе
Утилита мониторинга состояния, ориентированная на разработчиков, которая дает вам возможность отслеживать службы с помощью HTTP, ICMP, TCP и DNS-запросов, а также анализировать результат запросов, используя список условий для значений, таких как код и время ответа, срок действия сертификата, тело ответа и многие другие. Каждую из этих проверок работоспособности можно сочетать с оповещениями через Slack, Teams, PagerDuty, Discord, Twilio и другие.
Репыч на гитхабе
{kind=link}
Дашборды на Apache Superset
Можно рассмотреть в качестве замены PowerBI. Superset отвечает следующим требованиям:
⚡️ Открытый исходный код
⚡️ Возможность добавления новых коннекторов
⚡️ SQL для выполнения запросов
⚡️ Мнопользовательская модель доступа к дашбордам
⚡️ Возможность параметризации дашбордов для гибкой настройки
⚡️ Многообразие визализаций
Репыч на Гитхабе (60К звезд — не хухры-мухры)
Статья с описанием на medium.com
Можно рассмотреть в качестве замены PowerBI. Superset отвечает следующим требованиям:
⚡️ Открытый исходный код
⚡️ Возможность добавления новых коннекторов
⚡️ SQL для выполнения запросов
⚡️ Мнопользовательская модель доступа к дашбордам
⚡️ Возможность параметризации дашбордов для гибкой настройки
⚡️ Многообразие визализаций
Репыч на Гитхабе (60К звезд — не хухры-мухры)
Статья с описанием на medium.com
{kind=link}
Главная в России конференция про Kubernetes®
4 июля на Kuber Conf’24 разработчики и эксперты по контейнерным технологиям поделятся стратегиями решения бизнес-задач, обзорами инструментов и лучшими практиками. Подробная программа — на сайте!
Регистрируйтесь и присоединяйтесь к сообществу K8s-специалистов.
Место проведения — Москва, можно участвовать онлайн.
4 июля на Kuber Conf’24 разработчики и эксперты по контейнерным технологиям поделятся стратегиями решения бизнес-задач, обзорами инструментов и лучшими практиками. Подробная программа — на сайте!
Регистрируйтесь и присоединяйтесь к сообществу K8s-специалистов.
Место проведения — Москва, можно участвовать онлайн.
Гайд по настройке мониторинга PostgreSQL при помощи Prometheus и Grafana
В статье подобно разобрана настройка мониторинга БД PostgreSQL. Читать на medium.
В статье подобно разобрана настройка мониторинга БД PostgreSQL. Читать на medium.
{kind=link}
Оптимизация производительности Zabbix
Из канала @zabbix_ru (только про Zabbix и ничего кроме Zabbix):
Тюнинг производительности — обязательная часть работы администратора Zabbix. При росте количества узлов, количества собираемых элементов данных и снижению интервалов их сбора резко возрастает шанс столкнуться с бутылочными горлышками в производительности. Ключевые метрики, которые напрямую влияют на производительность — количество узлов (разумеется, с наполняемыми элементами данных) и количество новых значений в секунду. Чем их больше и чем меньше интервал сбора данных — тем больше нагрузка на инсталляцию Zabbix в целом. При этом, элементы данных типа Zabbix Trapper и SNMP-трап особого вклада в нагрузку не вносят.
Читать статью о том, как оптимизировать Zabbix
Из канала @zabbix_ru (только про Zabbix и ничего кроме Zabbix):
Тюнинг производительности — обязательная часть работы администратора Zabbix. При росте количества узлов, количества собираемых элементов данных и снижению интервалов их сбора резко возрастает шанс столкнуться с бутылочными горлышками в производительности. Ключевые метрики, которые напрямую влияют на производительность — количество узлов (разумеется, с наполняемыми элементами данных) и количество новых значений в секунду. Чем их больше и чем меньше интервал сбора данных — тем больше нагрузка на инсталляцию Zabbix в целом. При этом, элементы данных типа Zabbix Trapper и SNMP-трап особого вклада в нагрузку не вносят.
Читать статью о том, как оптимизировать Zabbix
gals.software
Блог Gals Software | Тюнинг производительности Zabbix 7.0
Рассказываем об подходах к тюнингу производительности Zabbix 7.0 LTS
Нюансы работы с Redis: репликация
DevOps-инженер компании Nixys продолжает свой обзор Redis. Эта статья — подробное руководство по базовой репликации Redis, из которого вы узнаете, как настроить эту БД на высокий уровень отказоустойчивости. В конце статьи автор поместил разбор атаки на Redis через H2Miner, из-за которой можно полностью потерять данные на инстансе Redis. Читать статью.
DevOps-инженер компании Nixys продолжает свой обзор Redis. Эта статья — подробное руководство по базовой репликации Redis, из которого вы узнаете, как настроить эту БД на высокий уровень отказоустойчивости. В конце статьи автор поместил разбор атаки на Redis через H2Miner, из-за которой можно полностью потерять данные на инстансе Redis. Читать статью.
SLA vs. SLO vs. SLI: What’s the Difference?
В статье рассказывают о предназначении SLA, SLO и SLI, а также приводятся примеры каждой сущности. Полезно, если планируете внедрять у себя работу с этими показателями. Читать статью.
В статье рассказывают о предназначении SLA, SLO и SLI, а также приводятся примеры каждой сущности. Полезно, если планируете внедрять у себя работу с этими показателями. Читать статью.
{kind=link}
SRE Archetypes или какой ты сегодня SRE
В статье разобраны разные подходы к работе SRE и можно попробовать определить ваш стиль работы: Админ, Архитектор, Слесарь или пожарный. Читать статью.
В статье разобраны разные подходы к работе SRE и можно попробовать определить ваш стиль работы: Админ, Архитектор, Слесарь или пожарный. Читать статью.
{kind=link}
{kind=link}
Pinterest: разработка всеобъемлющей JSON-системы логирования для клиентских приложений
В начале 2020 года у приложения Pinterest для iOS часто возникала серьёзная проблема, связанная с нехваткой памяти. Тогда в компании поняли, что у них нет ни достаточно подробных сведений о работе приложений, ни хорошей системы, позволяющей анализировать подобные сведения в целях мониторинга приложений и решения проблем. В посте рассказывают о подходах к логированию и использованию для этого в т.ч. OpenSearch. Читать статью на Хабре.
В начале 2020 года у приложения Pinterest для iOS часто возникала серьёзная проблема, связанная с нехваткой памяти. Тогда в компании поняли, что у них нет ни достаточно подробных сведений о работе приложений, ни хорошей системы, позволяющей анализировать подобные сведения в целях мониторинга приложений и решения проблем. В посте рассказывают о подходах к логированию и использованию для этого в т.ч. OpenSearch. Читать статью на Хабре.
{kind=link}
Getting started with Grafana: best practices to design your first dashboard
Разбирают эффективный дашбординг в зависимости от того, кто будет смотреть на панели мониторинга. Читать в блоге Grafana.
Разбирают эффективный дашбординг в зависимости от того, кто будет смотреть на панели мониторинга. Читать в блоге Grafana.
{kind=link}
How to customize your Loki deployment with Ansible
Существуют различные методы деплоя Loki: Helm, Tanka, Docker или Docker Compose и локально из исходников. Все эти методы установки великолепны, служат своей цели и дают гибкость пользователям, чтобы развернуть Loki способом, который соответствует конкретным задачам. В статье представлен другой подход — роль Ansible Loki. Эта роль поддерживает Debian, Ubuntu и Red Hat. Читать в блоге Grafana.
Существуют различные методы деплоя Loki: Helm, Tanka, Docker или Docker Compose и локально из исходников. Все эти методы установки великолепны, служат своей цели и дают гибкость пользователям, чтобы развернуть Loki способом, который соответствует конкретным задачам. В статье представлен другой подход — роль Ansible Loki. Эта роль поддерживает Debian, Ubuntu и Red Hat. Читать в блоге Grafana.
{kind=link}
Alerts Are Fundamentally Messy
Хорошая подход к гигиене алертинга состоит из нескольких компонентов: контроль за условиями срабатывания оповещения, постмортем и размышления о том, что делает алертинг хорошим или плохим. Задача состоит в доведении алертинга до стадии, когда уведомления улетят, когда они должны отправиться, и не будут разосланы, когда это не требуется. Вообще говоря, это недостижимый идеал.
Реальность такова, что достижение идеала это процесс, а сам идеал недостижим. В этой статье разобран подобный итеративный процесс. Читать статью.
Хорошая подход к гигиене алертинга состоит из нескольких компонентов: контроль за условиями срабатывания оповещения, постмортем и размышления о том, что делает алертинг хорошим или плохим. Задача состоит в доведении алертинга до стадии, когда уведомления улетят, когда они должны отправиться, и не будут разосланы, когда это не требуется. Вообще говоря, это недостижимый идеал.
Реальность такова, что достижение идеала это процесс, а сам идеал недостижим. В этой статье разобран подобный итеративный процесс. Читать статью.
{kind=link}
How we avoided alarm fatigue syndrome by managing/reducing the alerting noise
Сотрудник Doctolib делится способом снижения количества шумовых событий. Они используют для алертинга PagerDuty, но никто ж не мешает поставить на это место Grafana OnCall или другое решение. Читать статью.
❗️Статья на Медиум
Сотрудник Doctolib делится способом снижения количества шумовых событий. Они используют для алертинга PagerDuty, но никто ж не мешает поставить на это место Grafana OnCall или другое решение. Читать статью.
❗️Статья на Медиум
{kind=link}