
Польза от Code Review
У нас в компании уже достаточное время внедрен Code Review и можно подвести некоторые промежуточные итоги:
1. Код стал чище и более читаемый
2. Большая часть багов и недоработок выявляется на стадии Code Review
3. Документация обновляется сразу по мере написания кода, описаны все bugfix
4. Поддерживать код в проде стало проще
5. Вырос средний уровень написания продакшен кода в команде
У нас в компании уже достаточное время внедрен Code Review и можно подвести некоторые промежуточные итоги:
1. Код стал чище и более читаемый
2. Большая часть багов и недоработок выявляется на стадии Code Review
3. Документация обновляется сразу по мере написания кода, описаны все bugfix
4. Поддерживать код в проде стало проще
5. Вырос средний уровень написания продакшен кода в команде
Привет всем любителям футбола и аналитики!
Я решил немного разделить контент и пригласить всех любителей футбола и футбольной аналитики в свой второй Telegram-канал Артета позвонит
Канал будет полностью посвящен футбольной аналитике:
- Python для анализа футбольных данных
- Анализ футбольных матчей
- Анализ Fantasy EPL
- Мысли о футболе человека, который никогда не играл в профессиональный футбол, но хочет туда попасть
Если вам интересна эта тема подписывайтесь, будем вместе понимать футбол по новому
Я решил немного разделить контент и пригласить всех любителей футбола и футбольной аналитики в свой второй Telegram-канал Артета позвонит
Канал будет полностью посвящен футбольной аналитике:
- Python для анализа футбольных данных
- Анализ футбольных матчей
- Анализ Fantasy EPL
- Мысли о футболе человека, который никогда не играл в профессиональный футбол, но хочет туда попасть
Если вам интересна эта тема подписывайтесь, будем вместе понимать футбол по новому
Telegram
Артета позвонит
Канал Рената Алимбекова (@alimbekovkz) про футбол и футбольную аналитику. Анализ Fantasy EPL и футбольных матчей.
Недавно беседовал с моим подписчиком про АБ-тесты и их влиянии на бизнес. Родион опытный ML-инженер, уже давно подписан на мой канал и недавно поделился своим мануалом по АБ-тестам. У него есть небольшой канал, где рассказывает про будни ML-инженера, работу и разные забавные моменты. Рекомендую посмотреть, скоро планирует серию постов про MLOps. Канал здесь
Telegram
Заметки дата-сатаниста
Про повседневность ML инженера, мотивацию, вызовы, работу с данными и истории из жизни.
Forwarded from Заметки дата-сатаниста
AB-тесты в несколько строк кода?
Помню как тратил временя на дизайн АБ-теста и в голову все время шла идея, что механики расчетов можно оформить в библиотеку. Команда Big Data МТС в конце 2022 года выложила в open source такую библиотеку, уже поставил им звезду.
Подготовил #мануал по расчету размера датасета с использованием этой крутой библиотеки, которая называется ambrosia.
В мануале для понижения дисперсии применилCUPED с несколькими ковариатами . Да, библиотека и в такое умеет.
🔗 Вот ссылка на колаб с кодом.
А что ты используешь для дизайна АБ-теста? Может есть еще более крутая либа?
Помню как тратил временя на дизайн АБ-теста и в голову все время шла идея, что механики расчетов можно оформить в библиотеку. Команда Big Data МТС в конце 2022 года выложила в open source такую библиотеку, уже поставил им звезду.
Подготовил #мануал по расчету размера датасета с использованием этой крутой библиотеки, которая называется ambrosia.
В мануале для понижения дисперсии применил
🔗 Вот ссылка на колаб с кодом.
А что ты используешь для дизайна АБ-теста? Может есть еще более крутая либа?
Google
ambrosia.ipynb
Colaboratory notebook
Группа разработчиков, имевшая доступ к GitHub Copilot, смогла выполнить задачу на 55,8 % быстрее, чем контрольная группа.
Теперь каждый инженерный отдел должен попробовать применить его в своей работе.
Ссылка на статью
Я уже начал его потихоньку использовать. А вы?
Теперь каждый инженерный отдел должен попробовать применить его в своей работе.
Ссылка на статью
Я уже начал его потихоньку использовать. А вы?
🎉🇰🇿 Великолепные новости для казахского языка и IT-сообщества Казахстана!
Мы с гордостью хотим поделиться с вами нашей разработкой kaz-roberta-conversational
Kaz-RoBERTA-conversational предобучена на 9Gb данных на 2 языках: казахский и русский.
Большое спасибо всей команде за вложенные усилия, знания и время для создания этой модели.
Ссылка на пост
Мы с гордостью хотим поделиться с вами нашей разработкой kaz-roberta-conversational
Kaz-RoBERTA-conversational предобучена на 9Gb данных на 2 языках: казахский и русский.
Большое спасибо всей команде за вложенные усилия, знания и время для создания этой модели.
Ссылка на пост
{kind=link}
Дописал пост о том как стать Machine Learning инженером.
В посте рассмотрел вопросы востребованности, задач, навыков, инструментов, system и ML дизайна.
Дал ссылки на курсы и материалы
Всем приятного чтива
В посте рассмотрел вопросы востребованности, задач, навыков, инструментов, system и ML дизайна.
Дал ссылки на курсы и материалы
Всем приятного чтива
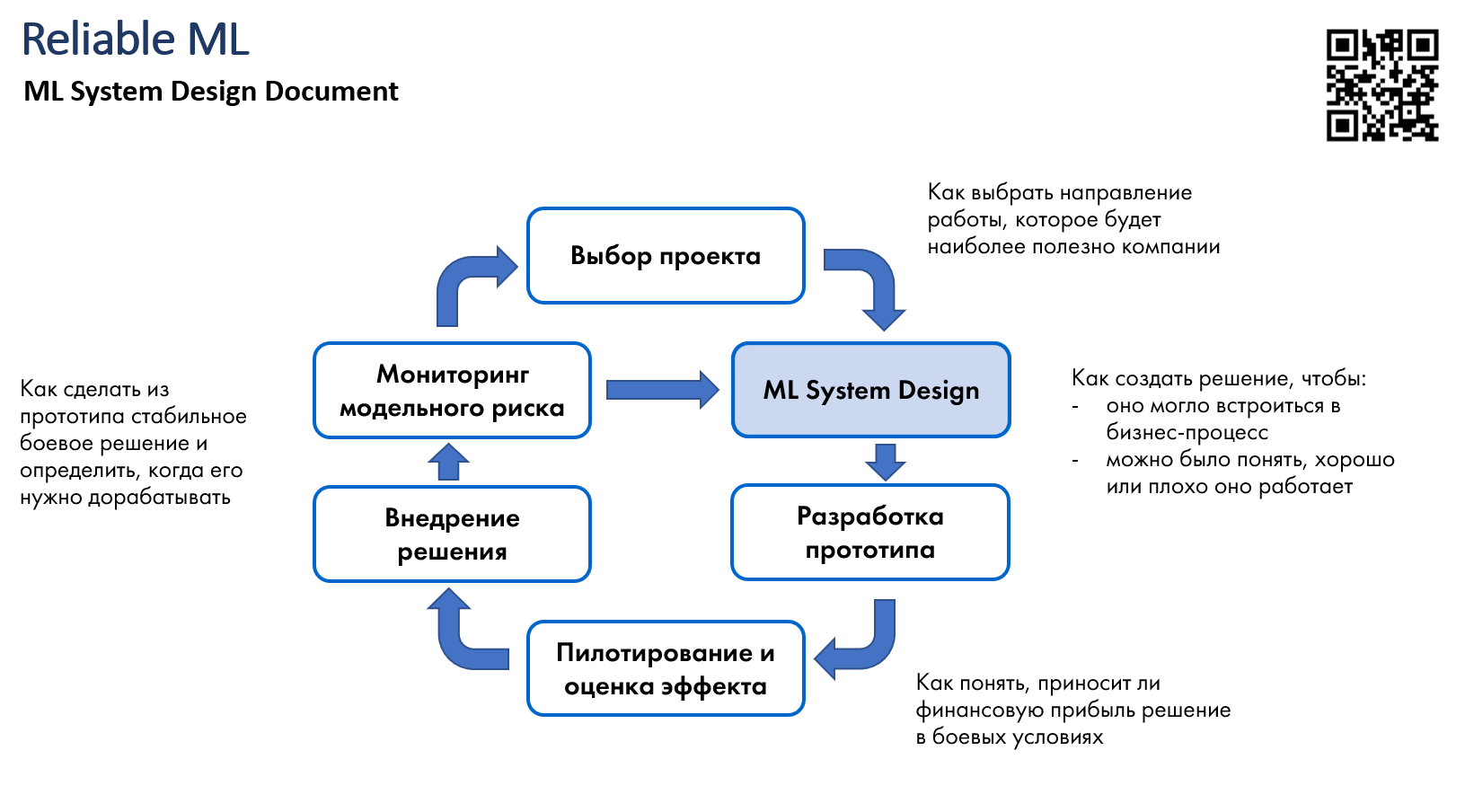
ML System Design Doc
ML System Design документ - это сводный план по построению системы машинного обучения для решения конкретного запроса бизнеса в вашей компании. Его стоит применять на этапе дизайна вашей системы, чтобы в итоге ваше решение было полезным для бизнеса, а именно: могло быть внедрено, работало после внедрения и приносило реальную пользу.
Очень годный документ для структурирования своих мыслей перед реализацией проекта.
Но мне показалось, что он подходит только больших организаций и для долгих проектов > 3 мес.
Если проект не долгий <3 мес и проект не подразумевает большего количества интеграций и разных источников данных, то можно обойтись и схемкой в MIRO
Ссылка: https://github.com/IrinaGoloshchapova/ml_system_design_doc_ru
Лекция по шаблону
ML System Design документ - это сводный план по построению системы машинного обучения для решения конкретного запроса бизнеса в вашей компании. Его стоит применять на этапе дизайна вашей системы, чтобы в итоге ваше решение было полезным для бизнеса, а именно: могло быть внедрено, работало после внедрения и приносило реальную пользу.
Очень годный документ для структурирования своих мыслей перед реализацией проекта.
Но мне показалось, что он подходит только больших организаций и для долгих проектов > 3 мес.
Если проект не долгий <3 мес и проект не подразумевает большего количества интеграций и разных источников данных, то можно обойтись и схемкой в MIRO
Ссылка: https://github.com/IrinaGoloshchapova/ml_system_design_doc_ru
Лекция по шаблону
{kind=link}
Всем привет, мы тут зарелизили датасет для казахского языка из открытых источников, которые не требуют реквеста плюс добавили своих эксклюзивные данные: книги и новости
Итого 25GB , 25млн текстов (22 млн на казахском, 3 млн новости на русском)
https://huggingface.co/datasets/kz-transformers/multidomain-kazakh-dataset
Итого 25GB , 25млн текстов (22 млн на казахском, 3 млн новости на русском)
https://huggingface.co/datasets/kz-transformers/multidomain-kazakh-dataset
huggingface.co
kz-transformers/multidomain-kazakh-dataset · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
#подборка
Всем привет 🚀! За несколько последних дней на канале добавилось много новых подписчиков. Рад вас приветствовать на канале. Канал активно развивается, пробую разные форматы и тематики.
Для всех подписчиков и особенно для тех кто к нам присоединился недавно публикую подборку старых постов. Надеюсь это поможет с навигацией и удобным поиском информации на канале.
Пишете в комментариях о чём было бы интересно почитать.🗣️
👨🏻💻 Про курсы и обучение хэштег #course
Как освоить Data Science — личный опыт
Прокачиваемся до computer vision researcher
Как стать Machine Learning Engineer
🚊 Production хэштег #production
Machine learning в продакшн — Flask REST API
Streamlit - быстрый способ создать приложение для работы с данными
Chalice - фреймворк для написания бессерверных приложений на Python
BentoML
👍 Полезное хэштег #полезно
Visual Studio Code для Data Science
Тестовые задания от разных компаний, на позицию, связанную с Data Scientist
Пост в блоге про выбор логирования в Python
⚒️ Много разных интересных python библиотек хэштег #library
albumentations - Библиотека быстрых аугментаций изображений
Dostoevsky - Библиотека анализ тональности текста для русского языка
Newspaper3k - библиотека для извлечения метаданных новостей, полных текстов и статей
scikit-uplift - это модуль Python для классических подходов к моделированию uplift, построенный на основе scikit-learn
SHAP (SHapley Additive exPlanations)
Great Expectations библиотека, которая помогает тестировать данные
Evidently- интерактивные отчеты для анализа моделей машинного обучения во время проверки или мониторинга в продакшене
📝 Подборки
Основы Python
Статистический анализ данных
Pandas и А/Б тесты
Сбор и хранение данных
👩🔬 Еще отдельно хочу рассказать про свой мини курс , где вы изучите основы анализа медицинских изображений с помощью Python. Вы будете изучать КТ и рентген снимки, сегментировать области изображения и проводить анализ метаданных. Стоимость 500р.
А еще я написал буклеты по подготовке к к Data Science интервью:
- Data Science Interview Guide (на англ. языке) по промокоду BLOG скидка 2 $
- Руководство по подготовке к Data Science интервью(на рус. языке) о промокоду BLOG скидка 2 $
Всем привет 🚀! За несколько последних дней на канале добавилось много новых подписчиков. Рад вас приветствовать на канале. Канал активно развивается, пробую разные форматы и тематики.
Для всех подписчиков и особенно для тех кто к нам присоединился недавно публикую подборку старых постов. Надеюсь это поможет с навигацией и удобным поиском информации на канале.
Пишете в комментариях о чём было бы интересно почитать.🗣️
👨🏻💻 Про курсы и обучение хэштег #course
Как освоить Data Science — личный опыт
Прокачиваемся до computer vision researcher
Как стать Machine Learning Engineer
🚊 Production хэштег #production
Machine learning в продакшн — Flask REST API
Streamlit - быстрый способ создать приложение для работы с данными
Chalice - фреймворк для написания бессерверных приложений на Python
BentoML
👍 Полезное хэштег #полезно
Visual Studio Code для Data Science
Тестовые задания от разных компаний, на позицию, связанную с Data Scientist
Пост в блоге про выбор логирования в Python
⚒️ Много разных интересных python библиотек хэштег #library
albumentations - Библиотека быстрых аугментаций изображений
Dostoevsky - Библиотека анализ тональности текста для русского языка
Newspaper3k - библиотека для извлечения метаданных новостей, полных текстов и статей
scikit-uplift - это модуль Python для классических подходов к моделированию uplift, построенный на основе scikit-learn
SHAP (SHapley Additive exPlanations)
Great Expectations библиотека, которая помогает тестировать данные
Evidently- интерактивные отчеты для анализа моделей машинного обучения во время проверки или мониторинга в продакшене
📝 Подборки
Основы Python
Статистический анализ данных
Pandas и А/Б тесты
Сбор и хранение данных
👩🔬 Еще отдельно хочу рассказать про свой мини курс , где вы изучите основы анализа медицинских изображений с помощью Python. Вы будете изучать КТ и рентген снимки, сегментировать области изображения и проводить анализ метаданных. Стоимость 500р.
А еще я написал буклеты по подготовке к к Data Science интервью:
- Data Science Interview Guide (на англ. языке) по промокоду BLOG скидка 2 $
- Руководство по подготовке к Data Science интервью(на рус. языке) о промокоду BLOG скидка 2 $
Пристанище Дата Сайентиста pinned «#подборка Всем привет 🚀! За несколько последних дней на канале добавилось много новых подписчиков. Рад вас приветствовать на канале. Канал активно развивается, пробую разные форматы и тематики. Для всех подписчиков и особенно для тех кто к нам присоединился…»
CAP6412 Advanced Computer Vision - Spring 2023
Скинули мне тут весьма интересный курс по Advanced Computer Vision.
В курсе можно познакомиться с новомодными штуковинами типо:
- Diffusion Models
- DALL-E-2
- Stable Diffusion
- Image Super-Resolution
- RePaint
И многое другое
Ссылка
Скинули мне тут весьма интересный курс по Advanced Computer Vision.
В курсе можно познакомиться с новомодными штуковинами типо:
- Diffusion Models
- DALL-E-2
- Stable Diffusion
- Image Super-Resolution
- RePaint
И многое другое
Ссылка
Наткнулся на один интересный репозиторий с общей структурой папок для Data Science проекта.
Репозиторий также содержит шаблоны для различных документов, которые рекомендуется заполнять.
Например:
- папка для хранения сэмплов данных
- архитектура системы
- словари данных
- отчеты, EDA
- документы по управлению проектом и планированию
- презентации
- отчеты по результатам baseline моделей и моделирования для прода
Model Report в целом выглядит как полезный документ. Он может содержать:
- определение таргета
- какой был input
- какая модель была построена?
- перечень гиперпараметров
- метрики модели
- важность фичей
- заключение
Ссылка
Репозиторий также содержит шаблоны для различных документов, которые рекомендуется заполнять.
Например:
- папка для хранения сэмплов данных
- архитектура системы
- словари данных
- отчеты, EDA
- документы по управлению проектом и планированию
- презентации
- отчеты по результатам baseline моделей и моделирования для прода
Model Report в целом выглядит как полезный документ. Он может содержать:
- определение таргета
- какой был input
- какая модель была построена?
- перечень гиперпараметров
- метрики модели
- важность фичей
- заключение
Ссылка
Хочу поделиться каналом своего давнего знакомого. Он делает очень крутой контент про разработку интернет-продуктов и сейчас работает над AI стартапом и делиться этим в канале.
Продукторий Владимира Меркушева — авторский канал о разработке интернет-продуктов и digital-маркетинге.
Владимир более 15 лет работает менеджером продукта: раньше — в Авито и Яндексе, сейчас — в OLX Europe. В Продуктории делится собственным опытом и ссылками на полезные ресурсы.
Материалы помогут научиться самостоятельно распознавать провальные гипотезы, говорить со своими продактами на одном языке и эффективно управлять командой.
Начать знакомство с каналом советую с этих постов:
✔️Памятка «Как продакты нанимают продактов» https://www.tg-me.com/vladimir_merkushev/1848
✔️Про тестирование сложных гипотез через fake door подход https://www.tg-me.com/vladimir_merkushev/872
✔️Советы при выборе бизнес модели и критерии оценки https://www.tg-me.com/vladimir_merkushev/990
Подписывайтесь и смотрите на мир глазами менеджера продукта → @vladimir_merkushev
Продукторий Владимира Меркушева — авторский канал о разработке интернет-продуктов и digital-маркетинге.
Владимир более 15 лет работает менеджером продукта: раньше — в Авито и Яндексе, сейчас — в OLX Europe. В Продуктории делится собственным опытом и ссылками на полезные ресурсы.
Материалы помогут научиться самостоятельно распознавать провальные гипотезы, говорить со своими продактами на одном языке и эффективно управлять командой.
Начать знакомство с каналом советую с этих постов:
✔️Памятка «Как продакты нанимают продактов» https://www.tg-me.com/vladimir_merkushev/1848
✔️Про тестирование сложных гипотез через fake door подход https://www.tg-me.com/vladimir_merkushev/872
✔️Советы при выборе бизнес модели и критерии оценки https://www.tg-me.com/vladimir_merkushev/990
Подписывайтесь и смотрите на мир глазами менеджера продукта → @vladimir_merkushev
Telegram
Продукторий Владимира Меркушева
Взгляд на мир глазами менеджера продукта. Работаю в управлении продуктами уже более 8 лет (Kolesa Group, Avito, Yandex, OLX). Пишу о собственном опыте, делюсь полезными ссылками, делаю фото-репортажи из офисов IT компаний. Живу в Лиссабоне. @mervlad
Продуктовый подход
Сегодня пост не про Data Science, а про продуктовых подход. Сейчас я решил сделать небольшой уклон в сторону Product Manager's Skill.
Вот несколько источников, что можно почитать/посмотреть/пройти курсы:
· ProductSense
· ProductStar
· https://skillsetter.io/
· Gopractice – онлайн симулятор - упор на продуктовую аналитику, если в бюджете вашей компании есть бюджет – очень рекомендую
- Читаем книгу «Спроси маму»
- Статья на Go Practice о проверке гипотез ценности без разработки:
- Основы Customer Development. Иван Замесин
- Статья о Дизайн Мышлении
- Тест на оценку навыков в управлении продуктом. Писал о нем ранее
Всем успешных продуктов!
Сегодня пост не про Data Science, а про продуктовых подход. Сейчас я решил сделать небольшой уклон в сторону Product Manager's Skill.
Вот несколько источников, что можно почитать/посмотреть/пройти курсы:
· ProductSense
· ProductStar
· https://skillsetter.io/
· Gopractice – онлайн симулятор - упор на продуктовую аналитику, если в бюджете вашей компании есть бюджет – очень рекомендую
- Читаем книгу «Спроси маму»
- Статья на Go Practice о проверке гипотез ценности без разработки:
- Основы Customer Development. Иван Замесин
- Статья о Дизайн Мышлении
- Тест на оценку навыков в управлении продуктом. Писал о нем ранее
Всем успешных продуктов!
В этой небольшой заметке попробую соединить свои две страсти - футбол и Data Science.
Например рассмотрим задачу трэкинга игроков:
- 2 место SoccerNet: https://arxiv.org/pdf/2211.13481.pdf
- ByteTrack : https://github.com/ifzhang/ByteTrack
- Обзор что вообще такое трекинг: https://habr.com/ru/companies/recognitor/articles/505694/
- DeepOCSort - SOTA 2023: https://arxiv.org/abs/2302.11813
Action recognition:
- Введение в action recognition: https://habr.com/ru/companies/recognitor/articles/647343/
- Довольно свежий обзор современного положения дел: https://arxiv.org/pdf/2208.03775.pdf
К сожалению не нашёл по футболу kaggle соревнований, но за то было круто соревнование по детекции столкновение игроков в американском футболе:
- решение часть 1: https://deepschool-pro.notion.site/Kaggle-NFL-Player-Contact-Detection-1-c88d8e50dc89408b8fe83fe776a65d2b
-решение часть 2: https://deepschool-pro.notion.site/Kaggle-NFL-Player-Contact-Detection-2-4e123d37bddf41089fd28bf4b377343b
Всем хорошего чтения
Например рассмотрим задачу трэкинга игроков:
- 2 место SoccerNet: https://arxiv.org/pdf/2211.13481.pdf
- ByteTrack : https://github.com/ifzhang/ByteTrack
- Обзор что вообще такое трекинг: https://habr.com/ru/companies/recognitor/articles/505694/
- DeepOCSort - SOTA 2023: https://arxiv.org/abs/2302.11813
Action recognition:
- Введение в action recognition: https://habr.com/ru/companies/recognitor/articles/647343/
- Довольно свежий обзор современного положения дел: https://arxiv.org/pdf/2208.03775.pdf
К сожалению не нашёл по футболу kaggle соревнований, но за то было круто соревнование по детекции столкновение игроков в американском футболе:
- решение часть 1: https://deepschool-pro.notion.site/Kaggle-NFL-Player-Contact-Detection-1-c88d8e50dc89408b8fe83fe776a65d2b
-решение часть 2: https://deepschool-pro.notion.site/Kaggle-NFL-Player-Contact-Detection-2-4e123d37bddf41089fd28bf4b377343b
Всем хорошего чтения
Стань экспертом в Machine Learning и MLOps!
Всем привет. Я с недавних пор стал партнером и преподавателем в Risoma School. И уже в сентябре стартуют два курса, где вы сможете прокачать навыки для проектов машинного обучения:
1. MLOps для Data Science и разработки ML моделей - курс для Data Scientists & Analytics, для эффективной работы с экспериментами, моделями и подготовки production решений c FastAPI и Airflow.
2. MLOps для Batch Scoring: автоматизация пайплайнов и CI/CD c DVC, MLflow и Airflow - курс для Machine Learning, Data и DevOps инженеров.
На курсах вы научитесь:
▪️ Управлять экспериментами и жизненным циклом моделей
▪️ Работать с продвинутыми сценариями версионирования данных и моделей
▪️ Эффективно использовать Git и следовать Git-flow в проектах
▪️ Автоматизировать процессы доставки моделей в production, сборку и тестирования решений
▪️ Настраивать мониторинг работы моделей и данных в production
▪️ Эффективно работать с Airflow, DVD, Evidently, MLflow, FastAPI, Grafana, Git, Docker, GitLab, GitLab CI
В программе курсов лекции от экспертов ML в банкинге, MedTech, AdTech, Big Data.
Делюсь с вами промокодом, с которым вы получите скидку 10% на любой курс: "FRIEND10" !
Выбрать курс со скидкой: тут.
Всем привет. Я с недавних пор стал партнером и преподавателем в Risoma School. И уже в сентябре стартуют два курса, где вы сможете прокачать навыки для проектов машинного обучения:
1. MLOps для Data Science и разработки ML моделей - курс для Data Scientists & Analytics, для эффективной работы с экспериментами, моделями и подготовки production решений c FastAPI и Airflow.
2. MLOps для Batch Scoring: автоматизация пайплайнов и CI/CD c DVC, MLflow и Airflow - курс для Machine Learning, Data и DevOps инженеров.
На курсах вы научитесь:
▪️ Управлять экспериментами и жизненным циклом моделей
▪️ Работать с продвинутыми сценариями версионирования данных и моделей
▪️ Эффективно использовать Git и следовать Git-flow в проектах
▪️ Автоматизировать процессы доставки моделей в production, сборку и тестирования решений
▪️ Настраивать мониторинг работы моделей и данных в production
▪️ Эффективно работать с Airflow, DVD, Evidently, MLflow, FastAPI, Grafana, Git, Docker, GitLab, GitLab CI
В программе курсов лекции от экспертов ML в банкинге, MedTech, AdTech, Big Data.
Делюсь с вами промокодом, с которым вы получите скидку 10% на любой курс: "
Выбрать курс со скидкой: тут.
risoma.ru
Risoma School
Школа Risoma - курсы по автоматизации и инженерным практикам в машинном обучении
Написание unit тестов и тестирование в Machine Learning
Сегодня хочу рассказать вам о написании unit тестов и тестировании кода для Data Science.
Лично я начинал изучать эту тему со статей и попыток вникнуть как пишутся тесты для библиотеки albumentations.
Вот статьи и документация:
Writing tests
test_core.py
Writing tests for the Albumentations library with pytest
Далее рекомендую почитать следующие статьи:
Testing Machine Learning Systems: Code, Data and Models
How to unit test machine learning code - про тестирование нейронок
How to Trust Your Deep Learning Code - очень крутая статья про отладку нейронок
How to Test Machine Learning Code and Systems - а вот тут про тестирование для табличных данных. Например в статье есть про тесты, которые проверяют правильность нашей написанной логики. Например, находится ли вероятность классификации в диапазоне от 0 до 1? Или тесты после обучения проверяют, ожидается ли изученная логика.
Minimal examples of machine learning tests for implementation, behaviour, and performance - репозиторий из статьи выше
Сегодня хочу рассказать вам о написании unit тестов и тестировании кода для Data Science.
Лично я начинал изучать эту тему со статей и попыток вникнуть как пишутся тесты для библиотеки albumentations.
Вот статьи и документация:
Writing tests
test_core.py
Writing tests for the Albumentations library with pytest
Далее рекомендую почитать следующие статьи:
Testing Machine Learning Systems: Code, Data and Models
How to unit test machine learning code - про тестирование нейронок
How to Trust Your Deep Learning Code - очень крутая статья про отладку нейронок
How to Test Machine Learning Code and Systems - а вот тут про тестирование для табличных данных. Например в статье есть про тесты, которые проверяют правильность нашей написанной логики. Например, находится ли вероятность классификации в диапазоне от 0 до 1? Или тесты после обучения проверяют, ожидается ли изученная логика.
Minimal examples of machine learning tests for implementation, behaviour, and performance - репозиторий из статьи выше
Сейчас мне приходится работать над очень разными проектами из разных областей.
Например: писать курс, делать примеры кода для еще одного курса, строить модели для разных проектов.
И в таком ритме работы очень важно быть сфокусированным на решении задач. И в этом очень помогает известный Метод помидора.
Но сложность такого подхода, что когда долго не видно прогресса или не понятен вклад каждого дня, то страдает мотивация.
Что помогает мне?
1. Я фиксирую всё работу в toggl. Помогает понять сколько времени на каком проекте и этапе проекте я потратил и какой результат достигнут.
2. Комитить в гит вашего проекта каждый день, даже по маленькому изменению. Так прогресс будет заметен и вы не должны будете потерять мотивацию.
Надеюсь заметка вам поможет быть более сфокусированным на ваших задачах и целях
Например: писать курс, делать примеры кода для еще одного курса, строить модели для разных проектов.
И в таком ритме работы очень важно быть сфокусированным на решении задач. И в этом очень помогает известный Метод помидора.
Но сложность такого подхода, что когда долго не видно прогресса или не понятен вклад каждого дня, то страдает мотивация.
Что помогает мне?
1. Я фиксирую всё работу в toggl. Помогает понять сколько времени на каком проекте и этапе проекте я потратил и какой результат достигнут.
2. Комитить в гит вашего проекта каждый день, даже по маленькому изменению. Так прогресс будет заметен и вы не должны будете потерять мотивацию.
Надеюсь заметка вам поможет быть более сфокусированным на ваших задачах и целях
Бесплатный курс по использованию chatGPT
Понимаю, что с таким постом я опоздал на пару месяцев, но всё же. Я активно юзаю chatGPT в работе, но с недавних пор решил сделать продукт на его базе.
И вот тут курс ChatGPT Prompt Engineering for Developers мне очень помог.
Начну с того, что желательно иметь для экспериментов Jupyter ноутбук со своим проектов и применять полученные навыки сразу в нём.
Очень круто видеть как новые навыки меняют предыдущий результат и делают его лучше
Но если у вас нет своего проекта на базе chatGPT, то в курсе на каждую лекцию есть свой Jupyter ноутбук в котором можно удобно поиграться.
Финальный проект - бот, принимающего заказы пиццы.
Что нового я узнал и что мне понравилось:
- быстрый курс, за пару часов можно пройти даже с учетом применения новых фишек в своем проекте
- все трюки очень практичные и упрощают жизнь в использовании chatGPT
- я не знал, что фразу, которую на вход желательно обернуть в символы и указать на это chatGPT. Позволяет chatGPT смотреть туда куда вам нужно
- никогда не указывал chatGPT формат выхода, как оказалось очень удобно для моего продукта возвращать ответ в формате JSON
- благодаря курсу узнал про параметр temperature. Это степень случайности выходных данных модели
- также мне очень пригодился хак с указанием написать пошаговую инструкцию
- остальное было более банально: суммаризация, анализ тональности, перевод, пересказ текста и т.д.
Если вы еще не работали с API chatGPT, то рекомендую этот курс
Понимаю, что с таким постом я опоздал на пару месяцев, но всё же. Я активно юзаю chatGPT в работе, но с недавних пор решил сделать продукт на его базе.
И вот тут курс ChatGPT Prompt Engineering for Developers мне очень помог.
Начну с того, что желательно иметь для экспериментов Jupyter ноутбук со своим проектов и применять полученные навыки сразу в нём.
Очень круто видеть как новые навыки меняют предыдущий результат и делают его лучше
Но если у вас нет своего проекта на базе chatGPT, то в курсе на каждую лекцию есть свой Jupyter ноутбук в котором можно удобно поиграться.
Финальный проект - бот, принимающего заказы пиццы.
Что нового я узнал и что мне понравилось:
- быстрый курс, за пару часов можно пройти даже с учетом применения новых фишек в своем проекте
- все трюки очень практичные и упрощают жизнь в использовании chatGPT
- я не знал, что фразу, которую на вход желательно обернуть в символы и указать на это chatGPT. Позволяет chatGPT смотреть туда куда вам нужно
- никогда не указывал chatGPT формат выхода, как оказалось очень удобно для моего продукта возвращать ответ в формате JSON
- благодаря курсу узнал про параметр temperature. Это степень случайности выходных данных модели
- также мне очень пригодился хак с указанием написать пошаговую инструкцию
- остальное было более банально: суммаризация, анализ тональности, перевод, пересказ текста и т.д.
Если вы еще не работали с API chatGPT, то рекомендую этот курс
www.deeplearning.ai
ChatGPT Prompt Engineering for Developers - DeepLearning.AI
Level up your use of LLMs with prompt engineering best practices. Learn to automate workflows, chain LLM calls, and build a custom chatbot.