
Forwarded from Системный Блокъ
Семантические сети: как представить значения слов в виде графа
Команда компьютерных лингвистов из школы лингвистики НИУ ВШЭ, университета Тренто и университета Осло под руководством Андрея Кутузова представила на конференции AIST библиотеку vec2graph для Python. Vec2graph умеет визуализировать семантическую близость слов в виде сети. Информацию о близости слов vec2graph получает из векторной семантической модели.
«Системный Блокъ» уже рассказывал о том, что в основе дистрибутивной семантики — простая идея: близкие по значению слова будут встречаться в похожих контекстах. Чтобы передать знание о контекстной близости слов компьютеру, ученые и инженеры обучают векторные семантические модели — например, с помощью word2vec.
Но как отображать семантические близости из векторной модели так, чтобы они снова стали понятны человеку? Самый простой вариант — выдавать для любого слова столбик ближайших к нему «семантических ассоциатов».
Можно попытаться сжать многомерное векторное пространство модели обратно в двумерное. Алгоритмов такого снижения размерности (PCA, MDS, t-SNE) множество.
Третья альтернатива — использовать сети (они же графы). Для каждого слова можно строить сеть из его семантических ассоциатов. При этом сам показатель близости отображать, например, через длину линии: чем короче связь — тем ближе слово в векторной модели. Именно такие визуализации делает vec2graph.
https://sysblok.ru/nlp/semanticheskie-seti-kak-predstavit-znachenija-slov-v-vide-grafa/
Команда компьютерных лингвистов из школы лингвистики НИУ ВШЭ, университета Тренто и университета Осло под руководством Андрея Кутузова представила на конференции AIST библиотеку vec2graph для Python. Vec2graph умеет визуализировать семантическую близость слов в виде сети. Информацию о близости слов vec2graph получает из векторной семантической модели.
«Системный Блокъ» уже рассказывал о том, что в основе дистрибутивной семантики — простая идея: близкие по значению слова будут встречаться в похожих контекстах. Чтобы передать знание о контекстной близости слов компьютеру, ученые и инженеры обучают векторные семантические модели — например, с помощью word2vec.
Но как отображать семантические близости из векторной модели так, чтобы они снова стали понятны человеку? Самый простой вариант — выдавать для любого слова столбик ближайших к нему «семантических ассоциатов».
Можно попытаться сжать многомерное векторное пространство модели обратно в двумерное. Алгоритмов такого снижения размерности (PCA, MDS, t-SNE) множество.
Третья альтернатива — использовать сети (они же графы). Для каждого слова можно строить сеть из его семантических ассоциатов. При этом сам показатель близости отображать, например, через длину линии: чем короче связь — тем ближе слово в векторной модели. Именно такие визуализации делает vec2graph.
https://sysblok.ru/nlp/semanticheskie-seti-kak-predstavit-znachenija-slov-v-vide-grafa/
RusVectōrēs
Скоро ждите в веб-интерфейсе RusVectōrēs!
Всем привет! Месяц назад мы писали о библиотеке графовой визуализации векторных пространств vec2graph.
Как и было обещано, сегодня мы представляем интеграцию этих визуализаций в веб-интерфейс RusVectōrēs и во фреймворк WebVectors. Динамические интерактивные графы ближайших соседей доступны на главной странице сайта и на страницах отдельных слов (например, тут).
Они могут быть полезны для анализа кластеров соседей у многозначных слов и просто для демонстрации семантических сетей в естественных языках.
Интеграция vec2graph в веб-интерфейс проделана силами нашего волонтёра Анастасии Лисицыной, за что ей большое спасибо!
Как и было обещано, сегодня мы представляем интеграцию этих визуализаций в веб-интерфейс RusVectōrēs и во фреймворк WebVectors. Динамические интерактивные графы ближайших соседей доступны на главной странице сайта и на страницах отдельных слов (например, тут).
Они могут быть полезны для анализа кластеров соседей у многозначных слов и просто для демонстрации семантических сетей в естественных языках.
Интеграция vec2graph в веб-интерфейс проделана силами нашего волонтёра Анастасии Лисицыной, за что ей большое спасибо!
PyPI
vec2graph
Mini-library for producing graph visualizations from embedding models
Мы давно не рассказывали вам об исследованиях, которые в качестве инструментов используют модели RusVectōrēs. Сегодня мы возобновим эту славную традицию и познакомим вас со статьей Полины Паничевой и Татьяны Литвиновой "Semantic Coherence in Schizophrenia in Russian Written Texts". Это исследование использует методы author profiling по отношению к текстам людей, страдающих шизофренией. Главный вопрос исследования - можно ли отличить тексты людей, больных шизофренией, от текстов здоровых людей? Основной признак, по которому сравниваются данные - semantic coherence (семантическая связность).
Семантическая связность определяется как средний коэффициент косинусной близости двух векторов слов, подсчитанный для определенных n-грамм. Например, в предложении "Снесла курочка яичко, да не простое, а золотое" коэффициент семантической связности для триграммы "Снесла курочка яичко" (окно размера 3) подсчитывается как средний коэффициент косинусной близости между векторами слов "снесла" и "курочка", "курочка" и "яичко". Каждый текст характеризуется последовательностью таких коэффициентов для всех n-грамм (в нашем примере выше мы использовали триграммы). Авторы выделяют несколько метрик, с помощью которых можно сравнивать тексты: минимальное и максимальное значения коэффициента семантической связности, среднее значение коэффициента, стандартное отклонение и др. Для вычисления косинусной близости между векторами слов в тексте авторы используют модель RusVectōrēs с идентификатором ruwikiruscorpora_upos_skipgram_300_2_2018.
Исследование показало, что между текстами людей, больных шизофренией, и текстами здоровых людей имеются существенные различия. Авторы добились точности от 0.72 до 0.88 при автоматическом опредлении принадлежности текста к той или иной группе данных. В то же время, анализ результатов для русского языка противоречит исследованиям, проведенным для английского языка. Например, минимальный коэффициент семантической связности оказывается ниже для текстов здоровых людей, в то время как в английском языке прослеживалась обратная тенденция.
В целом, нам кажется, что это интересное исследование демонстрирует, как разнообразны сферы NLP, в которых применимы модели векторной семантики. Успехов авторам, а мы надеемся прочесть ещё множество замечательных статей, где в качестве инструментов используются модели RusVectōrēs!
Семантическая связность определяется как средний коэффициент косинусной близости двух векторов слов, подсчитанный для определенных n-грамм. Например, в предложении "Снесла курочка яичко, да не простое, а золотое" коэффициент семантической связности для триграммы "Снесла курочка яичко" (окно размера 3) подсчитывается как средний коэффициент косинусной близости между векторами слов "снесла" и "курочка", "курочка" и "яичко". Каждый текст характеризуется последовательностью таких коэффициентов для всех n-грамм (в нашем примере выше мы использовали триграммы). Авторы выделяют несколько метрик, с помощью которых можно сравнивать тексты: минимальное и максимальное значения коэффициента семантической связности, среднее значение коэффициента, стандартное отклонение и др. Для вычисления косинусной близости между векторами слов в тексте авторы используют модель RusVectōrēs с идентификатором ruwikiruscorpora_upos_skipgram_300_2_2018.
Исследование показало, что между текстами людей, больных шизофренией, и текстами здоровых людей имеются существенные различия. Авторы добились точности от 0.72 до 0.88 при автоматическом опредлении принадлежности текста к той или иной группе данных. В то же время, анализ результатов для русского языка противоречит исследованиям, проведенным для английского языка. Например, минимальный коэффициент семантической связности оказывается ниже для текстов здоровых людей, в то время как в английском языке прослеживалась обратная тенденция.
В целом, нам кажется, что это интересное исследование демонстрирует, как разнообразны сферы NLP, в которых применимы модели векторной семантики. Успехов авторам, а мы надеемся прочесть ещё множество замечательных статей, где в качестве инструментов используются модели RusVectōrēs!
Анонс от наших коллег:
Мы рады сообщить Вам, что в 2019-2020 году впервые будет проходить соревнование по автоматическому предсказанию гиперонимов для русского языка в рамках 26-й Международной конференции DIALOGUE 2020.
Цель данного соревнования -- автоматически обогатить существующую таксономию (ruWordNet) новыми словами, связав их отношениями гиперонимии с существующими. Для слова, не включенного в тезаурус, необходимо предсказать ранжированный список из 10 синсетов, которые с наибольшей вероятностью могли бы быть гиперонимами для данного слова (гиперонимов может быть больше, чем 1).
Мы полагаем, что современные контекстуальные векторные представления слов, такие как ELMo и BERT, будут особенно эффективны в при поиске гиперонимов, и будем рады увидеть решения, использующие данные подходы (или любые другие) в нашем соревновании. В качестве базовых решений мы предоставим реализации, основанные на дистрибутивной семантике и нейросетевых языковых моделях.
Важные даты:
Начало соревнования: 15 декабря 2019
Публикация тренировочных данных: 15 декабря 2019
Публикация тестовых данных: 31 января 2020
Последний день для отправки решений: 14 февраля 2020
Результаты дорожки: 28 февраля 2020
Контакты для связи с организаторами:
[email protected]
[email protected]
Группа для обсуждения дорожки в Telegram
Мы рады сообщить Вам, что в 2019-2020 году впервые будет проходить соревнование по автоматическому предсказанию гиперонимов для русского языка в рамках 26-й Международной конференции DIALOGUE 2020.
Цель данного соревнования -- автоматически обогатить существующую таксономию (ruWordNet) новыми словами, связав их отношениями гиперонимии с существующими. Для слова, не включенного в тезаурус, необходимо предсказать ранжированный список из 10 синсетов, которые с наибольшей вероятностью могли бы быть гиперонимами для данного слова (гиперонимов может быть больше, чем 1).
Мы полагаем, что современные контекстуальные векторные представления слов, такие как ELMo и BERT, будут особенно эффективны в при поиске гиперонимов, и будем рады увидеть решения, использующие данные подходы (или любые другие) в нашем соревновании. В качестве базовых решений мы предоставим реализации, основанные на дистрибутивной семантике и нейросетевых языковых моделях.
Важные даты:
Начало соревнования: 15 декабря 2019
Публикация тренировочных данных: 15 декабря 2019
Публикация тестовых данных: 31 января 2020
Последний день для отправки решений: 14 февраля 2020
Результаты дорожки: 28 февраля 2020
Контакты для связи с организаторами:
[email protected]
[email protected]
Группа для обсуждения дорожки в Telegram
Всем привет!
На RusVectōrēs появилась новая контекстуализированная ELMo-модель tayga_lemmas_elmo_2048_2019. В отличие от предыдущих, она обучена на большом корпусе Taiga (использовалась лемматизированная версия). Начиная с этого релиза, мы вкладываем в архивы кроме собственно модели в формате HDF5, ещё и исходные TensorFlow-чекпойнты, на случай, если они вам понадобятся (например, если вы собираетесь заниматься language modeling).
Кроме того, в новой модели в два раза больше размерность LSTM (2048x2=4096). Результат налицо: на задаче word sense disambiguation качество (макро-F1 на датасете RUSSE'18) поднялось с 0.91 (модель ruwikiruscorpora_lemmas_elmo_1024_2019) до 0.93. Между прочим, это выше, чем результат RuBERT на той же задаче (0.92), хотя наша модель в два раза легче. Так что BERT побеждает не всегда.
Чтобы не ограничиваться только снятием лексической неоднозначности, мы теперь также тестируем ELMo-модели на задаче детектирования парафразов (фактически - классификация пар документов на три класса). Для этого используется корпус проекта ParaPhraser. Вот F1-метрики наших трёх моделей (и RuBERT для сравнения):
- ruwikiruscorpora_tokens_elmo_1024_2019: 0.55
- ruwikiruscorpora_lemmas_elmo_1024_2019: 0.57
- tayga_lemmas_elmo_2048_2019: 0.54
- ruBERT: 0.35
Интересно, что в этой задаче НКРЯ+Википедия оказывается более полезным обучающим корпусом, чем "Тайга", в отличие от WSD.
Наконец, мы допилили простой код для работы с ELMo-моделями: проект Simple ELMo. С помощью скриптов из этого репозитория вы легко сможете подавать на вход нашим моделям тексты и получать контекстуализированные репрезентации отдельных слов или целых документов. Есть и функции, воспроизводящие нашу оценку на детектировании парафразов. Требуется TensorFlow не ниже 1.15.
С нетерпением ждём ваших комментариев и вопросов!
На RusVectōrēs появилась новая контекстуализированная ELMo-модель tayga_lemmas_elmo_2048_2019. В отличие от предыдущих, она обучена на большом корпусе Taiga (использовалась лемматизированная версия). Начиная с этого релиза, мы вкладываем в архивы кроме собственно модели в формате HDF5, ещё и исходные TensorFlow-чекпойнты, на случай, если они вам понадобятся (например, если вы собираетесь заниматься language modeling).
Кроме того, в новой модели в два раза больше размерность LSTM (2048x2=4096). Результат налицо: на задаче word sense disambiguation качество (макро-F1 на датасете RUSSE'18) поднялось с 0.91 (модель ruwikiruscorpora_lemmas_elmo_1024_2019) до 0.93. Между прочим, это выше, чем результат RuBERT на той же задаче (0.92), хотя наша модель в два раза легче. Так что BERT побеждает не всегда.
Чтобы не ограничиваться только снятием лексической неоднозначности, мы теперь также тестируем ELMo-модели на задаче детектирования парафразов (фактически - классификация пар документов на три класса). Для этого используется корпус проекта ParaPhraser. Вот F1-метрики наших трёх моделей (и RuBERT для сравнения):
- ruwikiruscorpora_tokens_elmo_1024_2019: 0.55
- ruwikiruscorpora_lemmas_elmo_1024_2019: 0.57
- tayga_lemmas_elmo_2048_2019: 0.54
- ruBERT: 0.35
Интересно, что в этой задаче НКРЯ+Википедия оказывается более полезным обучающим корпусом, чем "Тайга", в отличие от WSD.
Наконец, мы допилили простой код для работы с ELMo-моделями: проект Simple ELMo. С помощью скриптов из этого репозитория вы легко сможете подавать на вход нашим моделям тексты и получать контекстуализированные репрезентации отдельных слов или целых документов. Есть и функции, воспроизводящие нашу оценку на детектировании парафразов. Требуется TensorFlow не ниже 1.15.
С нетерпением ждём ваших комментариев и вопросов!
RusVectores
RusVectōrēs: модели
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания
Всем привет! Анонс от наших коллег:
Social Media Mining for Health Application workshop (SMM4H) 2020: Дорожка по извлечению упоминаний побочных эффектов из твитов на русском языке
В этом году впервые будет проходить соревнование по автоматическому извлечению упоминаний о побочных эффектах из текстов твитов на русском языке в рамках SMM4H. SMM4H - это ежегодная встреча исследователей, заинтересованных в автоматических методах сбора, извлечения и анализа текстовых данных социальных сетей по теме медицины. В этом году воркшоп будет проходить совместно с конференцией COLING 2020.
Важные даты:
Публикация тренировочных данных: 15 января 2020
Публикация тестовых данных: 2 апреля 2020
Последний день для отправки решений: 5 апреля 2020
Подача статей с описанием решения: 5 мая 2020
Уведомление о принятии статьи с описанием решения: 10 июня 2020
Финальная версия статей: 30 июня 2020
SMM4H воркшоп: 13 сентября 2020
Для участия в дорожке отправьте письмо организаторам на [email protected] со следующей информацией:
(1) имя
(2) аффилиация
(3) ваша электронная почта
(4) имена и электронные почты участников вашей команды
(5) название команды в системе CodaLab
(6) номер дорожки.
Подробная информация:
https://healthlanguageprocessing.org/smm4h-sharedtask-2020/
Social Media Mining for Health Application workshop (SMM4H) 2020: Дорожка по извлечению упоминаний побочных эффектов из твитов на русском языке
В этом году впервые будет проходить соревнование по автоматическому извлечению упоминаний о побочных эффектах из текстов твитов на русском языке в рамках SMM4H. SMM4H - это ежегодная встреча исследователей, заинтересованных в автоматических методах сбора, извлечения и анализа текстовых данных социальных сетей по теме медицины. В этом году воркшоп будет проходить совместно с конференцией COLING 2020.
Важные даты:
Публикация тренировочных данных: 15 января 2020
Публикация тестовых данных: 2 апреля 2020
Последний день для отправки решений: 5 апреля 2020
Подача статей с описанием решения: 5 мая 2020
Уведомление о принятии статьи с описанием решения: 10 июня 2020
Финальная версия статей: 30 июня 2020
SMM4H воркшоп: 13 сентября 2020
Для участия в дорожке отправьте письмо организаторам на [email protected] со следующей информацией:
(1) имя
(2) аффилиация
(3) ваша электронная почта
(4) имена и электронные почты участников вашей команды
(5) название команды в системе CodaLab
(6) номер дорожки.
Подробная информация:
https://healthlanguageprocessing.org/smm4h-sharedtask-2020/
HLP @ Cedars-Sinai Computational Biomedicine
Social Media Mining for Health Applications (#SMM4H) Shared Task 2020
Call For Participation – Shared Task (Click here for the #SMM4H ’20 Call For Papers – Workshop, or click here for the #SMM4H ’19 Shared Task.) The Social Media Mining for Health Applications (#SMM4…
Как векторные семантические модели используются для отслеживания семантических сдвигов во времени:
Forwarded from Системный Блокъ
Семантические сдвиги и предсказание военных конфликтов — в интервью с Андреем Кутузовым
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
Значение слов постоянно меняется, отражаясь в контекстах. Следом меняются и типичные ассоциации, связанные со словами.
Цифровые методы позволяют отследить эти изменения. Классический пример — слово «cell», которое сначала означало только «тюремную камеру», потом постепенно начало появляться в значении «биологическая клетка», а вот в конце 90-х — начале 2000-х письменные тексты захлестнула волна использования слова «cell» в значении «сотовый телефон».
Системный Блокъ взял интервью у Андрея Кутузова, создателя сайта RusVectōrēs, постдока и сотрудника группы языковых технологий в университете Осло.
О чем мы поговорили в интервью с Андреем:
● о диахронических семантических сдвигах — как изучать изменения значений слов с течением времени.
● о том, как даже простые дистрибутивные модели выявляют тонкие семантические отношения.
● о предсказании вооруженных конфликтов. Оказывается, что семантические сдвиги предшествуют вооруженным конфликтам, а значит, теоретически могут их предсказывать.
https://sysblok.ru/interviews/oblast-v-kotoroj-ja-rabotaju-rozhdaetsja-prjamo-na-glazah/
{kind=link}
На RusVectōrēs временно отключены индивидуальные странички слов (на которые можно попасть, кликнув на слово, например, в списке ближайших соседей).
Причина в том, что кто-то начал неистово обкачивать эти страницы с разных ip-адресов, игнорируя правила из robots.txt. Это серьёзно замедляло работу всего сервиса в целом.
Мы надеемся, что это временная мера. Если вы знаете, кто занимается автоматизированным краулингом RusVectōrēs - пожалуйста, попросите их связаться с нами. Возможно, мы найдём разумное решение.
Причина в том, что кто-то начал неистово обкачивать эти страницы с разных ip-адресов, игнорируя правила из robots.txt. Это серьёзно замедляло работу всего сервиса в целом.
Мы надеемся, что это временная мера. Если вы знаете, кто занимается автоматизированным краулингом RusVectōrēs - пожалуйста, попросите их связаться с нами. Возможно, мы найдём разумное решение.
Индивидуальные страницы слов вернулись к жизни.
Вот, например, страничка слова "спам" в модели, обученной на НКРЯ и Википедии:
https://rusvectores.org/ru/ruwikiruscorpora_upos_skipgram_300_2_2019/%D1%81%D0%BF%D0%B0%D0%BC/
Вот, например, страничка слова "спам" в модели, обученной на НКРЯ и Википедии:
https://rusvectores.org/ru/ruwikiruscorpora_upos_skipgram_300_2_2019/%D1%81%D0%BF%D0%B0%D0%BC/
RusVectores
Слова, семантически связанные с спам
РусВекторес: дистрибутивная семантика для русского языка, веб-интерфейс и модели для скачивания
Кто хочет поразмечать качество кросс-языкового поиска похожих научных статей?
Не знаете, чем ещё занять себя на карантине? 10 000 деталей пазла собираются за полчаса, все курсы на Coursera давно пройдены, а холодильник забит вашими кулинарными шедеврами из гречки? Выход есть: достаточно найти пульт от времени и промотать всё туда, где уже можно гулять по улицам, выпить кофе в любимой кофейне, увидеться с друзьями и отправиться в путешествие! Одна проблема: такого пульта нет ☹️.
Но можно ускорить время, подарив свой час науке 😉 Ничего сложного: достаточно полистать статьи на русском и английском, опубликованные на российских NLP-конференциях, и оценить качество кросс-языкового поиска похожих. Звучит заманчиво? Тогда стучитесь в @RusNLP_bot за спасением или выберите одну или несколько из анкет! А ощутить свой вклад однажды можно будет на сервисе поиска NLP-статей RusNLP.
Не знаете, чем ещё занять себя на карантине? 10 000 деталей пазла собираются за полчаса, все курсы на Coursera давно пройдены, а холодильник забит вашими кулинарными шедеврами из гречки? Выход есть: достаточно найти пульт от времени и промотать всё туда, где уже можно гулять по улицам, выпить кофе в любимой кофейне, увидеться с друзьями и отправиться в путешествие! Одна проблема: такого пульта нет ☹️.
Но можно ускорить время, подарив свой час науке 😉 Ничего сложного: достаточно полистать статьи на русском и английском, опубликованные на российских NLP-конференциях, и оценить качество кросс-языкового поиска похожих. Звучит заманчиво? Тогда стучитесь в @RusNLP_bot за спасением или выберите одну или несколько из анкет! А ощутить свой вклад однажды можно будет на сервисе поиска NLP-статей RusNLP.
RusNLP
RusNLP: Опрос
RusNLP: семантический поиск по научным статьям на российских конференциях в области natural language processing
RusNLP - это поисковик по cтатьям, опубликованным на российских конференциях по компьютерной лингвистике: "Диалог", AIST, AINL. Мы обкачали все NLP-публикации на этих конференциях, начиная с 2001 года, и тщательно разметили статьи по авторам и их аффилиациям. Веб-сервис позволяет искать публикации по вашим запросам и отображает списки статей на схожую тему. Результаты поиска можно фильтровать по любому сочетанию авторов, аффилиаций, годов и конференций.
ВАЖНО: Сегодня мы выкатили обновленную базу данных, включающую статьи, опубликованные в 2019 году. Теперь у нас 516 публикаций, 1182 уникальных автора и 250 уникальных аффилиаций. Над этим релизом работали Андрей Кутузов (Университет Осло) и Ирина Никишина (Сколтех).
Кроме того, была проведена огромная работа по ручной коррекции метаданных публикаций. Имена авторов и названия аффилиаций в статьях часто пишут очень по-разному: движок должен понимать, что "Lomonosov Moscow State University, Moscow, Russian Federation" и "MSU, Moscow, Russia" являются одной и той же аффилиацией. И он это понимает, так что результаты поиска по метаданным стали теперь гораздо точнее. Вот, например, все публикации сотрудников и студентов Вышки.
Кстати, огромную помощь в разметке метаданных оказали как раз студенты вышкинской магистратуры по компьютерной лингвистике: Анна Сафарян, Петр Фильченков и Weijia Yan.
Мы надеемся, что RusNLP окажется полезен в вашей научной работе!
ЕЩЁ БОЛЕЕ ВАЖНО: сейчас RusNLP работает только с англоязычными статьями. Это не проблема для AIST и AINL, поскольку на этих конференциях почти все статьи на английском. Однако на "Диалоге" регулярно появляются русскоязычные публикации (особенно это верно для 2000-х годов). Сейчас мы работаем над преодолением этого ограничения и тестируем различные варианты кросс-языкового поиска ближайших статей к статье запроса.
На самом деле, мы уже реализовали целых 4 алгоритма такого поиска, но теперь нам нужна ваша помощь! Чтобы определить, какой из них лучше, необходимо разметить их результаты по степени релевантности. Мы не можем просто отдать эту разметку в Яндекс.Толоку: для оценки тематической схожести академических публикаций необходима всё-таки некоторая квалификация. Мы уверены, что если вы читаете этот текст, то у вас такая квалификация есть. Если вы готовы инвестировать полчаса своего времени в улучшение кросс-языкового поиска на RusNLP, то вот видео-тьюториал и инструкции по разметке. Также можно постучаться нашему боту, и он автоматически выдаст вам статьи на разметку. Большое спасибо!
RusNLP
ВАЖНО: Сегодня мы выкатили обновленную базу данных, включающую статьи, опубликованные в 2019 году. Теперь у нас 516 публикаций, 1182 уникальных автора и 250 уникальных аффилиаций. Над этим релизом работали Андрей Кутузов (Университет Осло) и Ирина Никишина (Сколтех).
Кроме того, была проведена огромная работа по ручной коррекции метаданных публикаций. Имена авторов и названия аффилиаций в статьях часто пишут очень по-разному: движок должен понимать, что "Lomonosov Moscow State University, Moscow, Russian Federation" и "MSU, Moscow, Russia" являются одной и той же аффилиацией. И он это понимает, так что результаты поиска по метаданным стали теперь гораздо точнее. Вот, например, все публикации сотрудников и студентов Вышки.
Кстати, огромную помощь в разметке метаданных оказали как раз студенты вышкинской магистратуры по компьютерной лингвистике: Анна Сафарян, Петр Фильченков и Weijia Yan.
Мы надеемся, что RusNLP окажется полезен в вашей научной работе!
ЕЩЁ БОЛЕЕ ВАЖНО: сейчас RusNLP работает только с англоязычными статьями. Это не проблема для AIST и AINL, поскольку на этих конференциях почти все статьи на английском. Однако на "Диалоге" регулярно появляются русскоязычные публикации (особенно это верно для 2000-х годов). Сейчас мы работаем над преодолением этого ограничения и тестируем различные варианты кросс-языкового поиска ближайших статей к статье запроса.
На самом деле, мы уже реализовали целых 4 алгоритма такого поиска, но теперь нам нужна ваша помощь! Чтобы определить, какой из них лучше, необходимо разметить их результаты по степени релевантности. Мы не можем просто отдать эту разметку в Яндекс.Толоку: для оценки тематической схожести академических публикаций необходима всё-таки некоторая квалификация. Мы уверены, что если вы читаете этот текст, то у вас такая квалификация есть. Если вы готовы инвестировать полчаса своего времени в улучшение кросс-языкового поиска на RusNLP, то вот видео-тьюториал и инструкции по разметке. Также можно постучаться нашему боту, и он автоматически выдаст вам статьи на разметку. Большое спасибо!
RusNLP
RusNLP
RusNLP: семантический поиск по научным статьям на российских конференциях в области natural language processing
Представляем ещё один наш проект.
ShiftRy - это веб-сервис для анализа диахронических изменений в употреблении слов в российских новостях. Он назван в честь покемона Шифтри (англ. shift - «сдвиг»), внешне похожего на японских тэнгу. Используются дистрибутивные модели, обученные на большом корпусе русскоязычных новостных текстов, опубликованных в период с 2010 по 2020 год. Все эти эмбеддинги доступны для скачивания.
Сам сервис построен на существенно изменённом коде фреймворка WebVectors. Вы можете исследовать историю семантических сдвигов любого заданного слова или получить списки слов, упорядоченных по силе семантических изменений между двумя данными годами. Также имеются визуализации «траекторий» слов через время, от одних значений к другим. Можно получить корпусные примеры употребления конкретного слова до и после семантического сдвига.
Работа по созданию ShiftRy велась в рамках магистерской программы по компьютерной лингвистике в Высшей школе экономики.
ShiftRy - это веб-сервис для анализа диахронических изменений в употреблении слов в российских новостях. Он назван в честь покемона Шифтри (англ. shift - «сдвиг»), внешне похожего на японских тэнгу. Используются дистрибутивные модели, обученные на большом корпусе русскоязычных новостных текстов, опубликованных в период с 2010 по 2020 год. Все эти эмбеддинги доступны для скачивания.
Сам сервис построен на существенно изменённом коде фреймворка WebVectors. Вы можете исследовать историю семантических сдвигов любого заданного слова или получить списки слов, упорядоченных по силе семантических изменений между двумя данными годами. Также имеются визуализации «траекторий» слов через время, от одних значений к другим. Можно получить корпусные примеры употребления конкретного слова до и после семантического сдвига.
Работа по созданию ShiftRy велась в рамках магистерской программы по компьютерной лингвистике в Высшей школе экономики.
ShiftRy
ShiftRy: Семантические сдвиги в русских новостях
Эволюция семантики слов в текстах русских новостей
Статья о ShiftRy будет представлена на конференции "Диалог" в июне (но почитать можно уже сейчас на сайте)
Forwarded from Системный Блокъ
Как работают семантические поисковые системы
На примере поисковика по стихам А. С. Пушкина
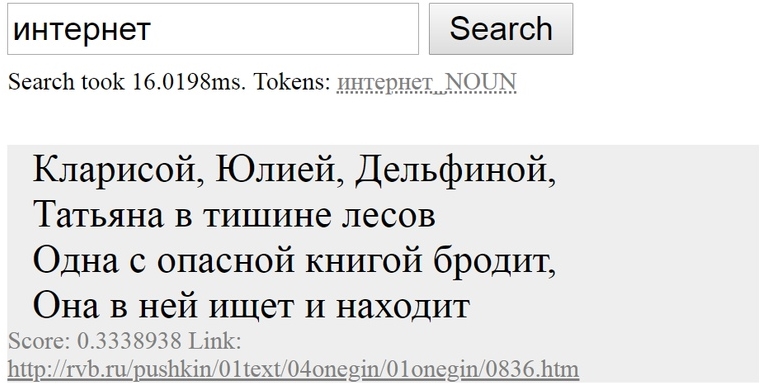
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
На примере поисковика по стихам А. С. Пушкина
Как найти «то, не знаю что», а если точнее — совершить нечеткий поиск? Вот бы можно было найти в интернете «похожую мысль», «что-нибудь по теме» или «такое же по смыслу». Жаль, что напрямую со смыслом слов Гугл пока что работать не умеет… Зато нечто похожее умеет маленький поисковик по стихам Пушкина.
Посмотрите на скрине ниже, что нашел этот поисковик по запросу «интернет». Как так получилось, что, хотя Пушкин не писал про интернет, поисковик нашел в его стихах строчки про книгу, в которой можно «искать и найти»? Ответ: благодаря семантическим векторам.
Семантический вектор слова
Лингвист Джон Руперт Фёрс однажды сказал: «Слово узнаешь по его окружению». Грубо говоря, на этой гипотезе строится основа дистрибутивной семантики — направления лингвистики, которое вычисляет, насколько близки два слова по смыслу, исходя из частоты их совместной встречаемости в текстовых корпусах.
Так можно найти синонимы и антонимы к слову или классифицировать его в тематический «отдел»; автоматически определить тематику документа, не давая прочесть его человеку; постараться смоделировать перифразы или выяснить правила сочетаемости слов.
Для таких операций каждому новому слову нужно присвоить набор чисел, характеризующий его смысл. Этот набор называется семантическим вектором слова. Его вычисляют на больших корпусах текстов.
В 2013 году Томаш Миколов разработал систему Word2vec, которая строит для слов векторы заданной размерности. Метод Миколова состоит в применении двух нейронных моделей: continuous bag-of-words (CBOW) и skip-gram. Первый предсказывает слово на основе данного контекста, а второй — наоборот, старается угадать контекст данного слова. В результате слова, встречающиеся в тексте в одинаковом окружении (а следовательно, имеющие схожий смысл), в векторном представлении будут иметь близкие координаты.
Семантический поисковик по стихам А. С. Пушкина
На сайте RusVectores выложены готовые наборы семантических векторов для огромного числа слов, полученные после обработки различных корпусов текстов алгоритмами word2vec с разными параметрами. Эти «векторные модели» можно скачать и использовать как готовую базу данных семантических векторов. Пользуясь этой возможностью, пользователь GitLab opennota написал семантический поисковик по стихам А. С. Пушкина.
Интерфейс программы — поле запроса, где пользователь может ввести слово или группу слов. Введенный запрос сохраняется в буфер обмена, где морфологический анализатор pymorphy2 распознает формы и леммы слов.
Для каждого слова запроса из предварительно рассчитанной модели word2vec извлекается семантический вектор. В случае, если поисковой запрос содержал несколько слов, их векторы суммируются и нормализуются.
Извлечение векторов отдельных слов, их суммирование и нормализация происходит также для каждого четверостишия из используемой базы данных: эта процедура реализуется при запуске программы. В результате для каждого четверостишия составляется единый семантический вектор.
После получения нормализованного вектора поискового запроса рассчитываются показатели косинусной близости вектора запроса и каждого из векторов четверостиший. Показатели сравниваются и программа выдает строфы, чей семантический вектор ближе всего к вектору слов из поискового запроса.
Поиск дает результаты и тогда, когда очевидно, что слова из поискового запроса не могут встречаться в произведениях Пушкина.
Данный пример демонстрирует, что при помощи инструментов word2vec и проекта RusVectores можно проводить семантический анализ и категоризацию текстов, выполняя поиск по нечетким критериям. Исследователь, работающий с подобной системой, сможет отыскать нестандартные контексты и значения лексических единиц на большом объеме данных.
Владимир Селеверстов
Больше подробностей в статье: https://sysblok.ru/philology/pushkin-terminator-i-zvezdolet/
{kind=link}
RusVectōrēs
Статья о ShiftRy будет представлена на конференции "Диалог" в июне (но почитать можно уже сейчас на сайте)
Индикатор.ру опубликовал большое интервью о ShiftRy и вообще о семантических сдвигах в русском языке, полюбопытствуйте
Indicator.Ru
«Как почти любой компьютерный лингвист, я существо двухголовое»
На 26-й международной конференции по компьютерной лингвистике и интеллектуальным технологиям «Диалог», которую компания ABBYY провела в партнерстве с Московским физико-техническим институтом, научный сотрудник Университета Осло Андрей Кутузов представил веб…