
Придумываю, как использовать нейросетки
Смотрели «Скрытые фигуры»? После нашей с вами голосовалки «человек vs нейросетка» я часто думаю про историю одной из героинь этого фильма, расчётчицы Мэри. Она раньше всех догадалась, что противиться компьютеру не получится — лучше найти с ним общий язык. В итоге она получила повышение, а для всех расчётчиц, которым было суждено потерять работу после автоматизации, она выбила новые престижные рабочие места. Круто?
В общем, я хочу так же. Хочу «свою» ручную нейросетку (подключённую куда-то ко мне по AP или как это делается?). Пусть сотрудницы скармливают ей аудиофайлы и получают готовую редактуру и звук. Потом пусть люди вручную правят результат и указывают нейросетке на ошибки. То есть мои сотрудницы из редакторок и звукорежиссёрок переквалифицируются в «операторок нейросеток». Они научатся говорить с нейросетями на одном языке, предвосхищать их ошибки, обучать и исправлять. А значимым капиталом моей компании станет нейросетка, обученная редактировать именно наши файлы.
Осталось только понять, как технически это сделать. Есть идеи?
Смотрели «Скрытые фигуры»? После нашей с вами голосовалки «человек vs нейросетка» я часто думаю про историю одной из героинь этого фильма, расчётчицы Мэри. Она раньше всех догадалась, что противиться компьютеру не получится — лучше найти с ним общий язык. В итоге она получила повышение, а для всех расчётчиц, которым было суждено потерять работу после автоматизации, она выбила новые престижные рабочие места. Круто?
В общем, я хочу так же. Хочу «свою» ручную нейросетку (подключённую куда-то ко мне по AP или как это делается?). Пусть сотрудницы скармливают ей аудиофайлы и получают готовую редактуру и звук. Потом пусть люди вручную правят результат и указывают нейросетке на ошибки. То есть мои сотрудницы из редакторок и звукорежиссёрок переквалифицируются в «операторок нейросеток». Они научатся говорить с нейросетями на одном языке, предвосхищать их ошибки, обучать и исправлять. А значимым капиталом моей компании станет нейросетка, обученная редактировать именно наши файлы.
Осталось только понять, как технически это сделать. Есть идеи?
{kind=link}
🔥34👍6😁4👎2
Как рассчитываться с подрядчикам и клиентами?
😩 😩 😩
Представьте математическую задачку. У вас параллельно проходит несколько проектов, и по каждому из них есть взаиморасчёты: вы — подрядчикам, клиент — вам. При этом расчёты проходят не синхронно: скажем, клиент уже заплатил, а вы подрядчикам — ещё нет. Или наоборот. Цены тоже всегда разные: за похожие задачи подрядчики могут от раза к разу требовать разное количество денег, ссылаясь на затраченные часы.
Сейчас я считаю взаимные обязательства в гугл-табличке, но это — сложный труд. Стоит немного отвлечься, можно наделать вот таких ошибок:
• заплатить за задачу подрядчику, но забыть включить этот кост в счёт для клиента;
• или цену для клиента установить без учёта дополнительных затрат на подрядчика;
• или забыть, что уже включала в счёт клиентов, а что ещё только предстоит.
Получается, нам нужна CRM, которая следит за взаиморасчётами попроектно и учитывает интересы всех участвующих сторон. Было бы круто, если бы она к тому же рассматривала услугу не как мешок картошки, а именно как услугу. Например, могла бы выводить показатель нормочаса. А если бы она к тому же умела пересчитывать в разных валютах — вообще космос!
Посоветуйте, кто встречал CRM, которые умеют что-то такое?
===
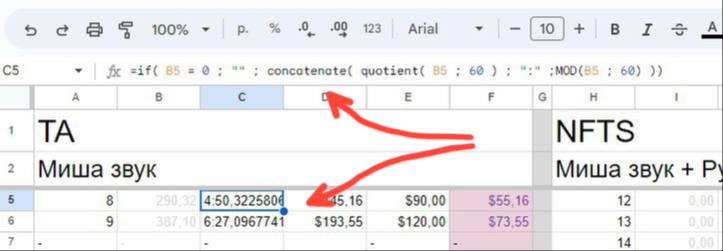
Ну или на худой конец формулу для гугл-таблицы, которая переведёт мои человекочасы из десятичных дробей в формат чч:мм, потому что даже чёртов GPT-чат не справляется с этой задачей
😤 😤 😤
😩 😩 😩
Представьте математическую задачку. У вас параллельно проходит несколько проектов, и по каждому из них есть взаиморасчёты: вы — подрядчикам, клиент — вам. При этом расчёты проходят не синхронно: скажем, клиент уже заплатил, а вы подрядчикам — ещё нет. Или наоборот. Цены тоже всегда разные: за похожие задачи подрядчики могут от раза к разу требовать разное количество денег, ссылаясь на затраченные часы.
Сейчас я считаю взаимные обязательства в гугл-табличке, но это — сложный труд. Стоит немного отвлечься, можно наделать вот таких ошибок:
• заплатить за задачу подрядчику, но забыть включить этот кост в счёт для клиента;
• или цену для клиента установить без учёта дополнительных затрат на подрядчика;
• или забыть, что уже включала в счёт клиентов, а что ещё только предстоит.
Получается, нам нужна CRM, которая следит за взаиморасчётами попроектно и учитывает интересы всех участвующих сторон. Было бы круто, если бы она к тому же рассматривала услугу не как мешок картошки, а именно как услугу. Например, могла бы выводить показатель нормочаса. А если бы она к тому же умела пересчитывать в разных валютах — вообще космос!
Посоветуйте, кто встречал CRM, которые умеют что-то такое?
===
Ну или на худой конец формулу для гугл-таблицы, которая переведёт мои человекочасы из десятичных дробей в формат чч:мм, потому что даже чёртов GPT-чат не справляется с этой задачей
😤 😤 😤
{kind=link}
😁2🤔2👎1
Чат GPT составил для меня план
Итак, я хочу отправлять в нейросеть исходники аудио — а на выходе получать качественный подкаст. Более того: я хочу, чтобы эта система была антихрупкой — чтобы с каждым новым сложным случаем она обучалась и справлялась всё лучше.
Мы обсудили эту задачу с чатом GPT: он посоветовал создать конвейер, в котором выход одной нейросети является входом следующей.
Вот пошаговая инструкция.
1. Найти нейронки, которые смогут решать мою задачу. По мнению GPT, это:
• AudioSet позволит собрать датасет — набор аудиофайлов с тегами, чтобы роботы могли понять, что я считаю "оговоркой", что — "шумом", а что звуком хорошего качества.
• Deep Noise Suppression или Wave-U-Net удалят шумы и дефекты звука, пользуясь моим датасетом с тегами.
• Transformer преобразует речевые сигналы в текст — так я получу расшифровки.
2. Обучить эти нейронные сети на моём наборе данных. Обученные модели можно сохранить на диск в виде файлов или объектов.
3. Разработать (или найти) API, чтобы объединить сети в единую цепочку. Можно использовать готовые фреймворки, вроде TensorFlow, Keras, PyTorch и MXNet.
4. Подключить нейронки в API, загрузить сохраненные модели, определить функцию для каждой нейронки. Так мы получим конвейер.
5. Донастроить. Останется только давать моему конвейеру фидбек, чтобы он мог дообучаться и справляться с каждой новой задачей лучше.
Уже интересно: я раньше не знала ни про готовые фреймворки для интеграции разных нейронок, ни про конвейеры. Но это ещё не рабочий план, ведь чат GPT — не предприниматель; он ничего не знает о ресурсах, расходах, MVP — так что мне придётся самой придумывать, с чего начать и как всё это провернуть без инвестиций. Ну или с вашей помощью 😏
Итак, я хочу отправлять в нейросеть исходники аудио — а на выходе получать качественный подкаст. Более того: я хочу, чтобы эта система была антихрупкой — чтобы с каждым новым сложным случаем она обучалась и справлялась всё лучше.
Мы обсудили эту задачу с чатом GPT: он посоветовал создать конвейер, в котором выход одной нейросети является входом следующей.
Вот пошаговая инструкция.
1. Найти нейронки, которые смогут решать мою задачу. По мнению GPT, это:
• AudioSet позволит собрать датасет — набор аудиофайлов с тегами, чтобы роботы могли понять, что я считаю "оговоркой", что — "шумом", а что звуком хорошего качества.
• Deep Noise Suppression или Wave-U-Net удалят шумы и дефекты звука, пользуясь моим датасетом с тегами.
• Transformer преобразует речевые сигналы в текст — так я получу расшифровки.
2. Обучить эти нейронные сети на моём наборе данных. Обученные модели можно сохранить на диск в виде файлов или объектов.
3. Разработать (или найти) API, чтобы объединить сети в единую цепочку. Можно использовать готовые фреймворки, вроде TensorFlow, Keras, PyTorch и MXNet.
4. Подключить нейронки в API, загрузить сохраненные модели, определить функцию для каждой нейронки. Так мы получим конвейер.
5. Донастроить. Останется только давать моему конвейеру фидбек, чтобы он мог дообучаться и справляться с каждой новой задачей лучше.
Уже интересно: я раньше не знала ни про готовые фреймворки для интеграции разных нейронок, ни про конвейеры. Но это ещё не рабочий план, ведь чат GPT — не предприниматель; он ничего не знает о ресурсах, расходах, MVP — так что мне придётся самой придумывать, с чего начать и как всё это провернуть без инвестиций. Ну или с вашей помощью 😏
{kind=link}
👍25🤔16🔥12😁2😱2
(продолжение)
...Я не стану прям щас нанимать команду разработчиков и создавать целый конвейер с нуля. Попробую подойти к этой задаче "методом прогрессивного джипега": собирать эту махину постепенно, причём так, чтобы на каждом этапе создавания она была уже сразу рабочей.
С чего начать?
Сейчас мне нужно найти нейросеть (или несколько?), которая:
1. Не требует разметки материалов тегами. Чтобы система хорошо работала, нужно скормить ей сотни тысяч примеров — а мы точно не станем вручную проставлять сотни тысяч тегов. Хорошо бы нейросетка умела сама сопоставлять файлы "до и после". Типа мы ей скармливаем исходники —> она нам выдаёт фигню —> мы исправляем и скармливаем обратно —> она сама сопоставляет до-после и делает выводы. В следующий раз справляется лучше.
Похоже, для этого подойдёт RNN с циклом обратной связи, и в особенности LSTM, поскольку она умеет сама извлекать уроки из материалов.
2. Работает как звуковик — чистить звук от ревербераций, цоканий, слюней. С таким уже хорошо справляется Adobe Podcast, но с ним каждый раз как в первый раз — он (по крайней мере в бесплатной браузерной версии) не умеет учиться. Нам нужно так же, но с умением обучаться, сопоставляя до-после.
3. Работает как монтажер — аккуратно вырезает ummm, you know, like и лишние паузы. Кажись, это принципиально другая задача, она требует не отделения полезного сигнала от шума, а распознавания речи. Не представляю, какая сетка может делать такое, но если мы научимся, это здорово продвинет нас вперёд.
4. Работает как редактор — понимает, где интро, где представление гостя, тело подкаста и аутро. Склеивает их вместе в нужном порядке. Здесь требуется распознавание не только речи, но и смысла. Эта часть занимает у человека меньше всего времени, так что её автоматизировать будем в последнюю очередь. Но в итоге будем.
5. Обученную нейросеть мы сможем сохранить в виде файлов или объектов — то есть сможем распоряжаться результатом своей работы.
6. Нейросети смогут интегрироваться в наш API или любой из готовых фреймворков. Делать мы этого пока не будем, но нужно, чтобы такая возможность была.
Когда я найду нейросети, отвечающие этому ТЗ, я попробую интегрировать их в уже существующую работу: попрошу редакторок и звукорежиссёров зедействовать нейронки в своей работе и тем самым уже начать процесс их обучения.
Итак: в чём я ошибаюсь?
...Я не стану прям щас нанимать команду разработчиков и создавать целый конвейер с нуля. Попробую подойти к этой задаче "методом прогрессивного джипега": собирать эту махину постепенно, причём так, чтобы на каждом этапе создавания она была уже сразу рабочей.
С чего начать?
Сейчас мне нужно найти нейросеть (или несколько?), которая:
1. Не требует разметки материалов тегами. Чтобы система хорошо работала, нужно скормить ей сотни тысяч примеров — а мы точно не станем вручную проставлять сотни тысяч тегов. Хорошо бы нейросетка умела сама сопоставлять файлы "до и после". Типа мы ей скармливаем исходники —> она нам выдаёт фигню —> мы исправляем и скармливаем обратно —> она сама сопоставляет до-после и делает выводы. В следующий раз справляется лучше.
Похоже, для этого подойдёт RNN с циклом обратной связи, и в особенности LSTM, поскольку она умеет сама извлекать уроки из материалов.
2. Работает как звуковик — чистить звук от ревербераций, цоканий, слюней. С таким уже хорошо справляется Adobe Podcast, но с ним каждый раз как в первый раз — он (по крайней мере в бесплатной браузерной версии) не умеет учиться. Нам нужно так же, но с умением обучаться, сопоставляя до-после.
3. Работает как монтажер — аккуратно вырезает ummm, you know, like и лишние паузы. Кажись, это принципиально другая задача, она требует не отделения полезного сигнала от шума, а распознавания речи. Не представляю, какая сетка может делать такое, но если мы научимся, это здорово продвинет нас вперёд.
4. Работает как редактор — понимает, где интро, где представление гостя, тело подкаста и аутро. Склеивает их вместе в нужном порядке. Здесь требуется распознавание не только речи, но и смысла. Эта часть занимает у человека меньше всего времени, так что её автоматизировать будем в последнюю очередь. Но в итоге будем.
5. Обученную нейросеть мы сможем сохранить в виде файлов или объектов — то есть сможем распоряжаться результатом своей работы.
6. Нейросети смогут интегрироваться в наш API или любой из готовых фреймворков. Делать мы этого пока не будем, но нужно, чтобы такая возможность была.
Когда я найду нейросети, отвечающие этому ТЗ, я попробую интегрировать их в уже существующую работу: попрошу редакторок и звукорежиссёров зедействовать нейронки в своей работе и тем самым уже начать процесс их обучения.
Итак: в чём я ошибаюсь?
{kind=link}
🔥9😁3
Просто чтобы вы знали, чем закончилось моё рубилово с нейросетками и иллюстрациями:
Я получила десятки картинок со страдальческими, жуткими и криповыми сценами личной жизни инопланетных чудищ — и решила, что с меня хватит.
А вот о чем в комментах напомнил Gleb: "Автоматизировать в первую очередь имеет смысл часто повторяющиеся операции" — то есть подкастерской студии не стоит упарываться, чтоб получать хорошие обложки в нейросетках. Чтож, ладно.
В итоге мы сделали заказ у иллюстраторки из плоти и крови — и остались очень довольны результатом. Посмотрите: она не выполнила задание дословно, но при этом попала прям в цель.
Я получила десятки картинок со страдальческими, жуткими и криповыми сценами личной жизни инопланетных чудищ — и решила, что с меня хватит.
А вот о чем в комментах напомнил Gleb: "Автоматизировать в первую очередь имеет смысл часто повторяющиеся операции" — то есть подкастерской студии не стоит упарываться, чтоб получать хорошие обложки в нейросетках. Чтож, ладно.
В итоге мы сделали заказ у иллюстраторки из плоти и крови — и остались очень довольны результатом. Посмотрите: она не выполнила задание дословно, но при этом попала прям в цель.
{kind=link}
🔥39👍9👎5
Загадка: почему Форд делал машины «любого цвета, если они чёрные».
Отгадку сообщит Максим, а заодно объяснит, почему бизнес-модели раньше строились вокруг продукта, а теперь — нет. Слушайте
⬇️ ⬇️ ⬇️
= = =
P.S. Это мы готовим ещё один выпуск «Заварили бизнес», но в него влезают не всё. Так что невошедшее я буду скидывать сюда. Прям как есть: без монтажа и звука.
Мой собеседник — Максим Михалев, ex-CPO Modeus и ведущий программы «Chief Product Officer: управление продуктовой стратегией».
Отгадку сообщит Максим, а заодно объяснит, почему бизнес-модели раньше строились вокруг продукта, а теперь — нет. Слушайте
⬇️ ⬇️ ⬇️
= = =
P.S. Это мы готовим ещё один выпуск «Заварили бизнес», но в него влезают не всё. Так что невошедшее я буду скидывать сюда. Прям как есть: без монтажа и звука.
Мой собеседник — Максим Михалев, ex-CPO Modeus и ведущий программы «Chief Product Officer: управление продуктовой стратегией».
👍13🥰3👎2🔥1
Audio
Одну из частей своего бизнеса мы называем «Макдоналдсом»: стандартизация, низкая маржа, заработок на объеме. А тут Максим объяснил, за счёт чего работает бизнес-модель самого Макдоналдса
👍10🔥4🤔1
Ликбез по нейросеткам
(затачиваю своё ТЗ, разбираюсь, как всё работает)
Созвонилась с Андреем, который много лет назад уехал в Японию, чтобы заниматься машинным обучением. Он объяснил, какие существуют варианты для решения моей бизнес-задачи, а заодно просто провёл ликбез по нейросеткам.
🐓🐣🐓🐣
Для начала рассказал про две стадии развития нейросетки:
1. Архитектура — это как студентка с высоким IQ, которая не прочитала ни одного учебника и никогда не решала задач. У неё высокий потенциал, но его только предстоит раскрыть.
Открытых архитектур много в свободном доступе, но они имеют скорее научную, чем бизнесовую ценность. Обычно разработчицы (-ки) архитектур прилагают к ним примерную оценку — сколько данных нужно через неё прогнать, чтобы она перешла на следующий уровень...
2. Обученная модель — та же студентка решила 10 млн или 10 млрд примеров, то есть поглотила огромный объем данных. В процессе у неё появились новые знания-умения — это называется параметры. Так мы получили "обученную модель" или "архитектуру с параметрами".
🎤🤖🎤🤖
А теперь — инструкция о том, как мне решать свою задачу:
1. Взять открытую архитектуру и самостоятельно её обучить. Найти в свободном доступе архитектуру без параметров — просто; шансы обучить её ниже среднего.
Нейросетке можно скармливать и неразмеченные данные (как я хотела), но для этого объем данных должен быть действительно огромным — десятки миллионов или миллиардов токенов.
Есть небольшая вероятность, что обучить нейросетку для работы с аудио получится и с небольшим объемом данных: если токен — это фонема, то каждый эпизод подкаста содержит тысячи токенов. Значит, для обучения нейросетки моему машин-лёрнинг-инженеру может быть достаточно найти в открытом доступе 100 тыс. аудиозаписей и засунуть их в пайплайн обучения. Это всё ещё дофига, но оборимо.
2. Найти открытую обученную модель — то есть уже с параметрами. Вероятность найти такую — ниже среднего, но если всё же найду, то вероятность успеха высокая. (Адрей прям так и общается, указывая вероятности)
Я смогу давать такой модели свои данные — и она будет обрабатывать их, используя готовые параметры.
===
Это всё ещё не план действий, ведь я пока не знаю: как искать архитектуры и модели? Как отличить подходящую? Как найти подходящую машин-лёрнинг-инженера? И наверняка есть ещё 100500 вопросов, до которых я пока не добралась.
Я запланировала ещё пару консультаций со спецами, а чтобы за них заплатить — продала пару реклам на май в этом канале. Надеюсь, эти рекламы вас не слишком побеспокоят 🙄
(затачиваю своё ТЗ, разбираюсь, как всё работает)
Созвонилась с Андреем, который много лет назад уехал в Японию, чтобы заниматься машинным обучением. Он объяснил, какие существуют варианты для решения моей бизнес-задачи, а заодно просто провёл ликбез по нейросеткам.
🐓🐣🐓🐣
Для начала рассказал про две стадии развития нейросетки:
1. Архитектура — это как студентка с высоким IQ, которая не прочитала ни одного учебника и никогда не решала задач. У неё высокий потенциал, но его только предстоит раскрыть.
Открытых архитектур много в свободном доступе, но они имеют скорее научную, чем бизнесовую ценность. Обычно разработчицы (-ки) архитектур прилагают к ним примерную оценку — сколько данных нужно через неё прогнать, чтобы она перешла на следующий уровень...
2. Обученная модель — та же студентка решила 10 млн или 10 млрд примеров, то есть поглотила огромный объем данных. В процессе у неё появились новые знания-умения — это называется параметры. Так мы получили "обученную модель" или "архитектуру с параметрами".
🎤🤖🎤🤖
А теперь — инструкция о том, как мне решать свою задачу:
1. Взять открытую архитектуру и самостоятельно её обучить. Найти в свободном доступе архитектуру без параметров — просто; шансы обучить её ниже среднего.
Нейросетке можно скармливать и неразмеченные данные (как я хотела), но для этого объем данных должен быть действительно огромным — десятки миллионов или миллиардов токенов.
Есть небольшая вероятность, что обучить нейросетку для работы с аудио получится и с небольшим объемом данных: если токен — это фонема, то каждый эпизод подкаста содержит тысячи токенов. Значит, для обучения нейросетки моему машин-лёрнинг-инженеру может быть достаточно найти в открытом доступе 100 тыс. аудиозаписей и засунуть их в пайплайн обучения. Это всё ещё дофига, но оборимо.
2. Найти открытую обученную модель — то есть уже с параметрами. Вероятность найти такую — ниже среднего, но если всё же найду, то вероятность успеха высокая. (Адрей прям так и общается, указывая вероятности)
Я смогу давать такой модели свои данные — и она будет обрабатывать их, используя готовые параметры.
===
Это всё ещё не план действий, ведь я пока не знаю: как искать архитектуры и модели? Как отличить подходящую? Как найти подходящую машин-лёрнинг-инженера? И наверняка есть ещё 100500 вопросов, до которых я пока не добралась.
Я запланировала ещё пару консультаций со спецами, а чтобы за них заплатить — продала пару реклам на май в этом канале. Надеюсь, эти рекламы вас не слишком побеспокоят 🙄
{kind=link}
🔥20👍8👎2😁2🥰1
«Заварили бизнес»
снова в формате реалити 😏
Наконец-то выпал шанс рассказать в подкасте про наш переезд в Португалию. В первом эпизоде Лена собирает чемодан за 15 минут, а я распродаю баночки из под специей, собираю справки и рыдаю в туалете в поликлинике.
Самоестыдное смешное в эпизоде — как я симулирую знание английского. А самое полезное — как Максим помогает мне пересобрать бизнес-модель для презентации инкубаторам и португальским ведомствам.
Обрывки разговора с ним вы уже слушали в этом канале. Вот его регалии:
Максим Михалев, ex-CPO Modeus и ведущий программы «Chief Product Officer: управление продуктовой стратегией».
Слушайте первый эпизод сезона: https://podcast.ru/e/.Hp3hVe9n~1
снова в формате реалити 😏
Наконец-то выпал шанс рассказать в подкасте про наш переезд в Португалию. В первом эпизоде Лена собирает чемодан за 15 минут, а я распродаю баночки из под специей, собираю справки и рыдаю в туалете в поликлинике.
Самое
Обрывки разговора с ним вы уже слушали в этом канале. Вот его регалии:
Максим Михалев, ex-CPO Modeus и ведущий программы «Chief Product Officer: управление продуктовой стратегией».
Слушайте первый эпизод сезона: https://podcast.ru/e/.Hp3hVe9n~1
Podcast.ru
«Моя жизнь похожа на реалити-шоу: чем страшней, тем интересней»: перевозим бизнес в Португалию – Заварили бизнес – Podcast.ru
Саша в сомнениях: уезжать ей или нет, а Лена собирается за 15 минут и улетает в Грузию. Саша бегает по московским инстанциям, добывая справки, а Лена собирает заявку на стартап-визу в Португалию. Саша пересобирает бизнес-модель студии, а Лена хочет шампанского…
🔥31👍7🥰4👎3
Ищу NSM — метрику полярной звезды
На этой неделе мы запускаем свой первый подкаст на английском языке. И, конечно, я хочу воспользоваться этим моментом, чтобы получить полезные цифры про подкасты в англоязычном мире.
Но какие из цифр — полезные?
Чтобы в этом разобраться, я переслушала выпуск “Бизнес, роботов, мечтов” про North Star Metric — и спешу вам напомнить, о чём там шла речь.
В каждом бизнесе множество цифр, которые можно отслеживать: количество платящих пользовательниц, средний чек, нормочас, маржинальность — короче, этих цифр тысячи. Но, если отслеживать их все, это будет просто перечень чисел: по ним нельзя будет судить о качестве бизнеса и тем более — принимать на их основе решения.
Можно сфокусироваться на самой важной метрике — прибыли. Ради неё же всё и затеваем, да? Но если думать только о прибыли, то бизнес рискует слишком сильно надавить на клиенток: брать с них больше денег, чем приносит ценности. Такие отношения не могут долго работать: при первой возможности клиентки сбегут искать лучшего соотношения цены и ценности. Так за быстрым ростом прибыли мы получим такой же быстрый провал.
Поэтому и придумали north star metric. Эта етрика может косвенно показать состояние всего бизнеса: продукта, маркетинга, продаж, дистрибуции, ценообразования... Но сформулировать свою north star metric — хитрое дело.
NSM должна коррелировать с:
• прибылью компании. Например, у Нетфликс NSM — это “Кол-во подписчиков, которые …”. Ключевое слово — подписчиков, то есть платящих клиентов. Хотя NSM создана, чтобы отражать количество наносимой пользы, она не теряет связи и с прибылью.
• с ценностью, которую мы нанесли клиентам. NSM Нетфликс продолжается так: “…которые смотрят больше 60 часов в месяц”. Даже если Нетфликс получит 100500 тыщ новых клиенток, которые будут смотреть по одному фильму в неделю — NSM не вырастет, и вся компания встанет на уши. Потому что новые клиентки не получили ценности — возможность посмотреть 60 часов фильмятины за 30 баксов. А значит, эти клиентки скоро уйдут к конкурентам.
• с aha-moment. Так называется момент, когда клиентка ощутила ту самую ценность продукта. В случае с Нетфликс этот момент — когда посмотрено 60 часов кино за месяц, но есть и более показательные примеры. Например, у американской компании Instacart NSM — это “Количество товаров, доставленных вовремя”. Только когда клиентка получает заказ вовремя, она такая: “аха! Вот это крутой сервис!” Опоздавшие доставки не идут в зачёт.
Ещё у NSM не должно быть лимита, чтобы компания могла бесконечно долго следить за её ростом. То есть “количество часов, проведённых клиенткой за просмотром сериалов” — не подходит, поскольку у такой метрики существует естественное ограничение.
И, разумеется, NSM должна быть выражена в цифрах. Это же метрика.
😏 😏 😏
Если вы формулировали NSM для своего бизнеса, расскажите, какую метрику вы выбрали. А если вы просто хотите размять мозги, то предложите, какая NSM может быть у студии подкастов. Я над этим билась, получается, 1.5 года — с тех пор, как мы записали тот выпуск “Бизнес, роботов, мечтов”.
На этой неделе мы запускаем свой первый подкаст на английском языке. И, конечно, я хочу воспользоваться этим моментом, чтобы получить полезные цифры про подкасты в англоязычном мире.
Но какие из цифр — полезные?
Чтобы в этом разобраться, я переслушала выпуск “Бизнес, роботов, мечтов” про North Star Metric — и спешу вам напомнить, о чём там шла речь.
В каждом бизнесе множество цифр, которые можно отслеживать: количество платящих пользовательниц, средний чек, нормочас, маржинальность — короче, этих цифр тысячи. Но, если отслеживать их все, это будет просто перечень чисел: по ним нельзя будет судить о качестве бизнеса и тем более — принимать на их основе решения.
Можно сфокусироваться на самой важной метрике — прибыли. Ради неё же всё и затеваем, да? Но если думать только о прибыли, то бизнес рискует слишком сильно надавить на клиенток: брать с них больше денег, чем приносит ценности. Такие отношения не могут долго работать: при первой возможности клиентки сбегут искать лучшего соотношения цены и ценности. Так за быстрым ростом прибыли мы получим такой же быстрый провал.
Поэтому и придумали north star metric. Эта етрика может косвенно показать состояние всего бизнеса: продукта, маркетинга, продаж, дистрибуции, ценообразования... Но сформулировать свою north star metric — хитрое дело.
NSM должна коррелировать с:
• прибылью компании. Например, у Нетфликс NSM — это “Кол-во подписчиков, которые …”. Ключевое слово — подписчиков, то есть платящих клиентов. Хотя NSM создана, чтобы отражать количество наносимой пользы, она не теряет связи и с прибылью.
• с ценностью, которую мы нанесли клиентам. NSM Нетфликс продолжается так: “…которые смотрят больше 60 часов в месяц”. Даже если Нетфликс получит 100500 тыщ новых клиенток, которые будут смотреть по одному фильму в неделю — NSM не вырастет, и вся компания встанет на уши. Потому что новые клиентки не получили ценности — возможность посмотреть 60 часов фильмятины за 30 баксов. А значит, эти клиентки скоро уйдут к конкурентам.
• с aha-moment. Так называется момент, когда клиентка ощутила ту самую ценность продукта. В случае с Нетфликс этот момент — когда посмотрено 60 часов кино за месяц, но есть и более показательные примеры. Например, у американской компании Instacart NSM — это “Количество товаров, доставленных вовремя”. Только когда клиентка получает заказ вовремя, она такая: “аха! Вот это крутой сервис!” Опоздавшие доставки не идут в зачёт.
Ещё у NSM не должно быть лимита, чтобы компания могла бесконечно долго следить за её ростом. То есть “количество часов, проведённых клиенткой за просмотром сериалов” — не подходит, поскольку у такой метрики существует естественное ограничение.
И, разумеется, NSM должна быть выражена в цифрах. Это же метрика.
😏 😏 😏
Если вы формулировали NSM для своего бизнеса, расскажите, какую метрику вы выбрали. А если вы просто хотите размять мозги, то предложите, какая NSM может быть у студии подкастов. Я над этим билась, получается, 1.5 года — с тех пор, как мы записали тот выпуск “Бизнес, роботов, мечтов”.
Apple Podcasts
«Бизнес, роботы, мечты»: ««Хочу супер-пупер мега продукт, начинайте штормить». Разбираемся, как гроуз-хакинг помогает бизнесу…
Шоу «Бизнес, роботы, мечты», выпуск ««Хочу супер-пупер мега продукт, начинайте штормить». Разбираемся, как гроуз-хакинг помогает бизнесу расти» от 25 нояб. 2021 г.
🔥17👎5
Наша NSM — количество людей, которые послушали эпизод с рекламой, а затем запустили подкаст снова
Но всё сложно..
Irina Choo ухватила моё главное затруднение: в отличие от Нетфликса, мы работаем в В2В-сегменте — наносим пользу слушательницам, а деньги получаем с компаний. Выходит, наша NSM должна отражать удовлетворённость и тех, и других — иначе мы рискуем или работать бесплатно, или сделать подкаст, который не интересует слушательниц. Как совместить интересы двух групп в одной метрике?
Мы поняли, что aha-момент наступает, когда слушательницу цепляют наши нарративные истории или ёмкая подача информации. Но мы сможем утверждать, что всё это её зацепило, только если она сознательно решит: “включу этот подкаст ещё раз!”. То есть наша NSM — “количество людей, которые запустили подкаст более одного раза”.
Чтобы наша NSM коррелировала не только с пользой, но и с прибылью компании, добавим, что мы будем считать только слушательниц эпизодов с рекламой. Так NSM не станет расти, если мы не умеем продавать рекламу или если наши интеграции отпугивают слушательниц. То есть наша NSM дополняется — “количество людей, которые послушали эпизод с рекламой, а затем запустили подкаст снова”.
А теперь вернёмся в реальность.
Хостинг и платформы дают очень скудную статистику: количество уников и прослушиваний на эпизод и на подкаст, дослушивания, разбивка по устройствам и странам, может, что-то ещё. Но в этой аналитике никогда не отслеживается история действий по юнитам: мы не можем выделить сегмент “людей, которые сделали то-то, а потом сделали то-то”. Например, мы можем посчитать уникальных слушательниц первого эпизода, но ни за что не узнаем, вернулись ли они послушать другие эпизоды. Увы, это делает большую часть цифр на нашем дашборде неприменимыми.
Единственное, на что нам остаётся смотреть — количество прослушиваний first 7 days since release. Эта метрика по идее должна косвенно указывать на рост ядра аудитории, потому что в первые 7 дней подкаст обычно слушают подписчицы или те, кто получают напоминалки в соцсетях. Правда, на эту метрику может повлиять любое промо, выходные дни или твит Маска, так что смотреть на неё будем, но только через монокль и со скептическим выражением лица.
Если у этой истории должна быть мораль, то она вот: интересно размять мозги и нащупать, какая цифра отразила бы в себе все главные жизненные показатели бизнеса. Но часто приходится заходить с другого конца: смотреть в то, что накладено в дашборды, и пытаться наковырять в этом какой-то смысл
🤷🏻♀️ 🤷🏻♀️ 🤷🏻♀️
Но всё сложно..
Irina Choo ухватила моё главное затруднение: в отличие от Нетфликса, мы работаем в В2В-сегменте — наносим пользу слушательницам, а деньги получаем с компаний. Выходит, наша NSM должна отражать удовлетворённость и тех, и других — иначе мы рискуем или работать бесплатно, или сделать подкаст, который не интересует слушательниц. Как совместить интересы двух групп в одной метрике?
Мы поняли, что aha-момент наступает, когда слушательницу цепляют наши нарративные истории или ёмкая подача информации. Но мы сможем утверждать, что всё это её зацепило, только если она сознательно решит: “включу этот подкаст ещё раз!”. То есть наша NSM — “количество людей, которые запустили подкаст более одного раза”.
Чтобы наша NSM коррелировала не только с пользой, но и с прибылью компании, добавим, что мы будем считать только слушательниц эпизодов с рекламой. Так NSM не станет расти, если мы не умеем продавать рекламу или если наши интеграции отпугивают слушательниц. То есть наша NSM дополняется — “количество людей, которые послушали эпизод с рекламой, а затем запустили подкаст снова”.
А теперь вернёмся в реальность.
Хостинг и платформы дают очень скудную статистику: количество уников и прослушиваний на эпизод и на подкаст, дослушивания, разбивка по устройствам и странам, может, что-то ещё. Но в этой аналитике никогда не отслеживается история действий по юнитам: мы не можем выделить сегмент “людей, которые сделали то-то, а потом сделали то-то”. Например, мы можем посчитать уникальных слушательниц первого эпизода, но ни за что не узнаем, вернулись ли они послушать другие эпизоды. Увы, это делает большую часть цифр на нашем дашборде неприменимыми.
Единственное, на что нам остаётся смотреть — количество прослушиваний first 7 days since release. Эта метрика по идее должна косвенно указывать на рост ядра аудитории, потому что в первые 7 дней подкаст обычно слушают подписчицы или те, кто получают напоминалки в соцсетях. Правда, на эту метрику может повлиять любое промо, выходные дни или твит Маска, так что смотреть на неё будем, но только через монокль и со скептическим выражением лица.
Если у этой истории должна быть мораль, то она вот: интересно размять мозги и нащупать, какая цифра отразила бы в себе все главные жизненные показатели бизнеса. Но часто приходится заходить с другого конца: смотреть в то, что накладено в дашборды, и пытаться наковырять в этом какой-то смысл
🤷🏻♀️ 🤷🏻♀️ 🤷🏻♀️
{kind=link}
👎7😢5👍3😁2
Как ненавязчиво пригласить себя в бар, если другие не догадались
Вышел наш первый англоязычный эпизод — Fucking English.
Это подкаст о том, как находить общий язык и флиртовать, особенно если английский для вас не родной. Подкаст можно слушать, даже если у вас pre-Intermediate — в общих чертах всё будет понятно 😏
😈 😈 😈
В этот раз наш учитель из Миннесоты, мистер Бретт, подскажет несколько фраз, которые спасут от одиночества в пятницу вечером. А ведущие расскажут, как использовали эти уроки на практике — тут-то и начнётся самое интересное.
В первом эпизоде Лена удирает со своим парнем от полиции, а Алёна встречает в Оккупид девчонку в смешной шапке, попадает в эпицентр финской драмы и пытается выяснить, когда же наступает американское some time.
И хотя в этом уроке у всех случился миссандестендинг, по крайней мере всем персонажам удалось избежать клешней плотоядных растений. И это — просто везение! Вы же знаете: путешествия через языковые барьеры и культурные различия — это захватывающе, но немного опасно.
😍 😍 😍
Слушайте подкаст, жмите сердечко или звёздочку, подписывайтесь и оставляйте комменты — всё это убедит площадки нас заметить и показывать наш подкаст другим.
Подкаст есть на всех платформах, в том числе:
- на эпл подкасты,
- гугл подкасты,
- спотифай.
...в остальных платформах вы можете набрать в поисковике — Fucking English.
Вышел наш первый англоязычный эпизод — Fucking English.
Это подкаст о том, как находить общий язык и флиртовать, особенно если английский для вас не родной. Подкаст можно слушать, даже если у вас pre-Intermediate — в общих чертах всё будет понятно 😏
😈 😈 😈
В этот раз наш учитель из Миннесоты, мистер Бретт, подскажет несколько фраз, которые спасут от одиночества в пятницу вечером. А ведущие расскажут, как использовали эти уроки на практике — тут-то и начнётся самое интересное.
В первом эпизоде Лена удирает со своим парнем от полиции, а Алёна встречает в Оккупид девчонку в смешной шапке, попадает в эпицентр финской драмы и пытается выяснить, когда же наступает американское some time.
И хотя в этом уроке у всех случился миссандестендинг, по крайней мере всем персонажам удалось избежать клешней плотоядных растений. И это — просто везение! Вы же знаете: путешествия через языковые барьеры и культурные различия — это захватывающе, но немного опасно.
😍 😍 😍
Слушайте подкаст, жмите сердечко или звёздочку, подписывайтесь и оставляйте комменты — всё это убедит площадки нас заметить и показывать наш подкаст другим.
Подкаст есть на всех платформах, в том числе:
- на эпл подкасты,
- гугл подкасты,
- спотифай.
...в остальных платформах вы можете набрать в поисковике — Fucking English.
{kind=link}
🔥33👎8👍7😁3
Теперь я знаю, где номадствуют все наши
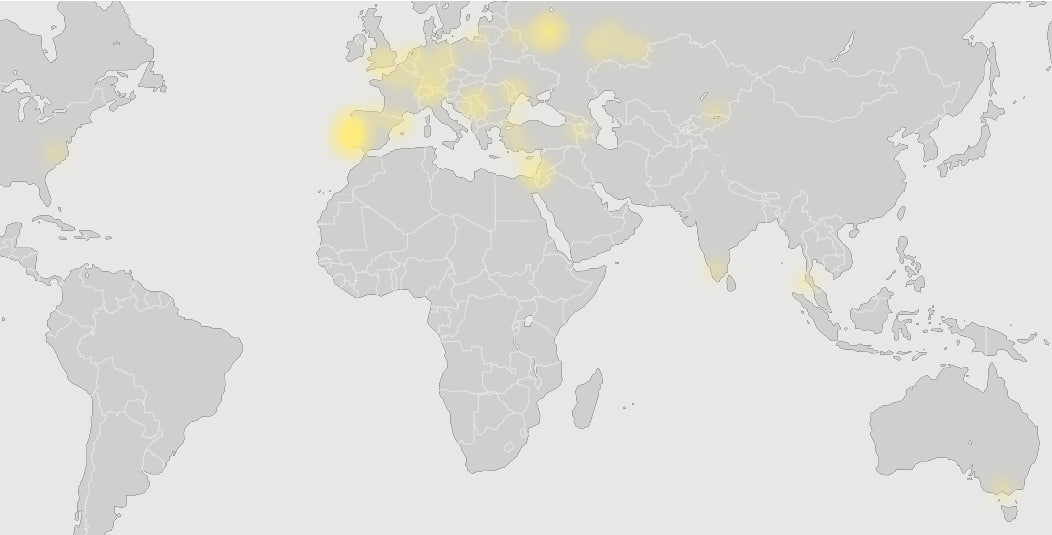
Большая часть аудитории Fucking English — россияне, но живут они в разных частях света.
33% — в разных частях России, 23% — в Португалии, а остальные по 2-5% — в США, Великобритании, Израиле, Германии, Нидерландах, Австрии, Грузии, Польше...
Большая часть аудитории Fucking English — россияне, но живут они в разных частях света.
33% — в разных частях России, 23% — в Португалии, а остальные по 2-5% — в США, Великобритании, Израиле, Германии, Нидерландах, Австрии, Грузии, Польше...
{kind=link}
🔥19👍5👎1
Вчера мы открыли Лене португальское ИП
Вот так просто за 40 минут она стала владелицей компании в Португалии — здесь этот процесс очень простой, онлайновый.
Но ещё круче то, что заставило нас так спешно открывать компанию: нам понадобились реквизиты, чтобы заключить свой первый международный контракт.
Волнительно?
Охх, я буду отмечать это все выходные!
Вот так просто за 40 минут она стала владелицей компании в Португалии — здесь этот процесс очень простой, онлайновый.
Но ещё круче то, что заставило нас так спешно открывать компанию: нам понадобились реквизиты, чтобы заключить свой первый международный контракт.
Волнительно?
Охх, я буду отмечать это все выходные!
👍67🔥42👎5🤬4🥰3😁3
Вошли в топ 25% 😏
Подкасты — это Крайнестан, озеро чёрных лебедей. Здесь большую часть прибыли зарабатывает 1% криэйтеров, и исследование Buzzsprout это косвенно подтверждает. Смотрите:
• топ 1% подкастов собирает в среднем 4 994 прослушивания за первые 7 дней после релиза;
• топ 5% — 1081 прослушивания;
• топ 10% — 440 прослушиваний;
• топ 25% — 110 прослушиваний (мы с Fucking English пока находимся здесь);
- топ 50% (то есть в среднем подкаст) — получает 32 прослушивания за первые 7 дней.
Мы целимся в золотой 1% и если вам нравится Fucking English, то не забудьте послушать новый эпизод, он уже вышел:
• на эпле, гугле и кастбоксе
• на спотифае
• на Яндекс.Музыке
Подкасты — это Крайнестан, озеро чёрных лебедей. Здесь большую часть прибыли зарабатывает 1% криэйтеров, и исследование Buzzsprout это косвенно подтверждает. Смотрите:
• топ 1% подкастов собирает в среднем 4 994 прослушивания за первые 7 дней после релиза;
• топ 5% — 1081 прослушивания;
• топ 10% — 440 прослушиваний;
• топ 25% — 110 прослушиваний (мы с Fucking English пока находимся здесь);
- топ 50% (то есть в среднем подкаст) — получает 32 прослушивания за первые 7 дней.
Мы целимся в золотой 1% и если вам нравится Fucking English, то не забудьте послушать новый эпизод, он уже вышел:
• на эпле, гугле и кастбоксе
• на спотифае
• на Яндекс.Музыке
{kind=link}
👍15👎4🥰4😁1
Помню, я вам обещала праздновать все выходные, как животное, но на самом деле поехала в Фигейру работать. Мы с Леной придумали новый формат подкаста про бизнес — и решили поскорей записать пилот. Это будет наше MVP, с которым мы пойдём продавать проект акселераторам.
Почему я работаю на выходных?! Дело в том, что мы тестим 3 бизнес-модели + ведём российскую часть бизнеса — и ничего из этого пока не удаётся отстрелить. Поэтому я постоянно работаю и всё равно чувствую, что недостаточно. За полгода можно было продвинуться и дальше 😏
В итоге вот она я: лежу на бортике бассейна в воскресенье и пытаюсь рассчитать, сколько процентов времени могу отдать каждому проекту. Иначе моя голова просто взорвётся, как зёрнышко кукурузы в микроволновке
Почему я работаю на выходных?! Дело в том, что мы тестим 3 бизнес-модели + ведём российскую часть бизнеса — и ничего из этого пока не удаётся отстрелить. Поэтому я постоянно работаю и всё равно чувствую, что недостаточно. За полгода можно было продвинуться и дальше 😏
В итоге вот она я: лежу на бортике бассейна в воскресенье и пытаюсь рассчитать, сколько процентов времени могу отдать каждому проекту. Иначе моя голова просто взорвётся, как зёрнышко кукурузы в микроволновке
{kind=link}
👍16🔥4🤯4👎3😁3
Делаю непристойный лендинг из всего, что завалялось 😏
«У вас есть сайт компании?» — это второй вопрос, который нам задают сразу после «Чем вы занимаетесь?». Поэтому сегодня на-коленке-нахуячиваю сайт нашей англоязычной студии.
Похоже, сайт нам всё же нужен, чтоб:
• больше не объяснять на пальцах, чем именно мы занимаемся («Ви мерк подкастс, хол продакшен, юноу?»);
• чтоб клиенты могли нам написать не только в LinkedIn, но и в формочку;
• чтоб наконец появилась страничка со ссылками на все платформы, где можно слушать Fucking English;
• чтоб писать статьи про подкастинг, чтоб клиенты млели от нашего профессионализма и шли к нам прям в руки, помахивая еврами;
• чтоб хвастаться инкубатору и в IAPMEI — смотрите, у нас даже сайт есть!
Короче, у меня 5 веских причин, чтобы сделать сайт немедленно.
И вот я делаю сайт на шаблонах Wix: он обеспечивает примерно все хотелки, за одним исключением — иллюстрации. Тут Wix предлагает только стоковые фотки людей, смеющихся у маркерной доски.
А мы таким не занимаемся.
Что ж: мама говорила, если вдруг нечего пожрать, поищи на полках ещё раз — наверняка можно сделать рагу из каких-нибудь недоедышей. У нас из недоедышей обнаружилась только обложка Fucking English — кайфовая, красочная, но только одна. Так что ради сайта я эту несчастную картинку нарезаю вдоль и поперёк на иконки, плашки, фоны.
Так наш лендинг стал намного пикантнее, чем я задумывала
«У вас есть сайт компании?» — это второй вопрос, который нам задают сразу после «Чем вы занимаетесь?». Поэтому сегодня на-коленке-нахуячиваю сайт нашей англоязычной студии.
Похоже, сайт нам всё же нужен, чтоб:
• больше не объяснять на пальцах, чем именно мы занимаемся («Ви мерк подкастс, хол продакшен, юноу?»);
• чтоб клиенты могли нам написать не только в LinkedIn, но и в формочку;
• чтоб наконец появилась страничка со ссылками на все платформы, где можно слушать Fucking English;
• чтоб писать статьи про подкастинг, чтоб клиенты млели от нашего профессионализма и шли к нам прям в руки, помахивая еврами;
• чтоб хвастаться инкубатору и в IAPMEI — смотрите, у нас даже сайт есть!
Короче, у меня 5 веских причин, чтобы сделать сайт немедленно.
И вот я делаю сайт на шаблонах Wix: он обеспечивает примерно все хотелки, за одним исключением — иллюстрации. Тут Wix предлагает только стоковые фотки людей, смеющихся у маркерной доски.
А мы таким не занимаемся.
Что ж: мама говорила, если вдруг нечего пожрать, поищи на полках ещё раз — наверняка можно сделать рагу из каких-нибудь недоедышей. У нас из недоедышей обнаружилась только обложка Fucking English — кайфовая, красочная, но только одна. Так что ради сайта я эту несчастную картинку нарезаю вдоль и поперёк на иконки, плашки, фоны.
Так наш лендинг стал намного пикантнее, чем я задумывала
{kind=link}
👍26😁15🔥9👎4
Привет, полуночники!
Ну всё, пикантный сайт слепила:
https://hatchupstudio.wixsite.com/mysite
• над текстами чур не хихикать, они собраны гугл-транслейтером;
• фотки и отзывы тоже рыбные, зато очаровательные;
• в блог вообще лучше не ходить, там 404;
• в мобильной версии всё разваливается.
В общем, MVP. Зато в нём — Фрида Кало, леопардовый принт и жопка французской бульдожки.
🥳 🥳 🥳
Что ж, теперь у меня будет время снова заняться сайтом только на следующей неделе — и то всего пара часов. Что посоветуете изменить в нём прям в первую очередь?
А пока вы пишите советы, я пойду пить вино и втыкать в сериалы. Завтра будет ещё один сложный день
Ну всё, пикантный сайт слепила:
https://hatchupstudio.wixsite.com/mysite
• над текстами чур не хихикать, они собраны гугл-транслейтером;
• фотки и отзывы тоже рыбные, зато очаровательные;
• в блог вообще лучше не ходить, там 404;
• в мобильной версии всё разваливается.
В общем, MVP. Зато в нём — Фрида Кало, леопардовый принт и жопка французской бульдожки.
🥳 🥳 🥳
Что ж, теперь у меня будет время снова заняться сайтом только на следующей неделе — и то всего пара часов. Что посоветуете изменить в нём прям в первую очередь?
А пока вы пишите советы, я пойду пить вино и втыкать в сериалы. Завтра будет ещё один сложный день
{kind=link}
🔥32👎7👍5😁5
This media is not supported in your browser
VIEW IN TELEGRAM
🤔15👍4👎4🔥2😁1