
Проверить, есть ли элемент в огромной коллекции
Как мы выяснили в прошлый раз, проверка на вхождение элемента в множество выполняется моментально, но занимает прилично места:
Для множества на 1 млн элементов получилось 160 микросекунд на 1000 проверок, 101 Мб в памяти.
Что если элементов будет 1 млрд? Это уже около 100 Гб, не хотелось бы держать их в памяти. Устроил бы компромиссный вариант, который работает медленнее, но занимает меньше места.
И он существует! Это фильтр Блума — специальная вероятностная структура данных. Она отвечает на вопрос «есть ли элемент в коллекции?» одним из двух вариантов:
— точно нет;
— возможно есть.
Вот как это работает:
Фильтр Блума на 1 млн элементов с вероятностью ложно-положительного ответа 0.1% занимает всего 3 Мб (вместо 100 Мб «честного» множества). А что со скоростью?
15 миллисекунд — это в 100 раз медленнее, чем проверка по множеству, но всё ещё достаточно быстро (например, в 600 раз быстрее проверки по списку).
Проверим на 1 млрд:
Три с лишним гигабайта, рост линейный. Чудес не бывает, но выигрыш по памяти в 30 раз при сохранении приемлемой скорости иногда может вам пригодиться.
#пакетик
Как мы выяснили в прошлый раз, проверка на вхождение элемента в множество выполняется моментально, но занимает прилично места:
>>> set_ = set(str(random.random()) for _ in range(1_000_000))
>>> num = str(random.random())
>>> timeit.timeit(lambda: num in set_, number=1000)
0.000160
>>> size_mb(set_)
101
Для множества на 1 млн элементов получилось 160 микросекунд на 1000 проверок, 101 Мб в памяти.
Что если элементов будет 1 млрд? Это уже около 100 Гб, не хотелось бы держать их в памяти. Устроил бы компромиссный вариант, который работает медленнее, но занимает меньше места.
И он существует! Это фильтр Блума — специальная вероятностная структура данных. Она отвечает на вопрос «есть ли элемент в коллекции?» одним из двух вариантов:
— точно нет;
— возможно есть.
Вот как это работает:
>>> from bloom_filter import BloomFilter
>>> bloom = BloomFilter(max_elements=1_000_000, error_rate=0.001)
>>> for el in set_:
... bloom.add(el)
>>> size_mb(bloom)
3
Фильтр Блума на 1 млн элементов с вероятностью ложно-положительного ответа 0.1% занимает всего 3 Мб (вместо 100 Мб «честного» множества). А что со скоростью?
>>> timeit.timeit(lambda: num in bloom, number=1000)
0.015
15 миллисекунд — это в 100 раз медленнее, чем проверка по множеству, но всё ещё достаточно быстро (например, в 600 раз быстрее проверки по списку).
Проверим на 1 млрд:
>>> bloom = BloomFilter(max_elements=1_000_000_000, error_rate=0.001)
>>> size_mb(bloom)
3428
Три с лишним гигабайта, рост линейный. Чудес не бывает, но выигрыш по памяти в 30 раз при сохранении приемлемой скорости иногда может вам пригодиться.
#пакетик
Грамотно работать с любым диапазоном
Все знают, что
Но не все знают, что
И даже так:
И так тоже:
При этом
А время выполнения операций при этом как в обычном списке:
Ну разве он не чудо?
#stdlib
Все знают, что
range() в питоне используется, когда нужно что-то сделать сколько-то раз:>>> for i in range(3, 0, -1):
... print(i)
3
2
1
Но не все знают, что
range — это коллекция (что? да!), вполне себе полноценная:>>> seq = range(10, 100)
>>> len(seq)
90
>>> 52 in seq
True
>>> seq[10]
20
И даже так:
>>> max(seq)
99
>>> seq.index(31)
21
>>> seq.count(42)
1
И так тоже:
>>> s1 = range(0, 10, 3)
>>> s2 = range(0, 11, 3)
>>> s1 == s2
True
При этом
range, в отличие от всех прочих коллекций, занимает мизерное место в памяти (48 байт), вне зависимости от того, сколько элементов в него попадают. Это потому, что хранит он только 3 атрибута: start, stop, step>>>from pympler import asizeof
>>> seq = range(0, 100)
>>> asizeof.asizeof(seq)
48
>>> seq = range(0, 100_000)
>>> asizeof.asizeof(seq)
48
>>> seq = range(0, 100_000_000)
>>> asizeof.asizeof(seq)
48
А время выполнения операций при этом как в обычном списке:
len(), in, [idx] — за O(1).Ну разве он не чудо?
#stdlib
Скорость работы оператора in range
После вчерашней заметки некоторые подписчики справедливо заметили, что сложность проверки «element in list» составляет O(n), а не O(1). А я пишу, что для range она O(1). Да, вы молодцы, так и есть ツ
Действительно: чтобы проверить, есть ли элемент в списке, придётся обойти все элементы списка, пока не найдём искомый — это сложность O(n). Но в случае с диапазоном мы точно знаем первый элемент, последний элемент и шаг. Поэтому разработчики стандартной библиотеки пошли на хитрость.
Допустим, есть выражение
Проверили границы, посчитали остаток от деления, бумс, готово. Для отрицательного step работает аналогично.
Так что
#stdlib
После вчерашней заметки некоторые подписчики справедливо заметили, что сложность проверки «element in list» составляет O(n), а не O(1). А я пишу, что для range она O(1). Да, вы молодцы, так и есть ツ
Действительно: чтобы проверить, есть ли элемент в списке, придётся обойти все элементы списка, пока не найдём искомый — это сложность O(n). Но в случае с диапазоном мы точно знаем первый элемент, последний элемент и шаг. Поэтому разработчики стандартной библиотеки пошли на хитрость.
Допустим, есть выражение
x in range(start, stop, step). Для положительного step можно обойтись без перебора всех элементов, вот так:def contains(range_, x):
if x < range_.start:
return False
if x >= range_.stop:
return False
return (x - range_.start) % range_.step == 0
>>> r = range(1000, 10000, 3)
>>> contains(r, 2068)
True
>>> contains(r, 2070)
False
Проверили границы, посчитали остаток от деления, бумс, готово. Для отрицательного step работает аналогично.
Так что
in range действительно выполняется за O(1), в отличие от in list.#stdlib
Задачка: сотрудникофикатор
Время для задачки! Допустим, вы основали модный HR-стартап, который подбирает идеальные коллективы сотрудников. Дело это нелёгкое, так что начали с простой эвристики:
> Любой коллектив идеален, пока в нём не появляется Френк
Подготовили интеллектуальный алгоритм, который предлагает сотрудника:
Остался последний шаг — разработать нечто под названием
Ваша задача — реализовать
Давайте я для затравки начну заведомо неудачным вариантом:
Ссылка на репл
Форкайте, реализуйте свой
Завтра вечером покажу лучшие варианты, а потом разберём плюсы и минусы каждого.
#задачка
Время для задачки! Допустим, вы основали модный HR-стартап, который подбирает идеальные коллективы сотрудников. Дело это нелёгкое, так что начали с простой эвристики:
> Любой коллектив идеален, пока в нём не появляется Френк
Подготовили интеллектуальный алгоритм, который предлагает сотрудника:
import random
names = ["Френк", "Клер", "Зоя", "Питер", "Лукас"]
def employee():
name = random.choice(names)
return name
Остался последний шаг — разработать нечто под названием
employeficator(), что и будет подбирать дружный коллектив. Использоваться оно будет так:>>> [name for name in employeficator()]
['Зоя', 'Зоя', 'Питер']
>>> [name for name in employeficator()]
['Лукас', 'Зоя', 'Питер']
Ваша задача — реализовать
employeficator() максимально идиоматично.Давайте я для затравки начну заведомо неудачным вариантом:
def employeficator():
employees = []
name = employee()
while name != "Френк":
employees.append(name)
name = employee()
return employees
Ссылка на репл
Форкайте, реализуйте свой
employeficator() и присылайте ссылку на форк мне → @nalgeonЗавтра вечером покажу лучшие варианты, а потом разберём плюсы и минусы каждого.
#задачка
Решение: сотрудникофикатор
Разберём задачку о сотрудниках.
Для начала, что такое «идиоматично». Идиоматичный код использует «родные» конструкции языка и стандартной библиотеки, не нарушая при этом питонячий дзен (simple is better than complex, readability counts, вот это всё).
Месиво из вложенных циклов с break и continue вряд ли можно назвать идиоматичным. Точно также не будет идиоматичной «функциональная» колбаса из вызовов functools и itertools. Абсолютных критериев тут нет, но общий смысл, надеюсь, понятен.
Теперь к решению. Задача была с небольшим подвохом: искомый
Да, это функция
Но в варианте с двумя аргументами
Первый аргумент — функция или что-нибудь вызываемое (callable), второй — контрольное значение (sentinel). Каждое обращение к итератору вызывает
Это ровно то поведение, что требовалось в задаче — вызывать
Так что
P.S. Некоторые участники решили, что коллектив обязательно должен состоять из 3 сотрудников или не может включать нескольких сотрудников с одинаковыми именами. Но таких ограничений в условиях не было. Вы сами усложнили себе задачу 🤷♀️
#задачка
Разберём задачку о сотрудниках.
Для начала, что такое «идиоматично». Идиоматичный код использует «родные» конструкции языка и стандартной библиотеки, не нарушая при этом питонячий дзен (simple is better than complex, readability counts, вот это всё).
Месиво из вложенных циклов с break и continue вряд ли можно назвать идиоматичным. Точно также не будет идиоматичной «функциональная» колбаса из вызовов functools и itertools. Абсолютных критериев тут нет, но общий смысл, надеюсь, понятен.
Теперь к решению. Задача была с небольшим подвохом: искомый
employeficator() уже есть в стандартной библиотеке. Больше того, не просто в стандартной библиотеке, а в самом её сердце, в built-in функциях! Вот он:[name for name in iter(employee, "Френк")]
Да, это функция
iter(). Обычно её вызывают с одним аргументом — коллекцией:>>> seq = [1, 2, 3]
>>> it = iter(seq)
>>> next(it)
1
Но в варианте с двумя аргументами
iter() работает иначе:iter(callable, sentinel)
Первый аргумент — функция или что-нибудь вызываемое (callable), второй — контрольное значение (sentinel). Каждое обращение к итератору вызывает
callable() и возвращает результат его выполнения. А как только callable() возвращает значение sentinel, итератор прекращает работу.Это ровно то поведение, что требовалось в задаче — вызывать
employee(), пока очередной вызов не вернёт "Френк". Так что
iter() здесь — идеальное решение. Поздравляю всех, кто его предложил! Есть и другие хорошие варианты, разберём их в следующий раз.P.S. Некоторые участники решили, что коллектив обязательно должен состоять из 3 сотрудников или не может включать нескольких сотрудников с одинаковыми именами. Но таких ограничений в условиях не было. Вы сами усложнили себе задачу 🤷♀️
#задачка
Как вам задачка?
Final Results
65%
Супер, давай каждую неделю!
24%
Норм, иногда можно
11%
Не надо больше
А вот и полный разбор задачки о сотрудникофикаторе. Не обошлось без моржа: https://antonz.ru/iter-with-sentinel/
#задачка
#задачка
Антон Жиянов
Задачка об итераторе на Python
Как подобрать коллектив единомышленников с помощью random и iter
Как работать с данными без экселя и pandas
Должен признаться: я недолюбливаю пандас. Спору нет, штука мощная и вполне подходит для обработки датасетов. Но пользоваться им удобно, только если работаете с пандасом каждый день. Иначе запомнить эти десятки функций и сотни хаотичных параметров невозможно — так и будете каждый раз гуглить простейшие операции.
Авторы пандаса думали о чем угодно, только не об удобстве пользователя. Если не верите — почитайте документацию о джойне таблиц. Выглядит так, как будто космический корабль строим, хотя с точки зрения предметной области задача элементарная.
Возможно, я бы смирился и безропотно учил пандасовское API. Если бы задолго до появления pandas не придумали SQL — лаконичный, продуманный доменный язык, который идеально подходит для работы с данными. Да, для 5% задач пандас окажется лучше, но не вижу смысла поедать кактус в остальных 95%.
К чему это всё. Я запускаю курс «SQLite на практике» о том, как использовать SQLite для повседневной работы с данными:
— Быстро анализировать наборы данных.
— Строить сводные отчеты из нескольких источников.
— Загружать, трансформировать и выгружать данные в нужном формате.
— Удобно работать с JSON-документами, деревьями и графами.
Курс не по основам SQL (этого добра в интернете хватает). Вместо разжевывания синтаксиса и теории фокусируется на конкретных задачах — так участники сразу смогут применять знания в работе. Входные требования: базовое понимание SQL и любовь к командной строке.
Курс платный. Но пока он в разработке, есть места для 10 бета-тестеров — они смогут пройти всю программу бесплатно. Если вам интересно, записывайтесь.
#курс
Должен признаться: я недолюбливаю пандас. Спору нет, штука мощная и вполне подходит для обработки датасетов. Но пользоваться им удобно, только если работаете с пандасом каждый день. Иначе запомнить эти десятки функций и сотни хаотичных параметров невозможно — так и будете каждый раз гуглить простейшие операции.
Авторы пандаса думали о чем угодно, только не об удобстве пользователя. Если не верите — почитайте документацию о джойне таблиц. Выглядит так, как будто космический корабль строим, хотя с точки зрения предметной области задача элементарная.
Возможно, я бы смирился и безропотно учил пандасовское API. Если бы задолго до появления pandas не придумали SQL — лаконичный, продуманный доменный язык, который идеально подходит для работы с данными. Да, для 5% задач пандас окажется лучше, но не вижу смысла поедать кактус в остальных 95%.
К чему это всё. Я запускаю курс «SQLite на практике» о том, как использовать SQLite для повседневной работы с данными:
— Быстро анализировать наборы данных.
— Строить сводные отчеты из нескольких источников.
— Загружать, трансформировать и выгружать данные в нужном формате.
— Удобно работать с JSON-документами, деревьями и графами.
Курс не по основам SQL (этого добра в интернете хватает). Вместо разжевывания синтаксиса и теории фокусируется на конкретных задачах — так участники сразу смогут применять знания в работе. Входные требования: базовое понимание SQL и любовь к командной строке.
Курс платный. Но пока он в разработке, есть места для 10 бета-тестеров — они смогут пройти всю программу бесплатно. Если вам интересно, записывайтесь.
#курс
Спасибо всем, кто подал заявки! Желающих оказалось в несколько раз больше, чем мест, так что прием заявок я остановил 🤷В ближайшие дни напишу бета-тестерам.
Если вы оставили заявку, но не попали в тест — для вас бессрочная 50% скидка на полный курс, когда он выйдет.
Если вы оставили заявку, но не попали в тест — для вас бессрочная 50% скидка на полный курс, когда он выйдет.
Travis CI → GitHub Actions
В прошлом году я писал, как сделать классный Python-пакет. Там упоминаются полезные облачные сервисы: Travis CI для сборки, Coveralls для покрытия, Code Climate для качества кода.
Так вот, сдается мне, что Travis CI пора на покой. В 2020 году Гитхаб довел до ума свои Actions, и они просто бесподобны. Где еще вы настроите сборку и публикацию под Windows, Linux и macOS за десять минут?
Рекомендация этого года — GitHub Actions:
https://antonz.ru/github-actions/
#код
В прошлом году я писал, как сделать классный Python-пакет. Там упоминаются полезные облачные сервисы: Travis CI для сборки, Coveralls для покрытия, Code Climate для качества кода.
Так вот, сдается мне, что Travis CI пора на покой. В 2020 году Гитхаб довел до ума свои Actions, и они просто бесподобны. Где еще вы настроите сборку и публикацию под Windows, Linux и macOS за десять минут?
Рекомендация этого года — GitHub Actions:
https://antonz.ru/github-actions/
#код
Простое против легкого
9 лет назад в докладе «Simple Made Easy» Рич Хикки рассказал о разнице между простым (simple) и легким (easy) в разработке софта. Стремление к простым программам (в противоположность легким) — самый важный, наверное, принцип разработки. И при этом совершенно непопулярный.
Simple — это о внутреннем устройстве программы, ее архитектуре. У простых программ мало внутренних зависимостей, движущихся частей, настроек. Антипод простой программы — сложная. Простая программа или сложная — это объективная характеристика.
Easy — это о том, насколько человеку легко работать с программой. Это субъективная характеристика: что мне легко, другому сложно, и наоборот. Антипод легкой программы — тяжелая.
Например, SQLite — легкая, но не простая. Внутри там ад, особенно в системе типов и взаимовлиянии многочисленных параметров. А Redis — простой. Но для многих не такой легкий, как SQLite, потому что непривычный. Docker — «легкий», но сложный. Kubernetes — тяжелый и адово сложный.
JavaScript — легкий, но очень сложно устроен. Python — тоже легкий и сложный, хотя и попроще джаваскрипта. Go — простой.
Модули стандартной библиотеки bisect и heapq — простые. Но не легкие, если вы не знаете алгоритмов, которые они реализуют. dataclasses и namedtuple созданы, чтобы быть легкими, но при этом очень сложные.
Простые программы в долгой перспективе лучше легких. В простой программе оказывается легче разобраться, легче использовать на реальных сценариях, легче менять и дорабатывать. Легкую (но при этом сложную) программу можно быстро начать использовать, но дальше ждет стена.
Разработчики предпочитают писать «легкие» программы, а не простые — потому что простые делать тяжело. Придется продумывать архитектуру, работать с ограничениями, много раз переписывать. Намного легче слепить из палочек и веточек, а сверху приделать «легкий» интерфейс.
Я очень хочу, чтобы в мире софта появлялось больше простых, а не «легких» программ и библиотек. А у вас есть любимые простые штуки?
#код
9 лет назад в докладе «Simple Made Easy» Рич Хикки рассказал о разнице между простым (simple) и легким (easy) в разработке софта. Стремление к простым программам (в противоположность легким) — самый важный, наверное, принцип разработки. И при этом совершенно непопулярный.
Simple — это о внутреннем устройстве программы, ее архитектуре. У простых программ мало внутренних зависимостей, движущихся частей, настроек. Антипод простой программы — сложная. Простая программа или сложная — это объективная характеристика.
Easy — это о том, насколько человеку легко работать с программой. Это субъективная характеристика: что мне легко, другому сложно, и наоборот. Антипод легкой программы — тяжелая.
Например, SQLite — легкая, но не простая. Внутри там ад, особенно в системе типов и взаимовлиянии многочисленных параметров. А Redis — простой. Но для многих не такой легкий, как SQLite, потому что непривычный. Docker — «легкий», но сложный. Kubernetes — тяжелый и адово сложный.
JavaScript — легкий, но очень сложно устроен. Python — тоже легкий и сложный, хотя и попроще джаваскрипта. Go — простой.
Модули стандартной библиотеки bisect и heapq — простые. Но не легкие, если вы не знаете алгоритмов, которые они реализуют. dataclasses и namedtuple созданы, чтобы быть легкими, но при этом очень сложные.
Простые программы в долгой перспективе лучше легких. В простой программе оказывается легче разобраться, легче использовать на реальных сценариях, легче менять и дорабатывать. Легкую (но при этом сложную) программу можно быстро начать использовать, но дальше ждет стена.
Разработчики предпочитают писать «легкие» программы, а не простые — потому что простые делать тяжело. Придется продумывать архитектуру, работать с ограничениями, много раз переписывать. Намного легче слепить из палочек и веточек, а сверху приделать «легкий» интерфейс.
Я очень хочу, чтобы в мире софта появлялось больше простых, а не «легких» программ и библиотек. А у вас есть любимые простые штуки?
#код
🎙️ Сегодня я узнал
Всегда хотел слушать короткий подкаст о разработке. Только не новостной, а практический. В итоге как-то так получилось, что сделал сам 🤷
Называется «Сегодня я узнал». Вот основные принципы:
1) Никакой пустой болтовни. Никаких рассуждений об очередном айфоне, цене биткойна или что там Маск написал в твитере.
2) Только практические штуки. В каждом выпуске — одна тема, которую можно взять и сразу применять на работе или в жизни.
3) Очень короткие эпизоды — пять минут или около того. Не хочу долго занимать эфир, да и вообще длинных подкастов уже достаточно.
Доступен в Apple и Google Podcasts. Если интересен такой формат — подписывайтесь!
https://we.fo/1556171504
#подкаст
Всегда хотел слушать короткий подкаст о разработке. Только не новостной, а практический. В итоге как-то так получилось, что сделал сам 🤷
Называется «Сегодня я узнал». Вот основные принципы:
1) Никакой пустой болтовни. Никаких рассуждений об очередном айфоне, цене биткойна или что там Маск написал в твитере.
2) Только практические штуки. В каждом выпуске — одна тема, которую можно взять и сразу применять на работе или в жизни.
3) Очень короткие эпизоды — пять минут или около того. Не хочу долго занимать эфир, да и вообще длинных подкастов уже достаточно.
Доступен в Apple и Google Podcasts. Если интересен такой формат — подписывайтесь!
https://we.fo/1556171504
#подкаст
we.fo
Сегодня я узнал | We.fo - Fast podcast sharing
Компактный практический подкаст о программировании и продуктах.
Python ❤️ SQLite
Создавать новые функции в SQLite через Python — одно удовольствие. Например, хотим привести заголовки новостей к Title Case:
Вот так просто ツ
#stdlib
Создавать новые функции в SQLite через Python — одно удовольствие. Например, хотим привести заголовки новостей к Title Case:
import sqlite3
def title(value):
return value.title()
query = "select title(headline) from news"
db = sqlite3.connect("news.db")
db.create_function("title", 1, title)
cursor = db.execute(query)
result = cursor.fetchall()
db.close()Вот так просто ツ
#stdlib
SQLite для аналитики
или как работать с данными без экселя и pandas
В январе я начал делать курс о том, как использовать SQLite для повседневной работы с данными. И наконец он готов! Вот чему научатся участники:
— Загружать и выгружать данные в разных форматах.
— Находить проблемы в данных и исправлять их.
— Соединять данные так и сяк, чтобы получить нужную информацию.
— Оценивать статистические показатели, которые характеризуют датасет.
— Выбирать данные из JSON-документов любой сложности.
— Быстро работать с большими наборами данных.
— Строить аналитические отчеты с помощью оконных функций.
Входные требования: базовое понимание SQL и любовь к командной строке. Навыки программирования не требуются.
Курс платный, стоит 3000₽. Специально для подписчиков канала до конца недели действует скидка 500₽ по промокоду OHMYPY.
Для всех, кто оставлял заявку на бета-тест — бессрочная скидка 50%, как обещал (пишите в личку @nalgeon).
Первый модуль курса (5 уроков и 13 практических заданий) доступен для всех бесплатно и без регистрации.
Перейти к курсу
#курс
или как работать с данными без экселя и pandas
В январе я начал делать курс о том, как использовать SQLite для повседневной работы с данными. И наконец он готов! Вот чему научатся участники:
— Загружать и выгружать данные в разных форматах.
— Находить проблемы в данных и исправлять их.
— Соединять данные так и сяк, чтобы получить нужную информацию.
— Оценивать статистические показатели, которые характеризуют датасет.
— Выбирать данные из JSON-документов любой сложности.
— Быстро работать с большими наборами данных.
— Строить аналитические отчеты с помощью оконных функций.
Входные требования: базовое понимание SQL и любовь к командной строке. Навыки программирования не требуются.
Курс платный, стоит 3000₽. Специально для подписчиков канала до конца недели действует скидка 500₽ по промокоду OHMYPY.
Для всех, кто оставлял заявку на бета-тест — бессрочная скидка 50%, как обещал (пишите в личку @nalgeon).
Первый модуль курса (5 уроков и 13 практических заданий) доступен для всех бесплатно и без регистрации.
Перейти к курсу
#курс
📦 Как сделать классный Python-пакет в 2021
В прошлом году я написал инструкцию, как сделать модный и современный питонячий пакет. Рекомендовал там использовать Travis CI.
А потом распробовал альтернативу — GitHub Actions. Это бесконечно крутой сервис, который использую теперь буквально для всего. Ну и для тестирования и публикации пакетов тоже, конечно.
Использовать Тревис больше нет никакого смысла. Поэтому вот новая версия руководства: https://antonz.ru/packaging/
#код
В прошлом году я написал инструкцию, как сделать модный и современный питонячий пакет. Рекомендовал там использовать Travis CI.
А потом распробовал альтернативу — GitHub Actions. Это бесконечно крутой сервис, который использую теперь буквально для всего. Ну и для тестирования и публикации пакетов тоже, конечно.
Использовать Тревис больше нет никакого смысла. Поэтому вот новая версия руководства: https://antonz.ru/packaging/
#код
Утилиты для работы с данными на питоне
В последнее время думаю о таком курсе для прокачки навыков Python. Курс состоит из набора уроков, на каждом уроке воспроизводим на чистом питоне с нуля одну из линуксовых утилит: head, cut, tr, wc, split, paste, sort, uniq, grep, sed. Используем только модули стандартной библиотеки.
Плюсы:
— Одновременно осваиваешь сами утилиты и прокачиваешь питон.
— Учишься эффективно работать со структурами данных.
— Осваиваешь самые разные модули стандартной библиотеки.
— Результат можно использовать в повседневной работе.
— Уроки независимые, можно начинать с любого или выполнять выборочно.
Минусы:
— Курс по питону не сделал только ленивый, лезть в это неохота.
Что думаете?
#курс
В последнее время думаю о таком курсе для прокачки навыков Python. Курс состоит из набора уроков, на каждом уроке воспроизводим на чистом питоне с нуля одну из линуксовых утилит: head, cut, tr, wc, split, paste, sort, uniq, grep, sed. Используем только модули стандартной библиотеки.
Плюсы:
— Одновременно осваиваешь сами утилиты и прокачиваешь питон.
— Учишься эффективно работать со структурами данных.
— Осваиваешь самые разные модули стандартной библиотеки.
— Результат можно использовать в повседневной работе.
— Уроки независимые, можно начинать с любого или выполнять выборочно.
Минусы:
— Курс по питону не сделал только ленивый, лезть в это неохота.
Что думаете?
#курс
Что думаете о курсе?
Anonymous Poll
15%
Немедленно начну
52%
В целом интересно
20%
Скорее нет
13%
Точно не нужно
Шпаргалки как альтернатива man
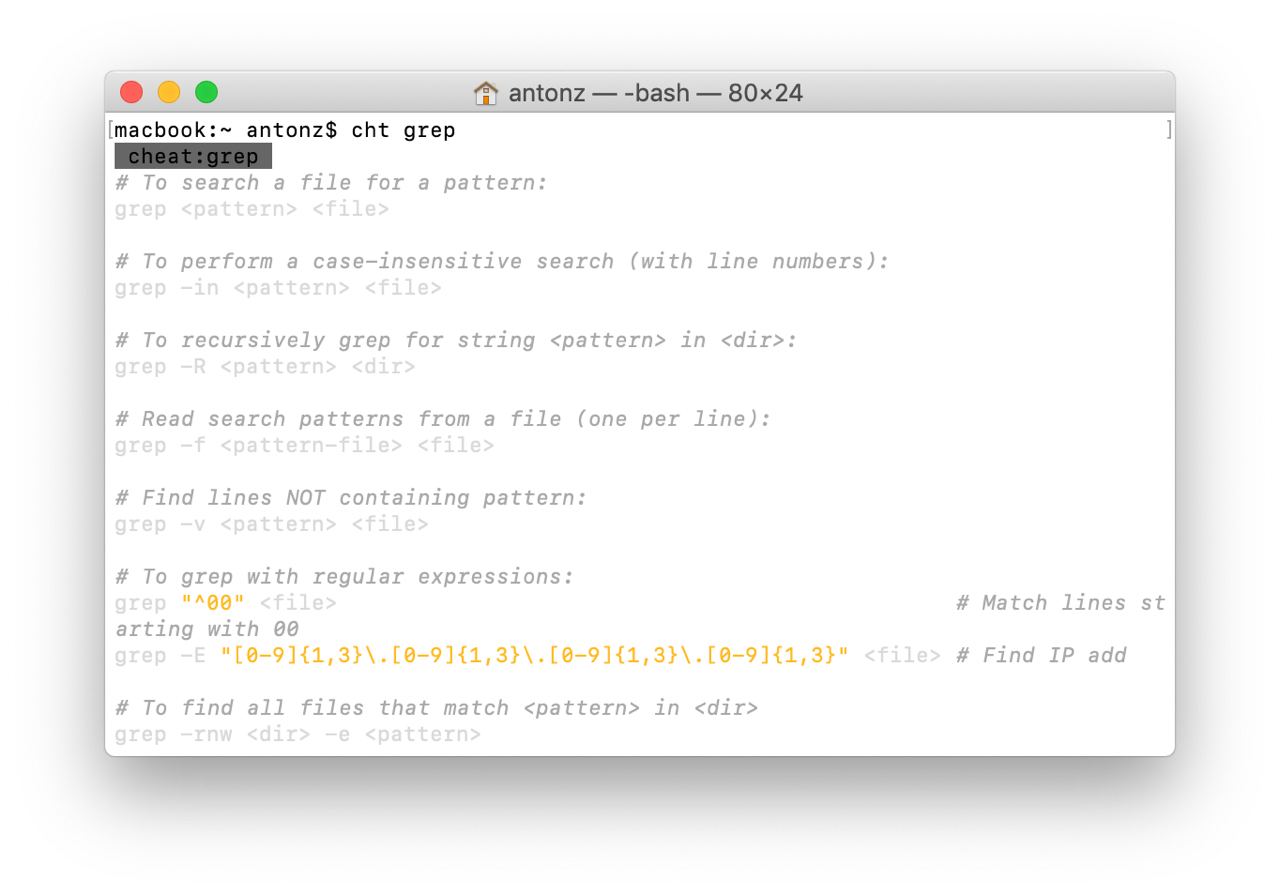
Я вечно забываю синтаксис линуксовых утилит вроде
Поэтому я был бесконечно счастлив, когда на днях нашел приятную альтернативу от Игоря Чубина — «шпаргалки» с конкретными примерами. Чтобы их включить, достаточно добавить такую функцию в
И вызвать шпаргалку по конкретной команде:
Есть консольный клиент и много всяких наворотов, подробности в репозитории автора.
Я вечно забываю синтаксис линуксовых утилит вроде
grep, sed и find. Есть команда man, которая показывает документацию по утилите, но для меня она совершенно бесполезна — никогда не получается найти то, что нужно (возможно, это только я такой тупой).Поэтому я был бесконечно счастлив, когда на днях нашел приятную альтернативу от Игоря Чубина — «шпаргалки» с конкретными примерами. Чтобы их включить, достаточно добавить такую функцию в
.bashrc:function cht() { curl "cht.sh/$1"; }И вызвать шпаргалку по конкретной команде:
$ cht grep
$ cht sed
$ cht tr
Есть консольный клиент и много всяких наворотов, подробности в репозитории автора.
{kind=link}
Второй язык для питониста
Если вы давно и хорошо знаете питон, некоторые моменты в нем могут напрягать. Например, необходимость начинать каждый новый проект с создания виртуального окружения и установки пачки тулов вроде black, pylint и pytest. Или отсутствующий рефакторинг и частые ошибки из-за динамической типизации. Или убоговатая асинхронность и костыль в виде GIL.
Если у вас так — возможно, пора освоить второй язык. Логично выбрать вариант без питонячих недостатков: статически типизированный, с готовым тулингом, продуманной асинхронностью и параллелизмом.
Давайте посмотрим, кто из топа StackOverflow подходят на роль второго языка.
JavaScript. Динамический язык, который во всем хуже питона. Единственный плюс — только с ним нативно работают браузеры. Если мечтаете о фронтенде — хороший выбор, если нет — с негодованием отметаем.
Bash/Shell/PowerShell. Моя любимая тройка write-only языков! Легко написать что угодно, уже через неделю невозможно понять, что написал. Нет.
C#. Интересный вариант. Новее питона, отличная стандартная библиотека, статически типизирован, все в порядке с асинхронностью. Начинался как очень простой, но за 20 лет превратился в один из самых фичастых языков. Кросс-платформенный, несмотря на виндовые корни.
PHP. Динамический язык с тяжелым наследием, который в свежих версиях решили превратить в Java образца 2005 года. Я даже не знаю, что может быть хуже.
TypeScript. А это JavaScript, который решили превратить в современную Java. Классическая дырявая абстракция, джаваскрипт протекает из всех щелей. Статически типизирован, куча наворотов. Стандартная библиотека отсутствует. Фронтендеры на него молятся, но у питониста вряд ли вызовет что-то помимо отвращения.
C++. В рейтинге мозговыносящих языков точно занял бы первое место. Старый язык, в который запихнули все что только можно. Гарантирую, писать на C++ вам будет физически больно.
C. Самый старый, но относительно простой язык. Статические типы, очень низкоуровневый, скудная стандартная библиотека. В 1991 году был бы хорошим выбором. Зато быстрый, да.
Go. Интересный вариант. Новый, отличная стандартная библиотека, статически типизирован, классная асинхронность. Одним из основных принципов считает простоту, так что не превратился в фича-монстра, в отличие от C#. Можно делать как низкоуровневые штуки, так и бизнес-приложения.
Kotlin. Интересный вариант. Котлин — это Java, если бы ее изобрели в 2010 году. Статический, много фич. Работает поверх JVM (виртуальная машина джавы), можно использовать любые джава-либы.
И несколько нишевых языков с преданным сообществом:
Rust. Современная альтернатива C++. Отличный вариант для низкоуровневых штук, плохо подходит для остального. Много фич, тяжело освоить. Хорошая стандартная библиотека.
Clojure. Современный LISP. Язык, в котором простота возведена в абсолют — всё есть данные. Акцент на неизменяемых данных, продуманная стандартная библиотека. Работает поверх JVM.
Итого, из топ-10 мне кажутся интересными C#, Go и Kotlin. Лично я выбрал Go, потому что устал от фичастых языков и наслоений абстракций. Хочу простоты.
Если вам тоже интересно попробовать — присоединяйтесь ко мне на бесплатном курсе:
https://stepik.org/96832
Если вы давно и хорошо знаете питон, некоторые моменты в нем могут напрягать. Например, необходимость начинать каждый новый проект с создания виртуального окружения и установки пачки тулов вроде black, pylint и pytest. Или отсутствующий рефакторинг и частые ошибки из-за динамической типизации. Или убоговатая асинхронность и костыль в виде GIL.
Если у вас так — возможно, пора освоить второй язык. Логично выбрать вариант без питонячих недостатков: статически типизированный, с готовым тулингом, продуманной асинхронностью и параллелизмом.
Давайте посмотрим, кто из топа StackOverflow подходят на роль второго языка.
JavaScript. Динамический язык, который во всем хуже питона. Единственный плюс — только с ним нативно работают браузеры. Если мечтаете о фронтенде — хороший выбор, если нет — с негодованием отметаем.
Bash/Shell/PowerShell. Моя любимая тройка write-only языков! Легко написать что угодно, уже через неделю невозможно понять, что написал. Нет.
C#. Интересный вариант. Новее питона, отличная стандартная библиотека, статически типизирован, все в порядке с асинхронностью. Начинался как очень простой, но за 20 лет превратился в один из самых фичастых языков. Кросс-платформенный, несмотря на виндовые корни.
PHP. Динамический язык с тяжелым наследием, который в свежих версиях решили превратить в Java образца 2005 года. Я даже не знаю, что может быть хуже.
TypeScript. А это JavaScript, который решили превратить в современную Java. Классическая дырявая абстракция, джаваскрипт протекает из всех щелей. Статически типизирован, куча наворотов. Стандартная библиотека отсутствует. Фронтендеры на него молятся, но у питониста вряд ли вызовет что-то помимо отвращения.
C++. В рейтинге мозговыносящих языков точно занял бы первое место. Старый язык, в который запихнули все что только можно. Гарантирую, писать на C++ вам будет физически больно.
C. Самый старый, но относительно простой язык. Статические типы, очень низкоуровневый, скудная стандартная библиотека. В 1991 году был бы хорошим выбором. Зато быстрый, да.
Go. Интересный вариант. Новый, отличная стандартная библиотека, статически типизирован, классная асинхронность. Одним из основных принципов считает простоту, так что не превратился в фича-монстра, в отличие от C#. Можно делать как низкоуровневые штуки, так и бизнес-приложения.
Kotlin. Интересный вариант. Котлин — это Java, если бы ее изобрели в 2010 году. Статический, много фич. Работает поверх JVM (виртуальная машина джавы), можно использовать любые джава-либы.
И несколько нишевых языков с преданным сообществом:
Rust. Современная альтернатива C++. Отличный вариант для низкоуровневых штук, плохо подходит для остального. Много фич, тяжело освоить. Хорошая стандартная библиотека.
Clojure. Современный LISP. Язык, в котором простота возведена в абсолют — всё есть данные. Акцент на неизменяемых данных, продуманная стандартная библиотека. Работает поверх JVM.
Итого, из топ-10 мне кажутся интересными C#, Go и Kotlin. Лично я выбрал Go, потому что устал от фичастых языков и наслоений абстракций. Хочу простоты.
Если вам тоже интересно попробовать — присоединяйтесь ко мне на бесплатном курсе:
https://stepik.org/96832
Stepik: online education
Thank Go! Golang на практике
Осваиваем Golang на практических задачах. Для опытных разработчиков, которые хотят быстро начать применять Go в работе.