
У меня на канале был пост про продуктовый подход
И вот недавно моя супруга написала пост в linkedin о том как проводить custdev по мотивам лекции Ивана Замесина по основам Customer Development
Рекомендую к прочтению, если вы создаете или собираетесь создать свой продукт.
Лайки к посту приветствуются 😊
PS
Супруга кстати находится сейчас в поиске новой карьерной возможности 😉
И вот недавно моя супруга написала пост в linkedin о том как проводить custdev по мотивам лекции Ивана Замесина по основам Customer Development
Рекомендую к прочтению, если вы создаете или собираетесь создать свой продукт.
Лайки к посту приветствуются 😊
PS
Супруга кстати находится сейчас в поиске новой карьерной возможности 😉
{kind=link}
Бесплатные курсы по генеративным AI
Я недавно писал про курс по использованию chatGPT и решил пройти остальные бесплатные короткие курсы
Вот небольшие отзывы на них:
- ChatGPT Prompt Engineering for Developers - курс не показался интересным, курс по использованию chatGPT куда полезнее и практичнее
- Building Systems with the ChatGPT API - курс поинтереснее, рассказывает про проектирование систем в основе которых лежат LLM
- LangChain for LLM Application Development - курс крутой и полезный, если вы еще не юзали LangChain в своих проектах, то этот курс поможет понять как использовать LangChain. Работать с контекстом, памятью и многим другим.
- LangChain: Chat with Your Data - тоже полезный курс, по сути расширяет предыдущий. Рассказывают и показывают как использовать свои данные для ChatGPT№
- Finetuning Large Language Models - тут всё понятно, показывают как тюнить модель для вашего домена
- Building Generative AI Applications with Gradio - крутой курс, после которого я задумался юзать для демок не streamlit, а Gradio
Отмечу, что во всех этих миникурсах есть Jupyter ноутбук в котором можно удобно поиграться.
Я недавно писал про курс по использованию chatGPT и решил пройти остальные бесплатные короткие курсы
Вот небольшие отзывы на них:
- ChatGPT Prompt Engineering for Developers - курс не показался интересным, курс по использованию chatGPT куда полезнее и практичнее
- Building Systems with the ChatGPT API - курс поинтереснее, рассказывает про проектирование систем в основе которых лежат LLM
- LangChain for LLM Application Development - курс крутой и полезный, если вы еще не юзали LangChain в своих проектах, то этот курс поможет понять как использовать LangChain. Работать с контекстом, памятью и многим другим.
- LangChain: Chat with Your Data - тоже полезный курс, по сути расширяет предыдущий. Рассказывают и показывают как использовать свои данные для ChatGPT№
- Finetuning Large Language Models - тут всё понятно, показывают как тюнить модель для вашего домена
- Building Generative AI Applications with Gradio - крутой курс, после которого я задумался юзать для демок не streamlit, а Gradio
Отмечу, что во всех этих миникурсах есть Jupyter ноутбук в котором можно удобно поиграться.
Почему анализ ошибок – это начало разработки ML системы, а не конец?
Наткнулся на интересную статью про анализ ошибок ML моделей.
Это действительно один из самых недооцененных этапов работы с моделью, который часто не делают или делают не самым верным способом.
В статье раскрыты методы и подходы для работы с анализом ошибок.
Рекомендую к прочтению
Ссылка: https://habr.com/ru/articles/760550/
Наткнулся на интересную статью про анализ ошибок ML моделей.
Это действительно один из самых недооцененных этапов работы с моделью, который часто не делают или делают не самым верным способом.
В статье раскрыты методы и подходы для работы с анализом ошибок.
Рекомендую к прочтению
Ссылка: https://habr.com/ru/articles/760550/
Forwarded from Артета позвонит
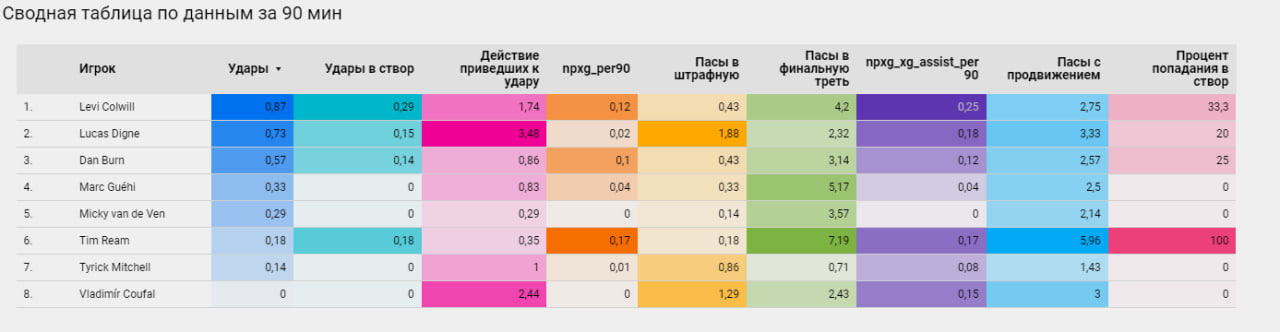
Дэшборд для игроков в фэнтези АПЛ
Напилил дэшборд по всей возможной статистике с сайта FbRef.
Данные обновляются ежедневно.
Вы можете изучить разные показатели для планирования выбора игроков для состава в фэнтези или для подготовки статей в медиа.
Обратите внимание, что можно выбрать количество сыгранных матчей и сыгранных матчей в старте. Это очень важно для фэнтези АПЛ.
Можно так выбирать конкретных игроков для их сравнения. На скрине я сравнивал защитников в ценовом диапазоне - 4.5-4.6 миллиона
Ссылка на дэшборд
Напилил дэшборд по всей возможной статистике с сайта FbRef.
Данные обновляются ежедневно.
Вы можете изучить разные показатели для планирования выбора игроков для состава в фэнтези или для подготовки статей в медиа.
Обратите внимание, что можно выбрать количество сыгранных матчей и сыгранных матчей в старте. Это очень важно для фэнтези АПЛ.
Можно так выбирать конкретных игроков для их сравнения. На скрине я сравнивал защитников в ценовом диапазоне - 4.5-4.6 миллиона
Ссылка на дэшборд
{kind=link}
Классные дата сайенс вакансии с релокацией в Германию
Ребята из https://www.datajob.io/ ведут курируемую подборку вакансий в дата сайенсе в Германии. В подборку Data Job (https://www.tg-me.com/datajob_io) попадают вакансии:
✅ для дата сайентистов разных грейдов
✅ с интересными задачами в ML, DL, NLP, CV
✅ на английском языке
✅ и возможностью релокации в Германию
Кроме того, на сайте вы найдете блог с полезными советами по жизни (и бюрократии) в Германии.
Подписывайтесь на телеграмм канал Data Job и на имейл рассылку. На этой неделе будет опубликована очередная подборка. 🤺
PS Ребята с удовольствием принимают фидбэк и идеи, которые помогут улучшить сервис.
Ребята из https://www.datajob.io/ ведут курируемую подборку вакансий в дата сайенсе в Германии. В подборку Data Job (https://www.tg-me.com/datajob_io) попадают вакансии:
✅ для дата сайентистов разных грейдов
✅ с интересными задачами в ML, DL, NLP, CV
✅ на английском языке
✅ и возможностью релокации в Германию
Кроме того, на сайте вы найдете блог с полезными советами по жизни (и бюрократии) в Германии.
Подписывайтесь на телеграмм канал Data Job и на имейл рассылку. На этой неделе будет опубликована очередная подборка. 🤺
PS Ребята с удовольствием принимают фидбэк и идеи, которые помогут улучшить сервис.
{kind=link}
-- Доступно от 15 до 20 часов в неделю для фриланс работы --
Сейчас я доступен от 15 до 20 часов (0,5 FTE) в неделю на позиции аналитика данных, дата сайентиста и ML инженера.
Предпочтительно в сфере AdTech, MedTech, EduTech, футбола и спорта.
Если у вас есть интересные предложения, вы можете связаться со мной через:
- [email protected]
- telegram: @alimbekovkz
- LinkedIn
Сейчас я доступен от 15 до 20 часов (0,5 FTE) в неделю на позиции аналитика данных, дата сайентиста и ML инженера.
Предпочтительно в сфере AdTech, MedTech, EduTech, футбола и спорта.
Если у вас есть интересные предложения, вы можете связаться со мной через:
- [email protected]
- telegram: @alimbekovkz
Evidently и кастомные метрики
Дописал пост про Evidently и кастомные метрики.
Эту работу мы еще начали в Билайне и вот теперь уже Pull request приняли. Теперь в Evidently есть lift метрика и её визуализация.
Пост: https://alimbekov.com/evidently-%d0%b8-%d0%ba%d0%b0%d1%81%d1%82%d0%be%d0%bc%d0%bd%d1%8b%d0%b5-%d0%bc%d0%b5%d1%82%d1%80%d0%b8%d0%ba%d0%b8/
Спасибо @EvidentlyAI за принятый и допиленный pull request
Дописал пост про Evidently и кастомные метрики.
Эту работу мы еще начали в Билайне и вот теперь уже Pull request приняли. Теперь в Evidently есть lift метрика и её визуализация.
Пост: https://alimbekov.com/evidently-%d0%b8-%d0%ba%d0%b0%d1%81%d1%82%d0%be%d0%bc%d0%bd%d1%8b%d0%b5-%d0%bc%d0%b5%d1%82%d1%80%d0%b8%d0%ba%d0%b8/
Спасибо @EvidentlyAI за принятый и допиленный pull request
Персональный блог Рената Алимбекова - Data Science, ML и Analytics Engineering
Evidently и кастомные метрики
Evidently и кастомные метрики Это библиотека, которая помогает анализировать модели машинного обучения во время проверки или мониторинга продакшена
Лайфхак от моего товарища
Как то раз сижу я читаю очередной пейпер и параллельно переключаюсь на vscode и контраст прям по глазам бьет.
Нашел способ все arxiv пейперы сделать черными, просто вместо .org ставите .black
Например: https://arxiv.black/pdf/1706.03762.pdf
Как то раз сижу я читаю очередной пейпер и параллельно переключаюсь на vscode и контраст прям по глазам бьет.
Нашел способ все arxiv пейперы сделать черными, просто вместо .org ставите .black
Например: https://arxiv.black/pdf/1706.03762.pdf
{kind=link}
Сегодня «Черная пятница», то есть день лютых скидок. Скидка 50% на все книги и курсы.
Только до 5 декабря
- Data Science Interview Guide (на англ. языке) по промокоду BLACKFRIDAY скидка 50%, 2.5 $
- Medical Image Analysis In Python (на англ. языке) по промокоду BLACKFRIDAY скидка 50%, 1.5$
- Руководство по подготовке к Data Science интервью (на рус. языке) по промокоду BLACKFRIDAY скидка 50%, 2.5 $
Промокод необходимо вводить в момент оформления заказа.
Всем приятной учебы и выходных!
Только до 5 декабря
- Data Science Interview Guide (на англ. языке) по промокоду BLACKFRIDAY скидка 50%, 2.5 $
- Medical Image Analysis In Python (на англ. языке) по промокоду BLACKFRIDAY скидка 50%, 1.5$
- Руководство по подготовке к Data Science интервью (на рус. языке) по промокоду BLACKFRIDAY скидка 50%, 2.5 $
Промокод необходимо вводить в момент оформления заказа.
Всем приятной учебы и выходных!
Как нанимать сотрудников класса А? Выжимка из книги "Who: The A Method For Hiring"
Если вы сейчас ищете работу или сами нанимаете людей себе в команду, то рекомендую прочитать статью с кратким содержанием книги "Who: The A Method For Hiring"
Если вы сейчас ищете работу или сами нанимаете людей себе в команду, то рекомендую прочитать статью с кратким содержанием книги "Who: The A Method For Hiring"
{kind=link}
Наткнулся на классный гайд по файнтюнингу LLM от Sebastian Raschka
Себастьян достаточно известный рисерчер и автор книг по Deep Learning
Так же у него есть крутой репозиторий по построению LLM моделей From Scratch
Себастьян достаточно известный рисерчер и автор книг по Deep Learning
Так же у него есть крутой репозиторий по построению LLM моделей From Scratch
YouTube
Insights from Finetuning LLMs with Low-Rank Adaptation
Links:- LoRA: Low-Rank Adaptation of Large Language Models, https://arxiv.org/abs/2106.09685- LitGPT: https://github.com/Lightning-AI/lit-gpt- LitGPT LoRA Tu...
Курс по мониторингу моделей в продакшене
Курс от одной из фаундеров Evidently Эмели Драль про мониторинг моделей/ данных в продакшене.
Я уже довольно много писал про Evidently: в канале есть обзорный пост, а в блоге есть пост про кастомные метрики
Но в этом мини курсе дано гораздо больше полезного материала. Например:
- Различные методы оценки
- Качество данных
- Дрифт данных
- Мониторинг LLM
- Развертывание и интеграция
А еще это все приправлено упражнениями на кодинг
Ссылка на курс
Курс от одной из фаундеров Evidently Эмели Драль про мониторинг моделей/ данных в продакшене.
Я уже довольно много писал про Evidently: в канале есть обзорный пост, а в блоге есть пост про кастомные метрики
Но в этом мини курсе дано гораздо больше полезного материала. Например:
- Различные методы оценки
- Качество данных
- Дрифт данных
- Мониторинг LLM
- Развертывание и интеграция
А еще это все приправлено упражнениями на кодинг
Ссылка на курс
Forwarded from DataEng
Всем привет!
Я сделал курс по Luigi бесплатным для всех, велком изучать — Введение в Data Engineering: дата-пайплайны
Luigi это компактный инструмент для построения зависимых между собой задач на базе нескольких сущностей: Task, Target. Он идеально подойдёт там, где Airflow кажется избыточным инструментом. В далёком 2017 году я писал небольшой обзорный пост на Luigi у себя в блоге: Строим Data Pipeline на Python и Luigi. С тех пор мало что изменилось в концепции инструмента, он по прежнему компактный и простой, именно в этом вся его прелесть.
Я сделал курс по Luigi бесплатным для всех, велком изучать — Введение в Data Engineering: дата-пайплайны
Luigi это компактный инструмент для построения зависимых между собой задач на базе нескольких сущностей: Task, Target. Он идеально подойдёт там, где Airflow кажется избыточным инструментом. В далёком 2017 году я писал небольшой обзорный пост на Luigi у себя в блоге: Строим Data Pipeline на Python и Luigi. С тех пор мало что изменилось в концепции инструмента, он по прежнему компактный и простой, именно в этом вся его прелесть.
Startdatajourney
Введение в Data Engineering: дата-пайплайны
Построение масштабируемых дата-пайплайнов на Python и Luigi
Курс Анализ медицинских изображений в Python теперь бесплатный для всех.
На курсе вы изучите анализ медицинских изображений с помощью Python. Вы будете изучать КТ и рентген снимки, сегментировать области изображения и проводить анализ метаданных. Даже если вы никогда раньше не работали с медицинскими изображениями, то по завершению курса вы будете обладать всеми необходимы навыками.
Если хотите меня поддержать, то это можно сделать на Patreon и Boosty просто подпишитесь на месяц =)
На курсе вы изучите анализ медицинских изображений с помощью Python. Вы будете изучать КТ и рентген снимки, сегментировать области изображения и проводить анализ метаданных. Даже если вы никогда раньше не работали с медицинскими изображениями, то по завершению курса вы будете обладать всеми необходимы навыками.
Если хотите меня поддержать, то это можно сделать на Patreon и Boosty просто подпишитесь на месяц =)
Startdatajourney
Анализ медицинских изображений в Python
Практический курс по исследованию медицинских изображений в Python
Forwarded from DataEng
Курс про Apache Airflow бесплатно
Решил выложить свой курс про Apache Airflow абсолютно бесплатно для всех: Apache Airflow 2.2: практический курс
За то время что существует курс, Apache Airflow успел обрасти множеством новых фич, которые только предстоит покрыть в будущем, возможно в виде отдельных роликов на Ютуб или в виде статей у себя в блоге.
В любом случае курс не потерял своей актуальности и может послужить неплохим введением для новичков и более опытных пользователей. Например, в курсе я подробно разбираю как развернуть у себя на сервере production-ready Airflow, а также настроить автодеплой дагов через GitHub Actions.
Велком!
Решил выложить свой курс про Apache Airflow абсолютно бесплатно для всех: Apache Airflow 2.2: практический курс
За то время что существует курс, Apache Airflow успел обрасти множеством новых фич, которые только предстоит покрыть в будущем, возможно в виде отдельных роликов на Ютуб или в виде статей у себя в блоге.
В любом случае курс не потерял своей актуальности и может послужить неплохим введением для новичков и более опытных пользователей. Например, в курсе я подробно разбираю как развернуть у себя на сервере production-ready Airflow, а также настроить автодеплой дагов через GitHub Actions.
Велком!
Startdatajourney
Apache Airflow 2.2: практический курс
Практический курс по основам Apache Airflow версии 2.2 и выше
Forwarded from Артета позвонит
Если вы любите футбол и аналитику так же как я, то можно поучаствовать в Хакатоне по анализу футбольных данных
Даты хакатона: 11.03.2024 - 23.04.2024
Задача весьма интересная:
Нужно выбрать команду Английской Премьер Лиги для анализа.
Вам нужно проанализировать последние выступления выбранной команды, тактику и статистику игроков, чтобы выявить значительные слабые места в команде.
Выберите 2 позиции в соответствии с вашим анализом. Ваша задача создать два списки игроков (максимум 5 игроков, включая ГЛАВНУЮ трансферную цель) для выбранных позиций и обосновать принятые решения по набору игроков, данными.
Все участники Хакатона должны учитывать планируемый бюджет, который можно найти на странице Transfermarkt для каждого игрока. Бюджетный план: максимальная сумма 60 млн евро для общей оценки игрока на Transfermarkt на две ГЛАВНЫE цели.
Описание задачи
Мне кажется очень крутая скаутская задача и возможность поработать с реальными футбольными данными. Ограничения в 60 миллионов я думаю не позволят вам выбрать топ клубы АПЛ.
Думаю попробовать поучаствовать
Даты хакатона: 11.03.2024 - 23.04.2024
Задача весьма интересная:
Нужно выбрать команду Английской Премьер Лиги для анализа.
Вам нужно проанализировать последние выступления выбранной команды, тактику и статистику игроков, чтобы выявить значительные слабые места в команде.
Выберите 2 позиции в соответствии с вашим анализом. Ваша задача создать два списки игроков (максимум 5 игроков, включая ГЛАВНУЮ трансферную цель) для выбранных позиций и обосновать принятые решения по набору игроков, данными.
Все участники Хакатона должны учитывать планируемый бюджет, который можно найти на странице Transfermarkt для каждого игрока. Бюджетный план: максимальная сумма 60 млн евро для общей оценки игрока на Transfermarkt на две ГЛАВНЫE цели.
Описание задачи
Мне кажется очень крутая скаутская задача и возможность поработать с реальными футбольными данными. Ограничения в 60 миллионов я думаю не позволят вам выбрать топ клубы АПЛ.
Думаю попробовать поучаствовать
Football Analytics Hackathon 2024
Football Analytics Hackathon is a competition where participants use data analysis to solve challenges related to football.
250 бесплатных курсов по ИИ
Наткнулся на интересный пост со списком 250 бесплатных курсов по ИИ
До 5 апреля они будут открыты и доступны на семи языках.
Ссылка
Наткнулся на интересный пост со списком 250 бесплатных курсов по ИИ
До 5 апреля они будут открыты и доступны на семи языках.
Ссылка
Linkedin
Build Critical AI Skills with These 250 AI Courses | LinkedIn
LinkedIn has 250 courses focused on AI that can help address the needs of everyone from AI newbies to power users.
Погружение в LLM часть первая
Я тут начал погружаться в LLM чуть глубже и лично для меня гораздо проще начинать погружение через практику.
Таким образом можно понять все ключевые концепции и наметить себе список пейперов для дальнейшего ознакомления.
Начал я с заметки StackLLaMA: A hands-on guide to train LLaMA with RLHF
Тут вы сразу сможете ознакомиться с концепциями Reinforcement Learning from Human Feedback, эффективной тренировкой с помощью LoRA, PPO.
Так же вы познакомитесь с зоопарком библиотек huggingface: accelerate, bitsandbytes, peft и trl.
В заметке используется StackExchange датасет, но для разнообразия могу посоветовать вам использовать датасет Anthropic/hh-rlhf
Во второй части пройдемся по ключевым пейперам
Я тут начал погружаться в LLM чуть глубже и лично для меня гораздо проще начинать погружение через практику.
Таким образом можно понять все ключевые концепции и наметить себе список пейперов для дальнейшего ознакомления.
Начал я с заметки StackLLaMA: A hands-on guide to train LLaMA with RLHF
Тут вы сразу сможете ознакомиться с концепциями Reinforcement Learning from Human Feedback, эффективной тренировкой с помощью LoRA, PPO.
Так же вы познакомитесь с зоопарком библиотек huggingface: accelerate, bitsandbytes, peft и trl.
В заметке используется StackExchange датасет, но для разнообразия могу посоветовать вам использовать датасет Anthropic/hh-rlhf
Во второй части пройдемся по ключевым пейперам
GitHub
blog/stackllama.md at main · huggingface/blog
Public repo for HF blog posts. Contribute to huggingface/blog development by creating an account on GitHub.
Погружение в LLM часть вторая
В первой части мы разобрали практическую часть погружения в LLM.
В этой части мы поговорим про ключевые пейперы, которые помогут в понимании LLM и прохождение собеседований =) Но об этом позже.
Все начинается с первой гпт
Затем рекомендую прочитать работу про InstructGPT. Там раскрыта тема обучения с фидбеком от человека.
Дальше есть пара интересных пейперов:
- SELF-INSTRUCT
- Information Retrieval with Contrastive Learning
Затем рекомендую ознакомиться с двумя воистину знаковых пейпера: LORA и QLORA, которые решают следующие проблемы:
- скорость обучения
- вычислительные ресурсы
- эффективность памяти
Еще два не менее важных пейпера PPO и DPO. Понимание этих работ поможет в ревард моделинге.
Ну и на последок:
- Switch Transformers - как база Mixtures of experts
- Mixtral of Experts - как Open Source SOTA
- Llama 2
Всем приятного чтения
В первой части мы разобрали практическую часть погружения в LLM.
В этой части мы поговорим про ключевые пейперы, которые помогут в понимании LLM и прохождение собеседований =) Но об этом позже.
Все начинается с первой гпт
Затем рекомендую прочитать работу про InstructGPT. Там раскрыта тема обучения с фидбеком от человека.
Дальше есть пара интересных пейперов:
- SELF-INSTRUCT
- Information Retrieval with Contrastive Learning
Затем рекомендую ознакомиться с двумя воистину знаковых пейпера: LORA и QLORA, которые решают следующие проблемы:
- скорость обучения
- вычислительные ресурсы
- эффективность памяти
Еще два не менее важных пейпера PPO и DPO. Понимание этих работ поможет в ревард моделинге.
Ну и на последок:
- Switch Transformers - как база Mixtures of experts
- Mixtral of Experts - как Open Source SOTA
- Llama 2
Всем приятного чтения
{kind=link}